 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Execution Safety Gate & Task Safety Contracts for LLM-Controlled Robot Systems
Apr 07, 2026Large Language Models (LLMs) are increasingly used to convert task commands into robot-executable code, however this pipeline lacks validation gates to detect unsafe and defective commands before they are translated into robot code. Furthermore, even commands that appear safe at the outset can produce unsafe state transitions during execution in the absence of continuous constraint monitoring. In this research, we introduce SafeGate, a neurosymbolic safety architecture that prevents unsafe natural language task commands from reaching robot execution. Drawing from ISO 13482 safety standard, SafeGate extracts structured safety-relevant properties from natural language commands and applies a deterministic decision gate to authorize or reject execution. In addition, we introduce Task Safety Contracts, which decomposes commands that pass through the gate into invariants, guards, and abort conditions to prevent unsafe state transitions during execution. We further incorporate Z3 SMT solving to enforce constraint checking derived from the Task Safety Contracts. We evaluate SafeGate against existing LLM-based robot safety frameworks and baseline LLMs across 230 benchmark tasks, 30 AI2-THOR simulation scenarios, and real-world robot experiments. Results show that SafeGate significantly reduces the acceptance of defective commands while maintaining a high acceptance of benign tasks, demonstrating the importance of pre-execution safety gates for LLM-controlled robot systems
Tracing the Invisible: Understanding Students' Judgment in AI-Supported Design Work
May 13, 2025
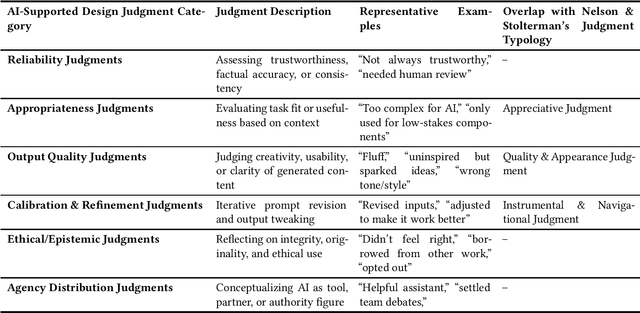
As generative AI tools become integrated into design workflows, students increasingly engage with these tools not just as aids, but as collaborators. This study analyzes reflections from 33 student teams in an HCI design course to examine the kinds of judgments students make when using AI tools. We found both established forms of design judgment (e.g., instrumental, appreciative, quality) and emergent types: agency-distribution judgment and reliability judgment. These new forms capture how students negotiate creative responsibility with AI and assess the trustworthiness of its outputs. Our findings suggest that generative AI introduces new layers of complexity into design reasoning, prompting students to reflect not only on what AI produces, but also on how and when to rely on it. By foregrounding these judgments, we offer a conceptual lens for understanding how students engage in co-creative sensemaking with AI in design contexts.
Multi-Agent LLM Actor-Critic Framework for Social Robot Navigation
Mar 12, 2025Recent advances in robotics and large language models (LLMs) have sparked growing interest in human-robot collaboration and embodied intelligence. To enable the broader deployment of robots in human-populated environments, socially-aware robot navigation (SAN) has become a key research area. While deep reinforcement learning approaches that integrate human-robot interaction (HRI) with path planning have demonstrated strong benchmark performance, they often struggle to adapt to new scenarios and environments. LLMs offer a promising avenue for zero-shot navigation through commonsense inference. However, most existing LLM-based frameworks rely on centralized decision-making, lack robust verification mechanisms, and face inconsistencies in translating macro-actions into precise low-level control signals. To address these challenges, we propose SAMALM, a decentralized multi-agent LLM actor-critic framework for multi-robot social navigation. In this framework, a set of parallel LLM actors, each reflecting distinct robot personalities or configurations, directly generate control signals. These actions undergo a two-tier verification process via a global critic that evaluates group-level behaviors and individual critics that assess each robot's context. An entropy-based score fusion mechanism further enhances self-verification and re-query, improving both robustness and coordination. Experimental results confirm that SAMALM effectively balances local autonomy with global oversight, yielding socially compliant behaviors and strong adaptability across diverse multi-robot scenarios. More details and videos about this work are available at: https://sites.google.com/view/SAMALM.
SafePlan: Leveraging Formal Logic and Chain-of-Thought Reasoning for Enhanced Safety in LLM-based Robotic Task Planning
Mar 10, 2025



Robotics researchers increasingly leverage large language models (LLM) in robotics systems, using them as interfaces to receive task commands, generate task plans, form team coalitions, and allocate tasks among multi-robot and human agents. However, despite their benefits, the growing adoption of LLM in robotics has raised several safety concerns, particularly regarding executing malicious or unsafe natural language prompts. In addition, ensuring that task plans, team formation, and task allocation outputs from LLMs are adequately examined, refined, or rejected is crucial for maintaining system integrity. In this paper, we introduce SafePlan, a multi-component framework that combines formal logic and chain-of-thought reasoners for enhancing the safety of LLM-based robotics systems. Using the components of SafePlan, including Prompt Sanity COT Reasoner and Invariant, Precondition, and Postcondition COT reasoners, we examined the safety of natural language task prompts, task plans, and task allocation outputs generated by LLM-based robotic systems as means of investigating and enhancing system safety profile. Our results show that SafePlan outperforms baseline models by leading to 90.5% reduction in harmful task prompt acceptance while still maintaining reasonable acceptance of safe tasks.
Value Imprint: A Technique for Auditing the Human Values Embedded in RLHF Datasets
Nov 18, 2024



LLMs are increasingly fine-tuned using RLHF datasets to align them with human preferences and values. However, very limited research has investigated which specific human values are operationalized through these datasets. In this paper, we introduce Value Imprint, a framework for auditing and classifying the human values embedded within RLHF datasets. To investigate the viability of this framework, we conducted three case study experiments by auditing the Anthropic/hh-rlhf, OpenAI WebGPT Comparisons, and Alpaca GPT-4-LLM datasets to examine the human values embedded within them. Our analysis involved a two-phase process. During the first phase, we developed a taxonomy of human values through an integrated review of prior works from philosophy, axiology, and ethics. Then, we applied this taxonomy to annotate 6,501 RLHF preferences. During the second phase, we employed the labels generated from the annotation as ground truth data for training a transformer-based machine learning model to audit and classify the three RLHF datasets. Through this approach, we discovered that information-utility values, including Wisdom/Knowledge and Information Seeking, were the most dominant human values within all three RLHF datasets. In contrast, prosocial and democratic values, including Well-being, Justice, and Human/Animal Rights, were the least represented human values. These findings have significant implications for developing language models that align with societal values and norms. We contribute our datasets to support further research in this area.
Investigating the Impact of Trust in Multi-Human Multi-Robot Task Allocation
Sep 24, 2024



Trust is essential in human-robot collaboration. Even more so in multi-human multi-robot teams where trust is vital to ensure teaming cohesion in complex operational environments. Yet, at the moment, trust is rarely considered a factor during task allocation and reallocation in algorithms used in multi-human, multi-robot collaboration contexts. Prior work on trust in single-human-robot interaction has identified that including trust as a parameter in human-robot interaction significantly improves both performance outcomes and human experience with robotic systems. However, very little research has explored the impact of trust in multi-human multi-robot collaboration, specifically in the context of task allocation. In this paper, we introduce a new trust model, the Expectation Comparison Trust (ECT) model, and employ it with three trust models from prior work and a baseline no-trust model to investigate the impact of trust on task allocation outcomes in multi-human multi-robot collaboration. Our experiment involved different team configurations, including 2 humans, 2 robots, 5 humans, 5 robots, and 10 humans, 10 robots. Results showed that using trust-based models generally led to better task allocation outcomes in larger teams (10 humans and 10 robots) than in smaller teams. We discuss the implications of our findings and provide recommendations for future work on integrating trust as a variable for task allocation in multi-human, multi-robot collaboration.
Adaptive Task Allocation in Multi-Human Multi-Robot Teams under Team Heterogeneity and Dynamic Information Uncertainty
Sep 20, 2024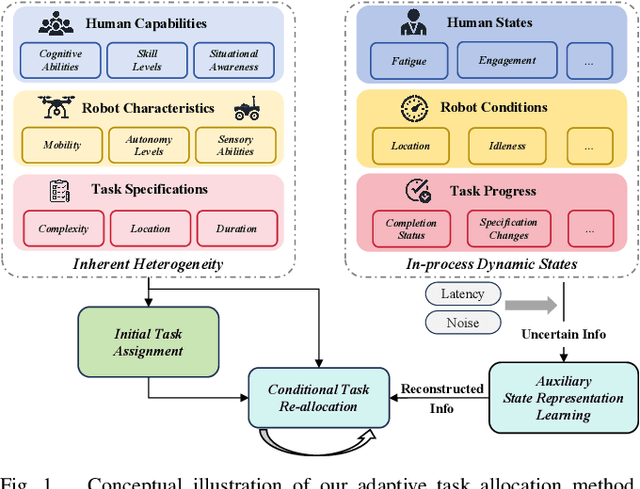
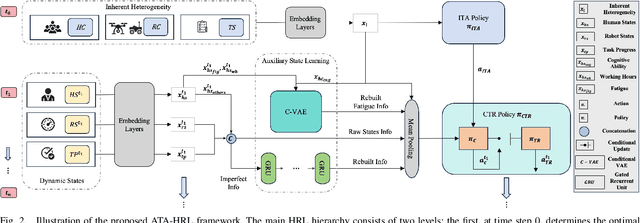

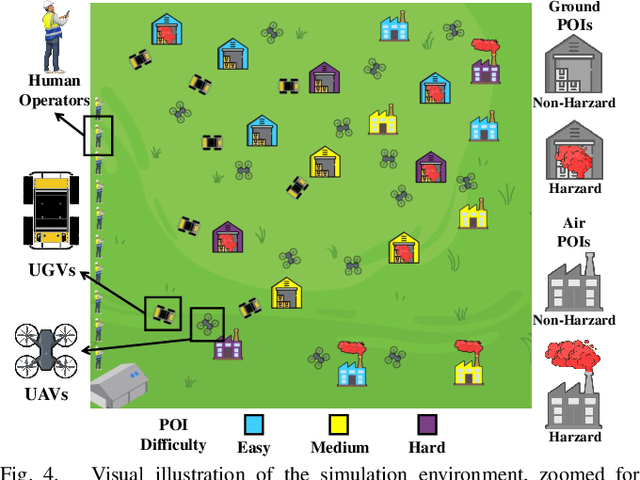
Task allocation in multi-human multi-robot (MH-MR) teams presents significant challenges due to the inherent heterogeneity of team members, the dynamics of task execution, and the information uncertainty of operational states. Existing approaches often fail to address these challenges simultaneously, resulting in suboptimal performance. To tackle this, we propose ATA-HRL, an adaptive task allocation framework using hierarchical reinforcement learning (HRL), which incorporates initial task allocation (ITA) that leverages team heterogeneity and conditional task reallocation in response to dynamic operational states. Additionally, we introduce an auxiliary state representation learning task to manage information uncertainty and enhance task execution. Through an extensive case study in large-scale environmental monitoring tasks, we demonstrate the benefits of our approach.
PrefCLM: Enhancing Preference-based Reinforcement Learning with Crowdsourced Large Language Models
Jul 11, 2024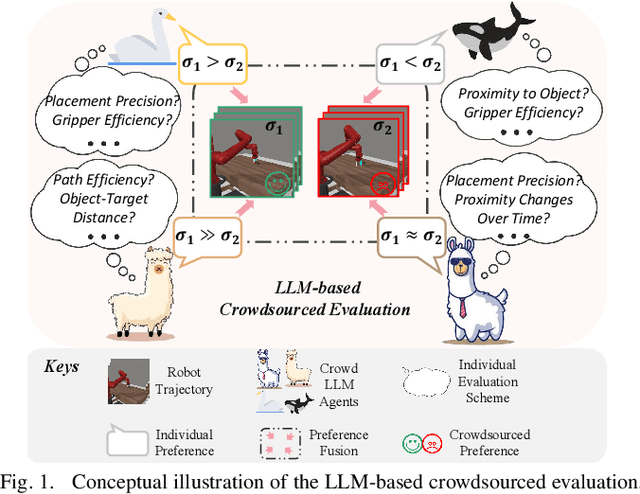
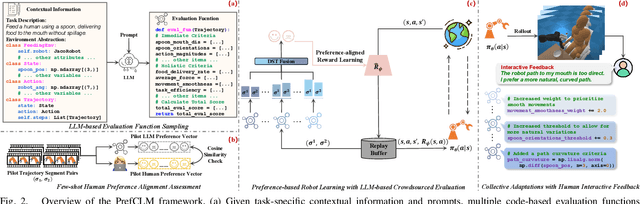
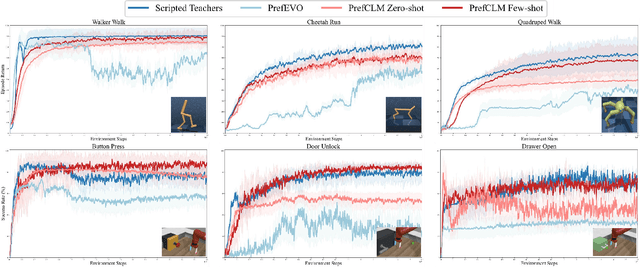

Preference-based reinforcement learning (PbRL) is emerging as a promising approach to teaching robots through human comparative feedback, sidestepping the need for complex reward engineering. However, the substantial volume of feedback required in existing PbRL methods often lead to reliance on synthetic feedback generated by scripted teachers. This approach necessitates intricate reward engineering again and struggles to adapt to the nuanced preferences particular to human-robot interaction (HRI) scenarios, where users may have unique expectations toward the same task. To address these challenges, we introduce PrefCLM, a novel framework that utilizes crowdsourced large language models (LLMs) as simulated teachers in PbRL. We utilize Dempster-Shafer Theory to fuse individual preferences from multiple LLM agents at the score level, efficiently leveraging their diversity and collective intelligence. We also introduce a human-in-the-loop pipeline that facilitates collective refinements based on user interactive feedback. Experimental results across various general RL tasks show that PrefCLM achieves competitive performance compared to traditional scripted teachers and excels in facilitating more more natural and efficient behaviors. A real-world user study (N=10) further demonstrates its capability to tailor robot behaviors to individual user preferences, significantly enhancing user satisfaction in HRI scenarios.
Robot Patrol: Using Crowdsourcing and Robotic Systems to Provide Indoor Navigation Guidance to The Visually Impaired
Jun 05, 2023Indoor navigation is a challenging activity for persons with disabilities, particularly, for those with low vision and visual impairment. Researchers have explored numerous solutions to resolve these challenges; however, several issues remain unsolved, particularly around providing dynamic and contextual information about potential obstacles in indoor environments. In this paper, we developed Robot Patrol, an integrated system that employs a combination of crowdsourcing, computer vision, and robotic frameworks to provide contextual information to the visually impaired to empower them to navigate indoor spaces safely. In particular, the system is designed to provide information to the visually impaired about 1) potential obstacles on the route to their indoor destination, 2) information about indoor events on their route which they may wish to avoid or attend, and 3) any other contextual information that might support them to navigate to their indoor destinations safely and effectively. Findings from the Wizard of Oz experiment of our demo system provide insights into the benefits and limitations of the system. We provide a concise discussion on the implications of our findings.