 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFramework, Standards, Applications and Best practices of Responsible AI : A Comprehensive Survey
Apr 18, 2025



Responsible Artificial Intelligence (RAI) is a combination of ethics associated with the usage of artificial intelligence aligned with the common and standard frameworks. This survey paper extensively discusses the global and national standards, applications of RAI, current technology and ongoing projects using RAI, and possible challenges in implementing and designing RAI in the industries and projects based on AI. Currently, ethical standards and implementation of RAI are decoupled which caters each industry to follow their own standards to use AI ethically. Many global firms and government organizations are taking necessary initiatives to design a common and standard framework. Social pressure and unethical way of using AI forces the RAI design rather than implementation.
Multi-Agent LLM Actor-Critic Framework for Social Robot Navigation
Mar 12, 2025Recent advances in robotics and large language models (LLMs) have sparked growing interest in human-robot collaboration and embodied intelligence. To enable the broader deployment of robots in human-populated environments, socially-aware robot navigation (SAN) has become a key research area. While deep reinforcement learning approaches that integrate human-robot interaction (HRI) with path planning have demonstrated strong benchmark performance, they often struggle to adapt to new scenarios and environments. LLMs offer a promising avenue for zero-shot navigation through commonsense inference. However, most existing LLM-based frameworks rely on centralized decision-making, lack robust verification mechanisms, and face inconsistencies in translating macro-actions into precise low-level control signals. To address these challenges, we propose SAMALM, a decentralized multi-agent LLM actor-critic framework for multi-robot social navigation. In this framework, a set of parallel LLM actors, each reflecting distinct robot personalities or configurations, directly generate control signals. These actions undergo a two-tier verification process via a global critic that evaluates group-level behaviors and individual critics that assess each robot's context. An entropy-based score fusion mechanism further enhances self-verification and re-query, improving both robustness and coordination. Experimental results confirm that SAMALM effectively balances local autonomy with global oversight, yielding socially compliant behaviors and strong adaptability across diverse multi-robot scenarios. More details and videos about this work are available at: https://sites.google.com/view/SAMALM.
SafePlan: Leveraging Formal Logic and Chain-of-Thought Reasoning for Enhanced Safety in LLM-based Robotic Task Planning
Mar 10, 2025



Robotics researchers increasingly leverage large language models (LLM) in robotics systems, using them as interfaces to receive task commands, generate task plans, form team coalitions, and allocate tasks among multi-robot and human agents. However, despite their benefits, the growing adoption of LLM in robotics has raised several safety concerns, particularly regarding executing malicious or unsafe natural language prompts. In addition, ensuring that task plans, team formation, and task allocation outputs from LLMs are adequately examined, refined, or rejected is crucial for maintaining system integrity. In this paper, we introduce SafePlan, a multi-component framework that combines formal logic and chain-of-thought reasoners for enhancing the safety of LLM-based robotics systems. Using the components of SafePlan, including Prompt Sanity COT Reasoner and Invariant, Precondition, and Postcondition COT reasoners, we examined the safety of natural language task prompts, task plans, and task allocation outputs generated by LLM-based robotic systems as means of investigating and enhancing system safety profile. Our results show that SafePlan outperforms baseline models by leading to 90.5% reduction in harmful task prompt acceptance while still maintaining reasonable acceptance of safe tasks.
Hyper-SAMARL: Hypergraph-based Coordinated Task Allocation and Socially-aware Navigation for Multi-Robot Systems
Sep 17, 2024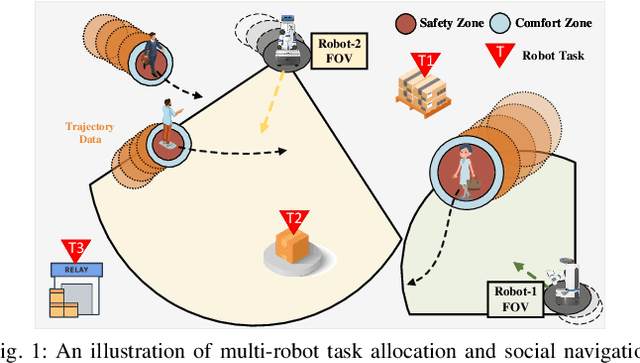
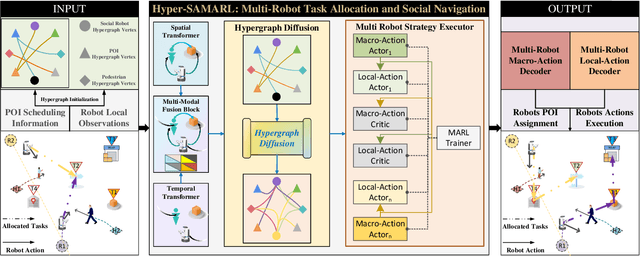
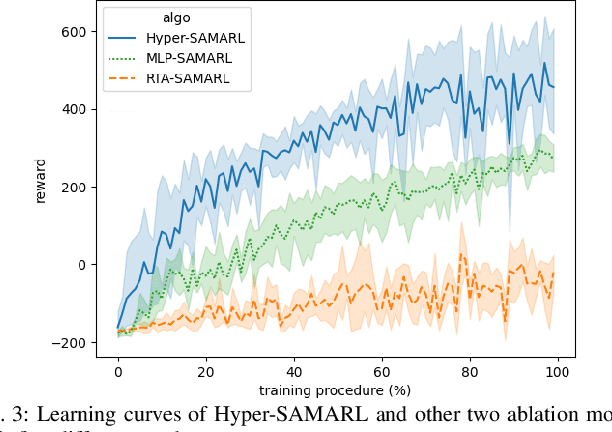
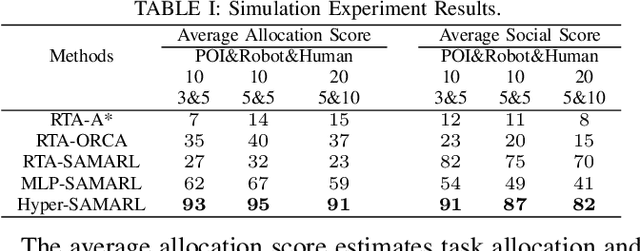
A team of multiple robots seamlessly and safely working in human-filled public environments requires adaptive task allocation and socially-aware navigation that account for dynamic human behavior. Current approaches struggle with highly dynamic pedestrian movement and the need for flexible task allocation. We propose Hyper-SAMARL, a hypergraph-based system for multi-robot task allocation and socially-aware navigation, leveraging multi-agent reinforcement learning (MARL). Hyper-SAMARL models the environmental dynamics between robots, humans, and points of interest (POIs) using a hypergraph, enabling adaptive task assignment and socially-compliant navigation through a hypergraph diffusion mechanism. Our framework, trained with MARL, effectively captures interactions between robots and humans, adapting tasks based on real-time changes in human activity. Experimental results demonstrate that Hyper-SAMARL outperforms baseline models in terms of social navigation, task completion efficiency, and adaptability in various simulated scenarios.
SRLM: Human-in-Loop Interactive Social Robot Navigation with Large Language Model and Deep Reinforcement Learning
Mar 22, 2024



An interactive social robotic assistant must provide services in complex and crowded spaces while adapting its behavior based on real-time human language commands or feedback. In this paper, we propose a novel hybrid approach called Social Robot Planner (SRLM), which integrates Large Language Models (LLM) and Deep Reinforcement Learning (DRL) to navigate through human-filled public spaces and provide multiple social services. SRLM infers global planning from human-in-loop commands in real-time, and encodes social information into a LLM-based large navigation model (LNM) for low-level motion execution. Moreover, a DRL-based planner is designed to maintain benchmarking performance, which is blended with LNM by a large feedback model (LFM) to address the instability of current text and LLM-driven LNM. Finally, SRLM demonstrates outstanding performance in extensive experiments. More details about this work are available at: https://sites.google.com/view/navi-srlm
PatchAD: Patch-based MLP-Mixer for Time Series Anomaly Detection
Jan 24, 2024

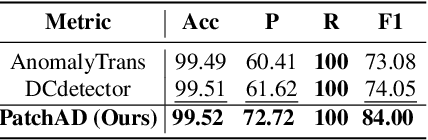
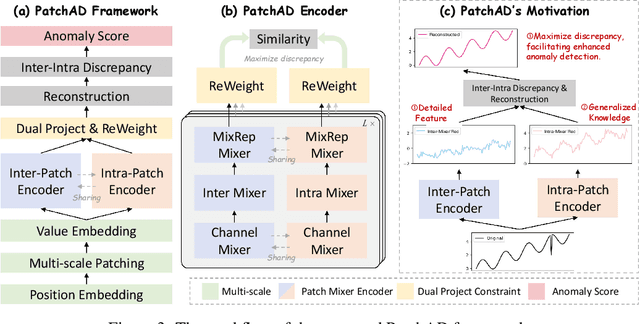
Anomaly detection stands as a crucial aspect of time series analysis, aiming to identify abnormal events in time series samples. The central challenge of this task lies in effectively learning the representations of normal and abnormal patterns in a label-lacking scenario. Previous research mostly relied on reconstruction-based approaches, restricting the representational abilities of the models. In addition, most of the current deep learning-based methods are not lightweight enough, which prompts us to design a more efficient framework for anomaly detection. In this study, we introduce PatchAD, a novel multi-scale patch-based MLP-Mixer architecture that leverages contrastive learning for representational extraction and anomaly detection. Specifically, PatchAD is composed of four distinct MLP Mixers, exclusively utilizing the MLP architecture for high efficiency and lightweight architecture. Additionally, we also innovatively crafted a dual project constraint module to mitigate potential model degradation. Comprehensive experiments demonstrate that PatchAD achieves state-of-the-art results across multiple real-world multivariate time series datasets. Our code is publicly available https://github.com/EmorZz1G/PatchAD
Hyper-STTN: Social Group-aware Spatial-Temporal Transformer Network for Human Trajectory Prediction with Hypergraph Reasoning
Jan 12, 2024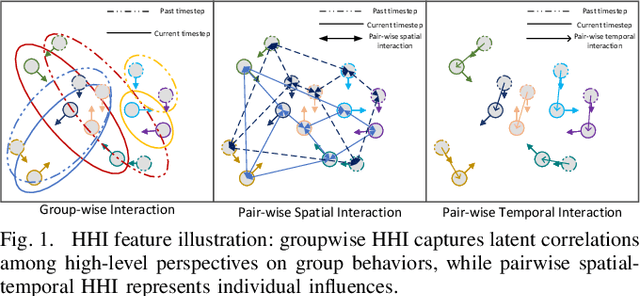
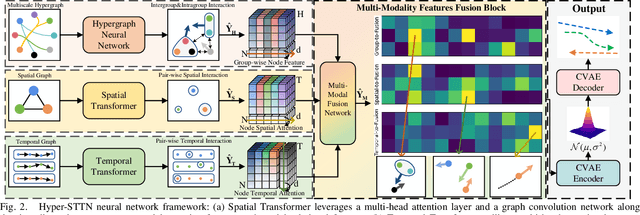
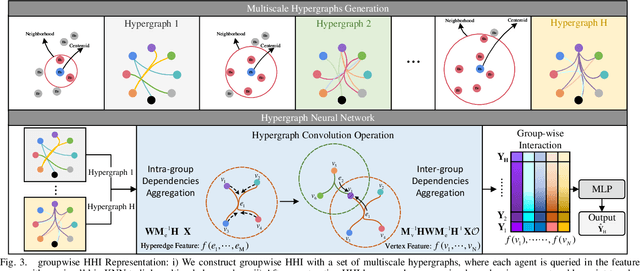
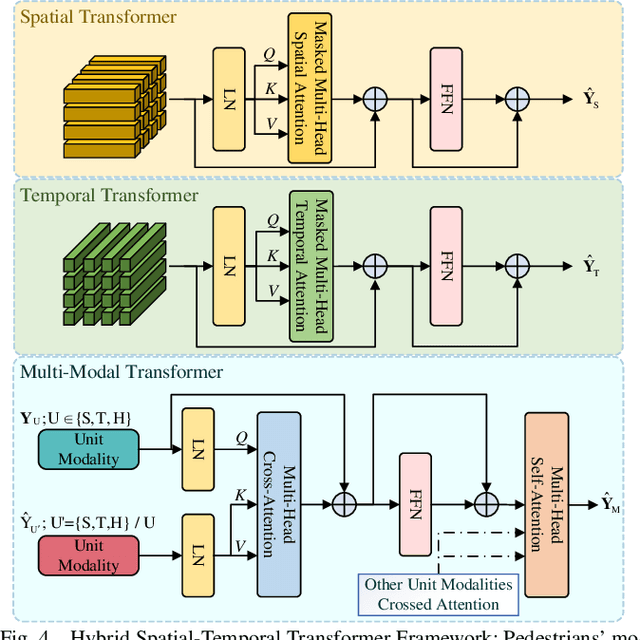
Predicting crowded intents and trajectories is crucial in varouls real-world applications, including service robots and autonomous vehicles. Understanding environmental dynamics is challenging, not only due to the complexities of modeling pair-wise spatial and temporal interactions but also the diverse influence of group-wise interactions. To decode the comprehensive pair-wise and group-wise interactions in crowded scenarios, we introduce Hyper-STTN, a Hypergraph-based Spatial-Temporal Transformer Network for crowd trajectory prediction. In Hyper-STTN, crowded group-wise correlations are constructed using a set of multi-scale hypergraphs with varying group sizes, captured through random-walk robability-based hypergraph spectral convolution. Additionally, a spatial-temporal transformer is adapted to capture pedestrians' pair-wise latent interactions in spatial-temporal dimensions. These heterogeneous group-wise and pair-wise are then fused and aligned though a multimodal transformer network. Hyper-STTN outperformes other state-of-the-art baselines and ablation models on 5 real-world pedestrian motion datasets.
Multi-Robot Cooperative Socially-Aware Navigation Using Multi-Agent Reinforcement Learning
Sep 26, 2023



In public spaces shared with humans, ensuring multi-robot systems navigate without collisions while respecting social norms is challenging, particularly with limited communication. Although current robot social navigation techniques leverage advances in reinforcement learning and deep learning, they frequently overlook robot dynamics in simulations, leading to a simulation-to-reality gap. In this paper, we bridge this gap by presenting a new multi-robot social navigation environment crafted using Dec-POSMDP and multi-agent reinforcement learning. Furthermore, we introduce SAMARL: a novel benchmark for cooperative multi-robot social navigation. SAMARL employs a unique spatial-temporal transformer combined with multi-agent reinforcement learning. This approach effectively captures the complex interactions between robots and humans, thus promoting cooperative tendencies in multi-robot systems. Our extensive experiments reveal that SAMARL outperforms existing baseline and ablation models in our designed environment. Demo videos for this work can be found at: https://sites.google.com/view/samarl
Generative Pre-trained Transformer: A Comprehensive Review on Enabling Technologies, Potential Applications, Emerging Challenges, and Future Directions
May 21, 2023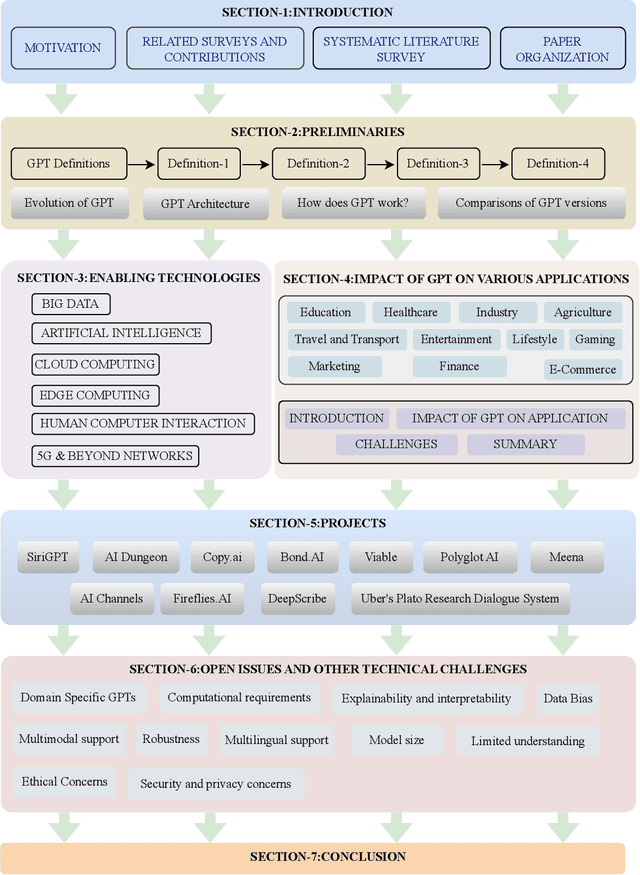
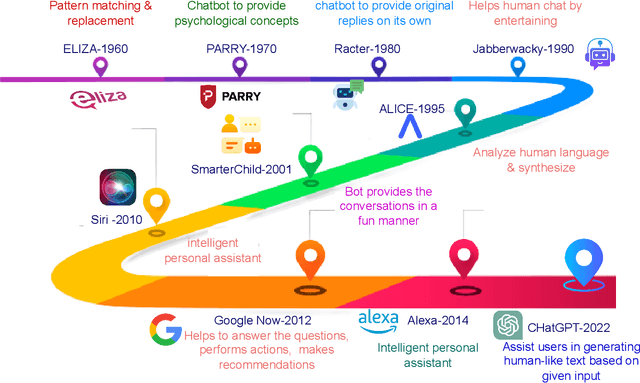
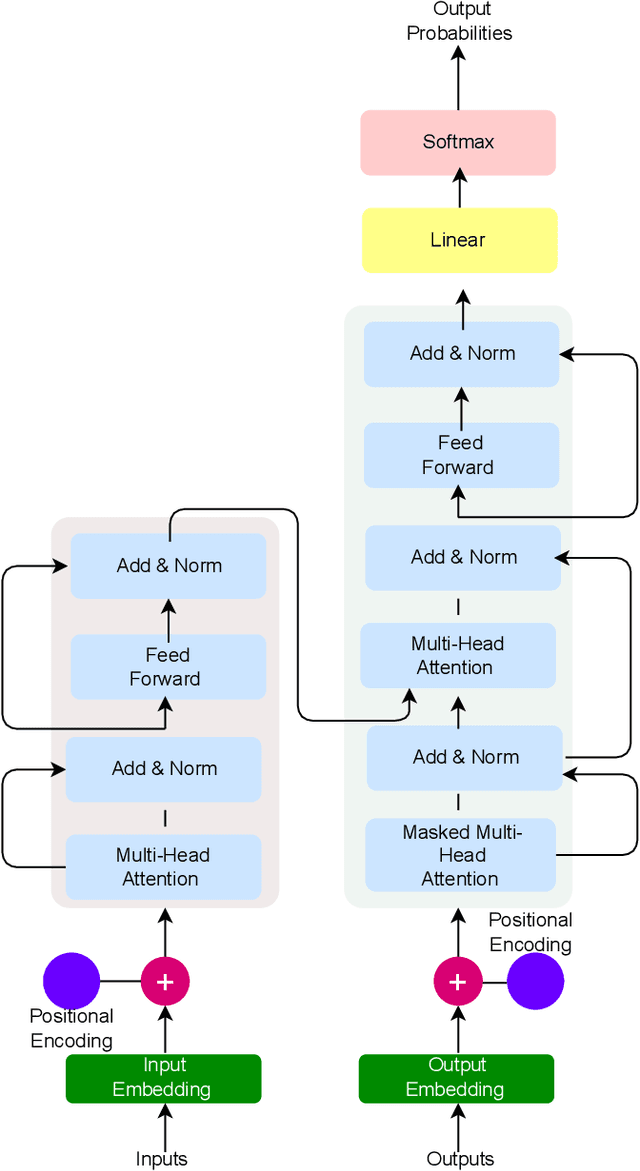
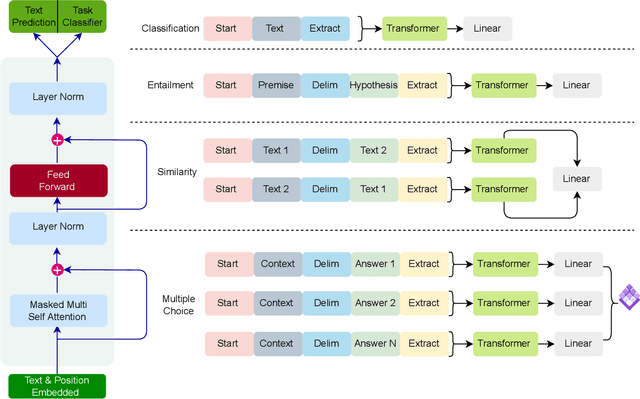
The Generative Pre-trained Transformer (GPT) represents a notable breakthrough in the domain of natural language processing, which is propelling us toward the development of machines that can understand and communicate using language in a manner that closely resembles that of humans. GPT is based on the transformer architecture, a deep neural network designed for natural language processing tasks. Due to their impressive performance on natural language processing tasks and ability to effectively converse, GPT have gained significant popularity among researchers and industrial communities, making them one of the most widely used and effective models in natural language processing and related fields, which motivated to conduct this review. This review provides a detailed overview of the GPT, including its architecture, working process, training procedures, enabling technologies, and its impact on various applications. In this review, we also explored the potential challenges and limitations of a GPT. Furthermore, we discuss potential solutions and future directions. Overall, this paper aims to provide a comprehensive understanding of GPT, enabling technologies, their impact on various applications, emerging challenges, and potential solutions.
NaviSTAR: Socially Aware Robot Navigation with Hybrid Spatio-Temporal Graph Transformer and Preference Learning
Apr 12, 2023



Developing robotic technologies for use in human society requires ensuring the safety of robots' navigation behaviors while adhering to pedestrians' expectations and social norms. However, maintaining real-time communication between robots and pedestrians to avoid collisions can be challenging. To address these challenges, we propose a novel socially-aware navigation benchmark called NaviSTAR, which utilizes a hybrid Spatio-Temporal grAph tRansformer (STAR) to understand interactions in human-rich environments fusing potential crowd multi-modal information. We leverage off-policy reinforcement learning algorithm with preference learning to train a policy and a reward function network with supervisor guidance. Additionally, we design a social score function to evaluate the overall performance of social navigation. To compare, we train and test our algorithm and other state-of-the-art methods in both simulator and real-world scenarios independently. Our results show that NaviSTAR outperforms previous methods with outstanding performance\footnote{The source code and experiment videos of this work are available at: https://sites.google.com/view/san-navistar