 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHusformer: A Multi-Modal Transformer for Multi-Modal Human State Recognition
Paper and Code
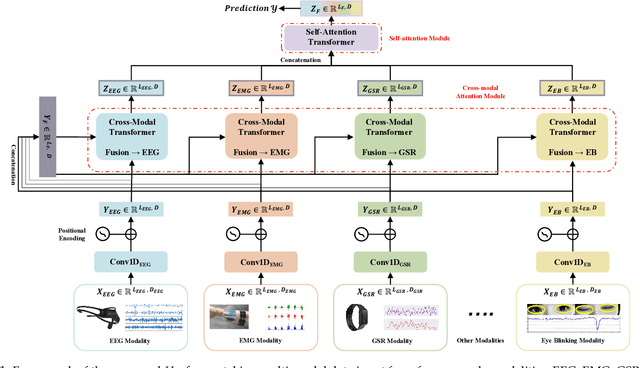
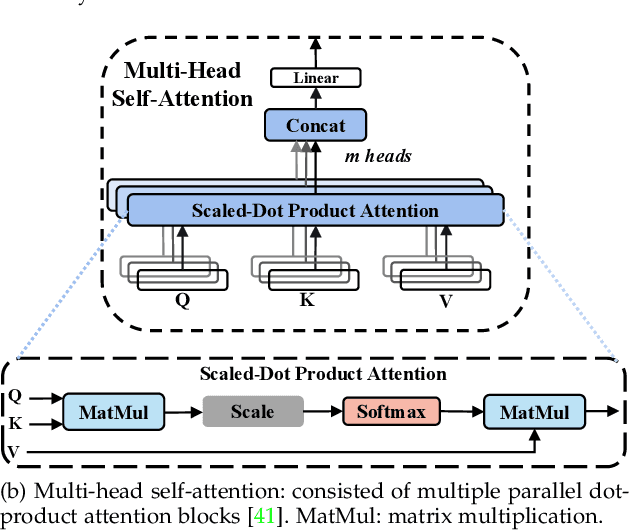
Human state recognition is a critical topic with pervasive and important applications in human-machine systems.Multi-modal fusion, the combination of metrics from multiple data sources, has been shown as a sound method for improving the recognition performance. However, while promising results have been reported by recent multi-modal-based models, they generally fail to leverage the sophisticated fusion strategies that would model sufficient cross-modal interactions when producing the fusion representation; instead, current methods rely on lengthy and inconsistent data preprocessing and feature crafting. To address this limitation, we propose an end-to-end multi-modal transformer framework for multi-modal human state recognition called Husformer.Specifically, we propose to use cross-modal transformers, which inspire one modality to reinforce itself through directly attending to latent relevance revealed in other modalities, to fuse different modalities while ensuring sufficient awareness of the cross-modal interactions introduced. Subsequently, we utilize a self-attention transformer to further prioritize contextual information in the fusion representation. Using two such attention mechanisms enables effective and adaptive adjustments to noise and interruptions in multi-modal signals during the fusion process and in relation to high-level features. Extensive experiments on two human emotion corpora (DEAP and WESAD) and two cognitive workload datasets (MOCAS and CogLoad) demonstrate that in the recognition of human state, our Husformer outperforms both state-of-the-art multi-modal baselines and the use of a single modality by a large margin, especially when dealing with raw multi-modal signals. We also conducted an ablation study to show the benefits of each component in Husformer/