 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebate Only When Necessary: Adaptive Multiagent Collaboration for Efficient LLM Reasoning
Apr 07, 2025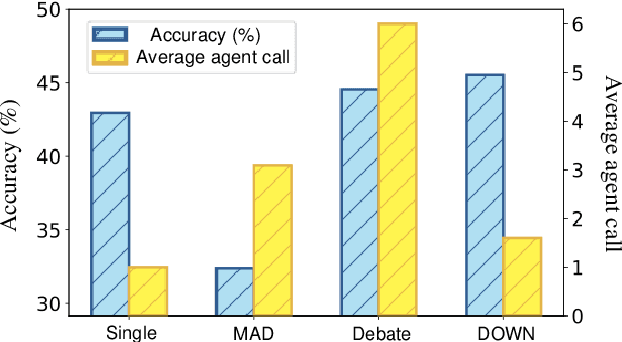
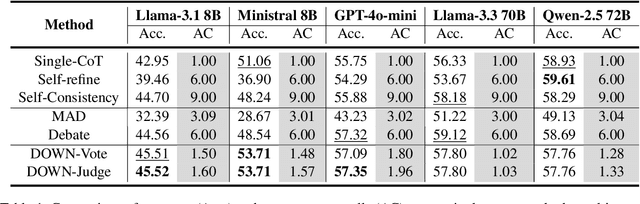
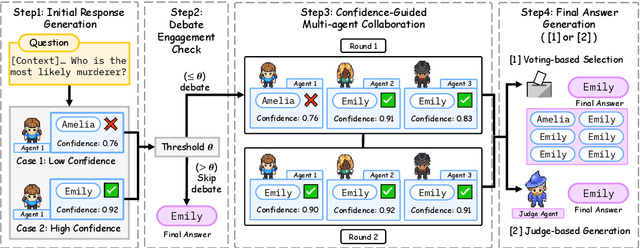
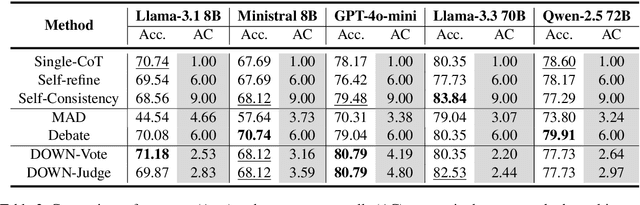
Multiagent collaboration has emerged as a promising framework for enhancing the reasoning capabilities of large language models (LLMs). While this approach improves reasoning capability, it incurs substantial computational overhead due to iterative agent interactions. Furthermore, engaging in debates for queries that do not necessitate collaboration amplifies the risk of error generation. To address these challenges, we propose Debate Only When Necessary (DOWN), an adaptive multiagent debate framework that selectively activates the debate process based on the confidence score of the agent's initial response. For queries where debate is triggered, agents refine their outputs using responses from participating agents and their confidence scores. Experimental results demonstrate that this mechanism significantly improves efficiency while maintaining or even surpassing the performance of existing multiagent debate systems. We also find that confidence-guided debate mitigates error propagation and enhances the selective incorporation of reliable responses. These results establish DOWN as an optimization strategy for efficient and effective multiagent reasoning, facilitating the practical deployment of LLM-based collaboration.
Toward Practical Automatic Speech Recognition and Post-Processing: a Call for Explainable Error Benchmark Guideline
Jan 26, 2024Automatic speech recognition (ASR) outcomes serve as input for downstream tasks, substantially impacting the satisfaction level of end-users. Hence, the diagnosis and enhancement of the vulnerabilities present in the ASR model bear significant importance. However, traditional evaluation methodologies of ASR systems generate a singular, composite quantitative metric, which fails to provide comprehensive insight into specific vulnerabilities. This lack of detail extends to the post-processing stage, resulting in further obfuscation of potential weaknesses. Despite an ASR model's ability to recognize utterances accurately, subpar readability can negatively affect user satisfaction, giving rise to a trade-off between recognition accuracy and user-friendliness. To effectively address this, it is imperative to consider both the speech-level, crucial for recognition accuracy, and the text-level, critical for user-friendliness. Consequently, we propose the development of an Error Explainable Benchmark (EEB) dataset. This dataset, while considering both speech- and text-level, enables a granular understanding of the model's shortcomings. Our proposition provides a structured pathway for a more `real-world-centric' evaluation, a marked shift away from abstracted, traditional methods, allowing for the detection and rectification of nuanced system weaknesses, ultimately aiming for an improved user experience.
Synthetic Alone: Exploring the Dark Side of Synthetic Data for Grammatical Error Correction
Jun 26, 2023
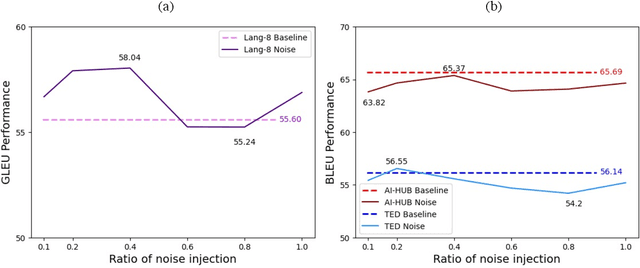


Data-centric AI approach aims to enhance the model performance without modifying the model and has been shown to impact model performance positively. While recent attention has been given to data-centric AI based on synthetic data, due to its potential for performance improvement, data-centric AI has long been exclusively validated using real-world data and publicly available benchmark datasets. In respect of this, data-centric AI still highly depends on real-world data, and the verification of models using synthetic data has not yet been thoroughly carried out. Given the challenges above, we ask the question: Does data quality control (noise injection and balanced data), a data-centric AI methodology acclaimed to have a positive impact, exhibit the same positive impact in models trained solely with synthetic data? To address this question, we conducted comparative analyses between models trained on synthetic and real-world data based on grammatical error correction (GEC) task. Our experimental results reveal that the data quality control method has a positive impact on models trained with real-world data, as previously reported in existing studies, while a negative impact is observed in models trained solely on synthetic data.
Towards Diverse and Effective Question-Answer Pair Generation from Children Storybooks
Jun 11, 2023Recent advances in QA pair generation (QAG) have raised interest in applying this technique to the educational field. However, the diversity of QA types remains a challenge despite its contributions to comprehensive learning and assessment of children. In this paper, we propose a QAG framework that enhances QA type diversity by producing different interrogative sentences and implicit/explicit answers. Our framework comprises a QFS-based answer generator, an iterative QA generator, and a relevancy-aware ranker. The two generators aim to expand the number of candidates while covering various types. The ranker trained on the in-context negative samples clarifies the top-N outputs based on the ranking score. Extensive evaluations and detailed analyses demonstrate that our approach outperforms previous state-of-the-art results by significant margins, achieving improved diversity and quality. Our task-oriented processes are consistent with real-world demand, which highlights our system's high applicability.
Self-Improving-Leaderboard: A Call for Real-World Centric Natural Language Processing Leaderboards
Mar 20, 2023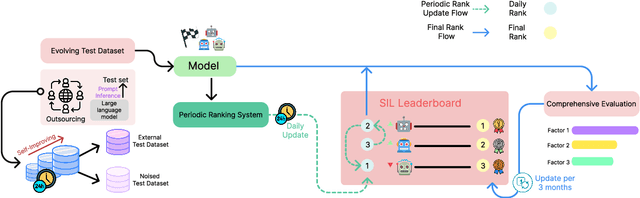
Leaderboard systems allow researchers to objectively evaluate Natural Language Processing (NLP) models and are typically used to identify models that exhibit superior performance on a given task in a predetermined setting. However, we argue that evaluation on a given test dataset is just one of many performance indications of the model. In this paper, we claim leaderboard competitions should also aim to identify models that exhibit the best performance in a real-world setting. We highlight three issues with current leaderboard systems: (1) the use of a single, static test set, (2) discrepancy between testing and real-world application (3) the tendency for leaderboard-centric competition to be biased towards the test set. As a solution, we propose a new paradigm of leaderboard systems that addresses these issues of current leaderboard system. Through this study, we hope to induce a paradigm shift towards more real -world-centric leaderboard competitions.
QUAK: A Synthetic Quality Estimation Dataset for Korean-English Neural Machine Translation
Sep 30, 2022
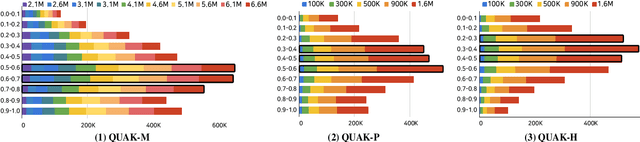
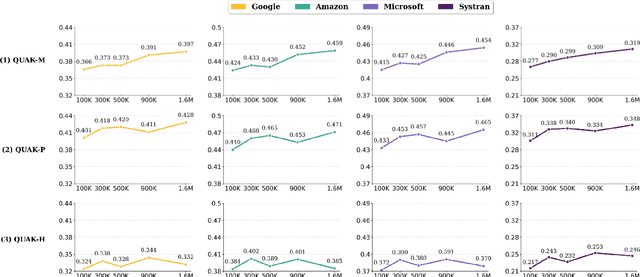
With the recent advance in neural machine translation demonstrating its importance, research on quality estimation (QE) has been steadily progressing. QE aims to automatically predict the quality of machine translation (MT) output without reference sentences. Despite its high utility in the real world, there remain several limitations concerning manual QE data creation: inevitably incurred non-trivial costs due to the need for translation experts, and issues with data scaling and language expansion. To tackle these limitations, we present QUAK, a Korean-English synthetic QE dataset generated in a fully automatic manner. This consists of three sub-QUAK datasets QUAK-M, QUAK-P, and QUAK-H, produced through three strategies that are relatively free from language constraints. Since each strategy requires no human effort, which facilitates scalability, we scale our data up to 1.58M for QUAK-P, H and 6.58M for QUAK-M. As an experiment, we quantitatively analyze word-level QE results in various ways while performing statistical analysis. Moreover, we show that datasets scaled in an efficient way also contribute to performance improvements by observing meaningful performance gains in QUAK-M, P when adding data up to 1.58M.
A Self-Supervised Automatic Post-Editing Data Generation Tool
Nov 24, 2021
Data building for automatic post-editing (APE) requires extensive and expert-level human effort, as it contains an elaborate process that involves identifying errors in sentences and providing suitable revisions. Hence, we develop a self-supervised data generation tool, deployable as a web application, that minimizes human supervision and constructs personalized APE data from a parallel corpus for several language pairs with English as the target language. Data-centric APE research can be conducted using this tool, involving many language pairs that have not been studied thus far owing to the lack of suitable data.
A New Tool for Efficiently Generating Quality Estimation Datasets
Nov 01, 2021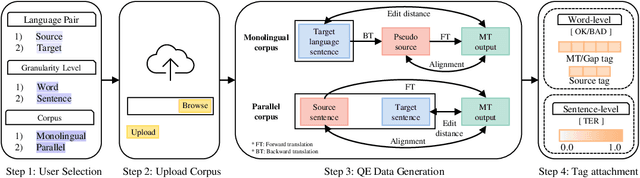
Building of data for quality estimation (QE) training is expensive and requires significant human labor. In this study, we focus on a data-centric approach while performing QE, and subsequently propose a fully automatic pseudo-QE dataset generation tool that generates QE datasets by receiving only monolingual or parallel corpus as the input. Consequently, the QE performance is enhanced either by data augmentation or by encouraging multiple language pairs to exploit the applicability of QE. Further, we intend to publicly release this user friendly QE dataset generation tool as we believe this tool provides a new, inexpensive method to the community for developing QE datasets.
Automatic Knowledge Augmentation for Generative Commonsense Reasoning
Oct 30, 2021
Generative commonsense reasoning is the capability of a language model to generate a sentence with a given concept-set that is based on commonsense knowledge. However, generative language models still struggle to provide outputs, and the training set does not contain patterns that are sufficient for generative commonsense reasoning. In this paper, we propose a data-centric method that uses automatic knowledge augmentation to extend commonsense knowledge using a machine knowledge generator. This method can generate semi-golden sentences that improve the generative commonsense reasoning of a language model without architecture modifications. Furthermore, this approach is a model-agnostic method and does not require human effort for data construction.
How should human translation coexist with NMT? Efficient tool for building high quality parallel corpus
Oct 30, 2021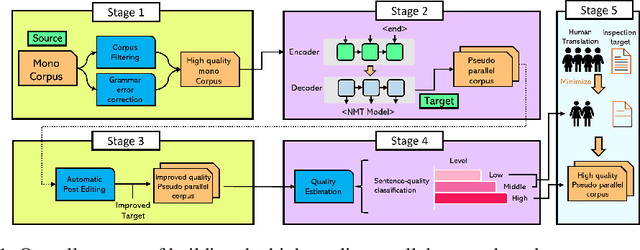
This paper proposes a tool for efficiently constructing high-quality parallel corpora with minimizing human labor and making this tool publicly available. Our proposed construction process is based on neural machine translation (NMT) to allow for it to not only coexist with human translation, but also improve its efficiency by combining data quality control with human translation in a data-centric approach.