Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Tool for Efficiently Generating Quality Estimation Datasets
Paper and Code
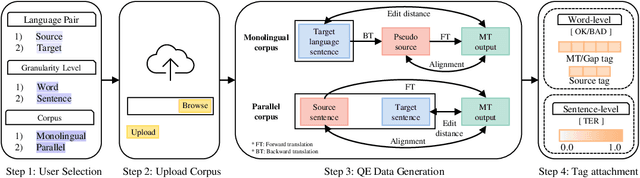
Building of data for quality estimation (QE) training is expensive and requires significant human labor. In this study, we focus on a data-centric approach while performing QE, and subsequently propose a fully automatic pseudo-QE dataset generation tool that generates QE datasets by receiving only monolingual or parallel corpus as the input. Consequently, the QE performance is enhanced either by data augmentation or by encouraging multiple language pairs to exploit the applicability of QE. Further, we intend to publicly release this user friendly QE dataset generation tool as we believe this tool provides a new, inexpensive method to the community for developing QE datasets.
* Accepted for Data-centric AI workshop at NeurIPS 2021
View paper on