 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-hoc Utterance Refining Method by Entity Mining for Faithful Knowledge Grounded Conversations
Jun 16, 2024

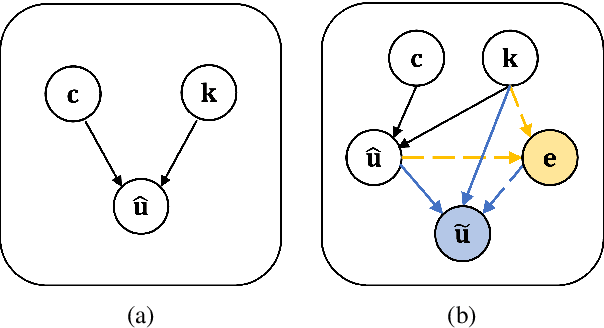
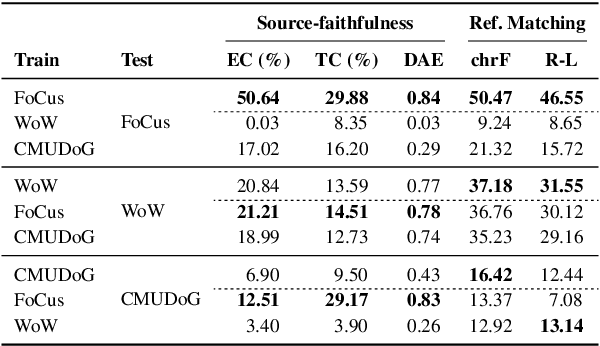
Despite the striking advances in recent language generation performance, model-generated responses have suffered from the chronic problem of hallucinations that are either untrue or unfaithful to a given source. Especially in the task of knowledge grounded conversation, the models are required to generate informative responses, but hallucinated utterances lead to miscommunication. In particular, entity-level hallucination that causes critical misinformation and undesirable conversation is one of the major concerns. To address this issue, we propose a post-hoc refinement method called REM. It aims to enhance the quality and faithfulness of hallucinated utterances by refining them based on the source knowledge. If the generated utterance has a low source-faithfulness score with the given knowledge, REM mines the key entities in the knowledge and implicitly uses them for refining the utterances. We verify that our method reduces entity hallucination in the utterance. Also, we show the adaptability and efficacy of REM with extensive experiments and generative results. Our code is available at https://github.com/YOONNAJANG/REM.
KoBigBird-large: Transformation of Transformer for Korean Language Understanding
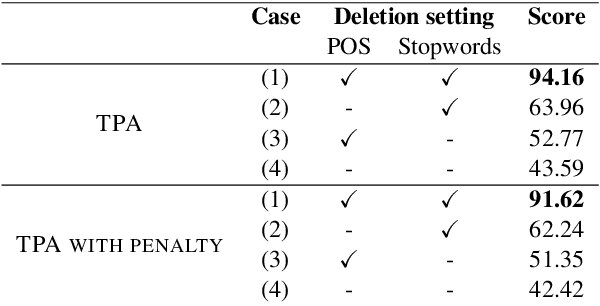
Sep 19, 2023This work presents KoBigBird-large, a large size of Korean BigBird that achieves state-of-the-art performance and allows long sequence processing for Korean language understanding. Without further pretraining, we only transform the architecture and extend the positional encoding with our proposed Tapered Absolute Positional Encoding Representations (TAPER). In experiments, KoBigBird-large shows state-of-the-art overall performance on Korean language understanding benchmarks and the best performance on document classification and question answering tasks for longer sequences against the competitive baseline models. We publicly release our model here.
You Truly Understand What I Need: Intellectual and Friendly Dialogue Agents grounding Knowledge and Persona
Jan 06, 2023
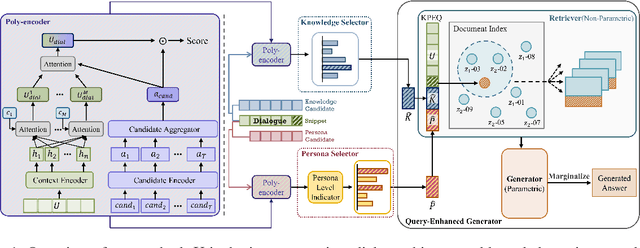


To build a conversational agent that interacts fluently with humans, previous studies blend knowledge or personal profile into the pre-trained language model. However, the model that considers knowledge and persona at the same time is still limited, leading to hallucination and a passive way of using personas. We propose an effective dialogue agent that grounds external knowledge and persona simultaneously. The agent selects the proper knowledge and persona to use for generating the answers with our candidate scoring implemented with a poly-encoder. Then, our model generates the utterance with lesser hallucination and more engagingness utilizing retrieval augmented generation with knowledge-persona enhanced query. We conduct experiments on the persona-knowledge chat and achieve state-of-the-art performance in grounding and generation tasks on the automatic metrics. Moreover, we validate the answers from the models regarding hallucination and engagingness through human evaluation and qualitative results. We show our retriever's effectiveness in extracting relevant documents compared to the other previous retrievers, along with the comparison of multiple candidate scoring methods. Code is available at https://github.com/dlawjddn803/INFO
Analysis of Utterance Embeddings and Clustering Methods Related to Intent Induction for Task-Oriented Dialogue
Dec 06, 2022

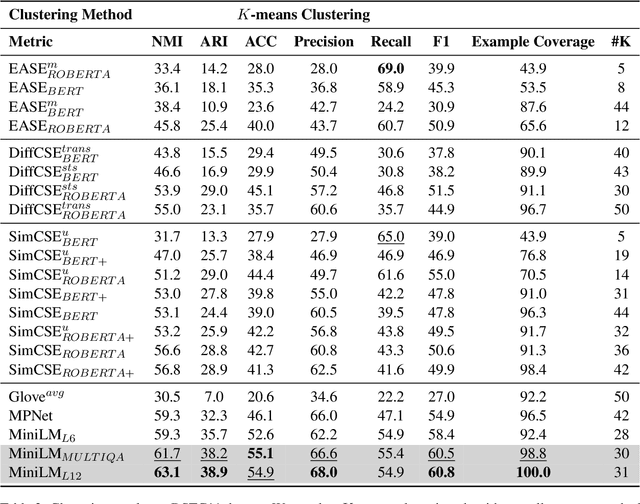

This paper investigates unsupervised approaches to overcome quintessential challenges in designing task-oriented dialog schema: assigning intent labels to each dialog turn (intent clustering) and generating a set of intents based on the intent clustering methods (intent induction). We postulate there are two salient factors for automatic induction of intents: (1) clustering algorithm for intent labeling and (2) user utterance embedding space. We compare existing off-the-shelf clustering models and embeddings based on DSTC11 evaluation. Our extensive experiments demonstrate that we sholud add two huge caveat that selection of utterance embedding and clustering method in intent induction task should be very careful. We also present that pretrained MiniLM with Agglomerative clustering shows significant improvement in NMI, ARI, F1, accuracy and example coverage in intent induction tasks. The source code for reimplementation will be available at Github.
Language Chameleon: Transformation analysis between languages using Cross-lingual Post-training based on Pre-trained language models
Sep 14, 2022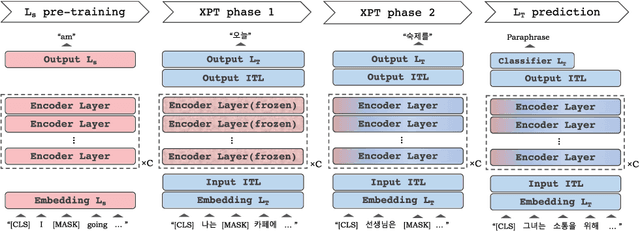
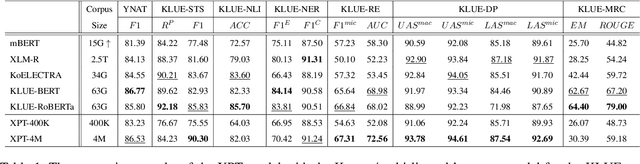

As pre-trained language models become more resource-demanding, the inequality between resource-rich languages such as English and resource-scarce languages is worsening. This can be attributed to the fact that the amount of available training data in each language follows the power-law distribution, and most of the languages belong to the long tail of the distribution. Some research areas attempt to mitigate this problem. For example, in cross-lingual transfer learning and multilingual training, the goal is to benefit long-tail languages via the knowledge acquired from resource-rich languages. Although being successful, existing work has mainly focused on experimenting on as many languages as possible. As a result, targeted in-depth analysis is mostly absent. In this study, we focus on a single low-resource language and perform extensive evaluation and probing experiments using cross-lingual post-training (XPT). To make the transfer scenario challenging, we choose Korean as the target language, as it is a language isolate and thus shares almost no typology with English. Results show that XPT not only outperforms or performs on par with monolingual models trained with orders of magnitudes more data but also is highly efficient in the transfer process.
Call for Customized Conversation: Customized Conversation Grounding Persona and Knowledge
Dec 16, 2021


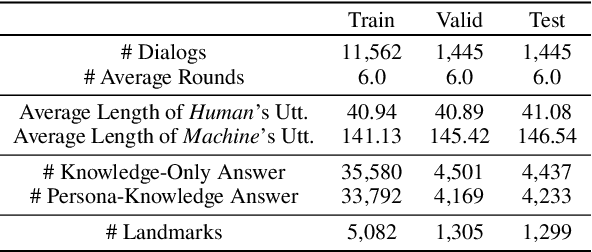
Humans usually have conversations by making use of prior knowledge about a topic and background information of the people whom they are talking to. However, existing conversational agents and datasets do not consider such comprehensive information, and thus they have a limitation in generating the utterances where the knowledge and persona are fused properly. To address this issue, we introduce a call For Customized conversation (FoCus) dataset where the customized answers are built with the user's persona and Wikipedia knowledge. To evaluate the abilities to make informative and customized utterances of pre-trained language models, we utilize BART and GPT-2 as well as transformer-based models. We assess their generation abilities with automatic scores and conduct human evaluations for qualitative results. We examine whether the model reflects adequate persona and knowledge with our proposed two sub-tasks, persona grounding (PG) and knowledge grounding (KG). Moreover, we show that the utterances of our data are constructed with the proper knowledge and persona through grounding quality assessment.
FreeTalky: Don't Be Afraid! Conversations Made Easier by a Humanoid Robot using Persona-based Dialogue
Dec 08, 2021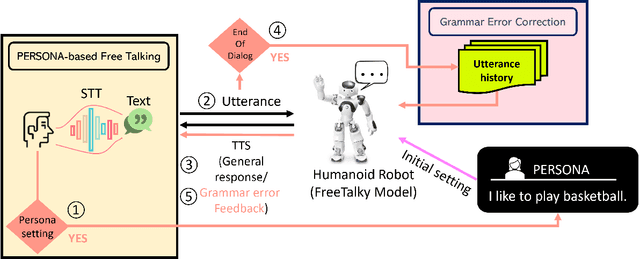

We propose a deep learning-based foreign language learning platform, named FreeTalky, for people who experience anxiety dealing with foreign languages, by employing a humanoid robot NAO and various deep learning models. A persona-based dialogue system that is embedded in NAO provides an interesting and consistent multi-turn dialogue for users. Also, an grammar error correction system promotes improvement in grammar skills of the users. Thus, our system enables personalized learning based on persona dialogue and facilitates grammar learning of a user using grammar error feedback. Furthermore, we verified whether FreeTalky provides practical help in alleviating xenoglossophobia by replacing the real human in the conversation with a NAO robot, through human evaluation.
PicTalky: Augmentative and Alternative Communication Software for Language Developmental Disabilities
Sep 27, 2021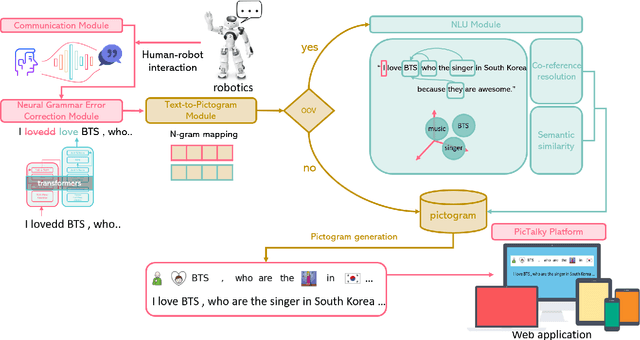

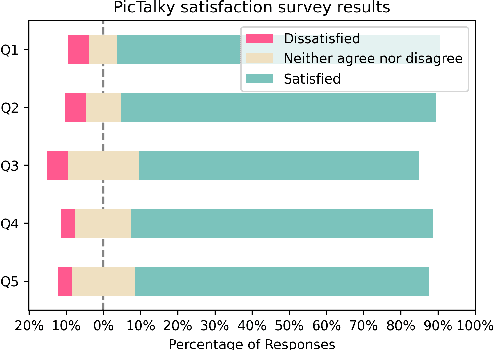
Augmentative and alternative communication (AAC) is a practical means of communication for people with language disabilities. In this study, we propose PicTalky, which is an AI-based AAC system that helps children with language developmental disabilities to improve their communication skills and language comprehension abilities. PicTalky can process both text and pictograms more accurately by connecting a series of neural-based NLP modules. Moreover, we perform quantitative and qualitative analyses on the essential features of PicTalky. It is expected that those suffering from language problems will be able to express their intentions or desires more easily and improve their quality of life by using this service. We have made the models freely available alongside a demonstration of the Web interface. Furthermore, we implemented robotics AAC for the first time by applying PicTalky to the NAO robot.
I Know What You Asked: Graph Path Learning using AMR for Commonsense Reasoning
Nov 06, 2020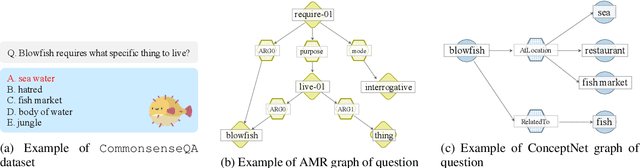
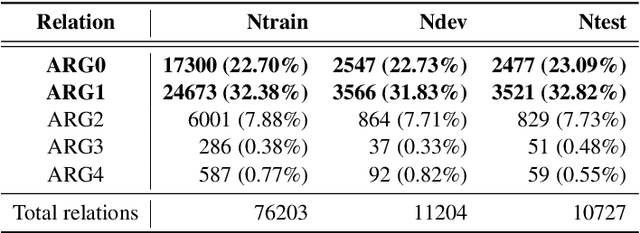
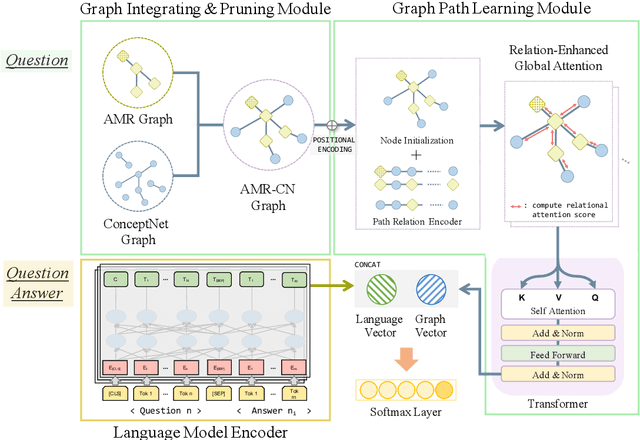
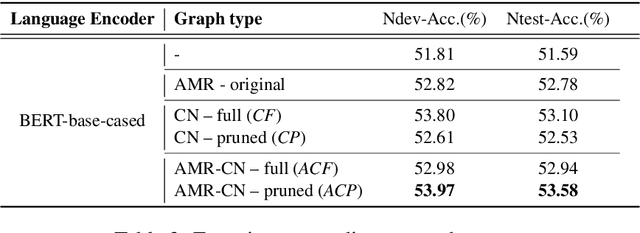
CommonsenseQA is a task in which a correct answer is predicted through commonsense reasoning with pre-defined knowledge. Most previous works have aimed to improve the performance with distributed representation without considering the process of predicting the answer from the semantic representation of the question. To shed light upon the semantic interpretation of the question, we propose an AMR-ConceptNet-Pruned (ACP) graph. The ACP graph is pruned from a full integrated graph encompassing Abstract Meaning Representation (AMR) graph generated from input questions and an external commonsense knowledge graph, ConceptNet (CN). Then the ACP graph is exploited to interpret the reasoning path as well as to predict the correct answer on the CommonsenseQA task. This paper presents the manner in which the commonsense reasoning process can be interpreted with the relations and concepts provided by the ACP graph. Moreover, ACP-based models are shown to outperform the baselines.