 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Ambiguity to Accuracy: The Transformative Effect of Coreference Resolution on Retrieval-Augmented Generation systems
Jul 10, 2025Retrieval-Augmented Generation (RAG) has emerged as a crucial framework in natural language processing (NLP), improving factual consistency and reducing hallucinations by integrating external document retrieval with large language models (LLMs). However, the effectiveness of RAG is often hindered by coreferential complexity in retrieved documents, introducing ambiguity that disrupts in-context learning. In this study, we systematically investigate how entity coreference affects both document retrieval and generative performance in RAG-based systems, focusing on retrieval relevance, contextual understanding, and overall response quality. We demonstrate that coreference resolution enhances retrieval effectiveness and improves question-answering (QA) performance. Through comparative analysis of different pooling strategies in retrieval tasks, we find that mean pooling demonstrates superior context capturing ability after applying coreference resolution. In QA tasks, we discover that smaller models benefit more from the disambiguation process, likely due to their limited inherent capacity for handling referential ambiguity. With these findings, this study aims to provide a deeper understanding of the challenges posed by coreferential complexity in RAG, providing guidance for improving retrieval and generation in knowledge-intensive AI applications.
Generating Multi-Table Time Series EHR from Latent Space with Minimal Preprocessing
Jul 09, 2025Electronic Health Records (EHR) are time-series relational databases that record patient interactions and medical events over time, serving as a critical resource for healthcare research and applications. However, privacy concerns and regulatory restrictions limit the sharing and utilization of such sensitive data, necessitating the generation of synthetic EHR datasets. Unlike previous EHR synthesis methods, which typically generate medical records consisting of expert-chosen features (e.g. a few vital signs or structured codes only), we introduce RawMed, the first framework to synthesize multi-table, time-series EHR data that closely resembles raw EHRs. Using text-based representation and compression techniques, RawMed captures complex structures and temporal dynamics with minimal preprocessing. We also propose a new evaluation framework for multi-table time-series synthetic EHRs, assessing distributional similarity, inter-table relationships, temporal dynamics, and privacy. Validated on two open-source EHR datasets, RawMed outperforms baseline models in fidelity and utility. The code is available at https://github.com/eunbyeol-cho/RawMed.
Enhancing LLMs' Clinical Reasoning with Real-World Data from a Nationwide Sepsis Registry
May 05, 2025Although large language models (LLMs) have demonstrated impressive reasoning capabilities across general domains, their effectiveness in real-world clinical practice remains limited. This is likely due to their insufficient exposure to real-world clinical data during training, as such data is typically not included due to privacy concerns. To address this, we propose enhancing the clinical reasoning capabilities of LLMs by leveraging real-world clinical data. We constructed reasoning-intensive questions from a nationwide sepsis registry and fine-tuned Phi-4 on these questions using reinforcement learning, resulting in C-Reason. C-Reason exhibited strong clinical reasoning capabilities on the in-domain test set, as evidenced by both quantitative metrics and expert evaluations. Furthermore, its enhanced reasoning capabilities generalized to a sepsis dataset involving different tasks and patient cohorts, an open-ended consultations on antibiotics use task, and other diseases. Future research should focus on training LLMs with large-scale, multi-disease clinical datasets to develop more powerful, general-purpose clinical reasoning models.
Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning
Dec 20, 2024



Despite recent advances in large language models, open-source models often struggle to consistently perform well on complex reasoning tasks. Existing ensemble methods, whether applied at the token or output levels, fail to address these challenges. In response, we present Language model Ensemble with Monte Carlo Tree Search (LE-MCTS), a novel framework for process-level ensembling of language models. LE-MCTS formulates step-by-step reasoning with an ensemble of language models as a Markov decision process. In this framework, states represent intermediate reasoning paths, while actions consist of generating the next reasoning step using one of the language models selected from a predefined pool. Guided by a process-based reward model, LE-MCTS performs a tree search over the reasoning steps generated by different language models, identifying the most accurate reasoning chain. Experimental results on five mathematical reasoning benchmarks demonstrate that our approach outperforms both single language model decoding algorithms and language model ensemble methods. Notably, LE-MCTS improves performance by 3.6% and 4.3% on the MATH and MQA datasets, respectively, highlighting its effectiveness in solving complex reasoning problems.
Multimodal Transformer With a Low-Computational-Cost Guarantee
Feb 23, 2024Transformer-based models have significantly improved performance across a range of multimodal understanding tasks, such as visual question answering and action recognition. However, multimodal Transformers significantly suffer from a quadratic complexity of the multi-head attention with the input sequence length, especially as the number of modalities increases. To address this, we introduce Low-Cost Multimodal Transformer (LoCoMT), a novel multimodal attention mechanism that aims to reduce computational cost during training and inference with minimal performance loss. Specifically, by assigning different multimodal attention patterns to each attention head, LoCoMT can flexibly control multimodal signals and theoretically ensures a reduced computational cost compared to existing multimodal Transformer variants. Experimental results on two multimodal datasets, namely Audioset and MedVidCL demonstrate that LoCoMT not only reduces GFLOPs but also matches or even outperforms established models.
FactKG: Fact Verification via Reasoning on Knowledge Graphs
May 19, 2023In real world applications, knowledge graphs (KG) are widely used in various domains (e.g. medical applications and dialogue agents). However, for fact verification, KGs have not been adequately utilized as a knowledge source. KGs can be a valuable knowledge source in fact verification due to their reliability and broad applicability. A KG consists of nodes and edges which makes it clear how concepts are linked together, allowing machines to reason over chains of topics. However, there are many challenges in understanding how these machine-readable concepts map to information in text. To enable the community to better use KGs, we introduce a new dataset, FactKG: Fact Verification via Reasoning on Knowledge Graphs. It consists of 108k natural language claims with five types of reasoning: One-hop, Conjunction, Existence, Multi-hop, and Negation. Furthermore, FactKG contains various linguistic patterns, including colloquial style claims as well as written style claims to increase practicality. Lastly, we develop a baseline approach and analyze FactKG over these reasoning types. We believe FactKG can advance both reliability and practicality in KG-based fact verification.
Do Language Models Understand Measurements?
Oct 23, 2022Recent success of pre-trained language models (PLMs) has stimulated interest in their ability to understand and work with numbers. Yet, the numerical reasoning over measurements has not been formally studied despite their importance. In this study, we show that PLMs lack the capability required for reasoning over measurements. Furthermore, we find that a language model trained on a measurement-rich corpus shows better performance on understanding measurements. We propose a simple embedding strategy to better distinguish between numbers and units, which leads to a significant improvement in the probing tasks.
Unconditional Image-Text Pair Generation with Multimodal Cross Quantizer
Apr 15, 2022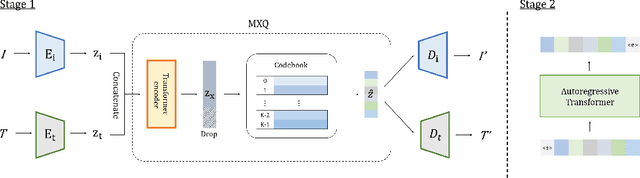
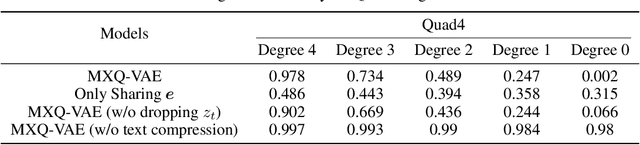
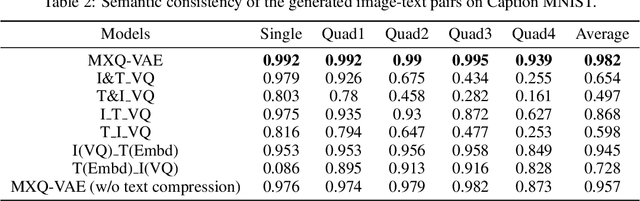

Though deep generative models have gained a lot of attention, most of the existing works are designed for the unimodal generation task. In this paper, we explore a new method for unconditional image-text pair generation. We propose MXQ-VAE, a vector quantization method for multimodal image-text representation. MXQ-VAE accepts a paired image and text as input, and learns a joint quantized representation space, so that the image-text pair can be converted to a sequence of unified indices. Then we can use autoregressive generative models to model the joint image-text representation, and even perform unconditional image-text pair generation. Extensive experimental results demonstrate that our approach effectively generates semantically consistent image-text pair and also enhances meaningful alignment between image and text.
Graph-Text Multi-Modal Pre-training for Medical Representation Learning
Mar 18, 2022

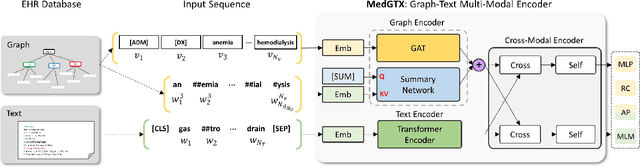

As the volume of Electronic Health Records (EHR) sharply grows, there has been emerging interest in learning the representation of EHR for healthcare applications. Representation learning of EHR requires appropriate modeling of the two dominant modalities in EHR: structured data and unstructured text. In this paper, we present MedGTX, a pre-trained model for multi-modal representation learning of the structured and textual EHR data. MedGTX uses a novel graph encoder to exploit the graphical nature of structured EHR data, and a text encoder to handle unstructured text, and a cross-modal encoder to learn a joint representation space. We pre-train our model through four proxy tasks on MIMIC-III, an open-source EHR data, and evaluate our model on two clinical benchmarks and three novel downstream tasks which tackle real-world problems in EHR data. The results consistently show the effectiveness of pre-training the model for joint representation of both structured and unstructured information from EHR. Given the promising performance of MedGTX, we believe this work opens a new door to jointly understanding the two fundamental modalities of EHR data.
FreeTalky: Don't Be Afraid! Conversations Made Easier by a Humanoid Robot using Persona-based Dialogue
Dec 08, 2021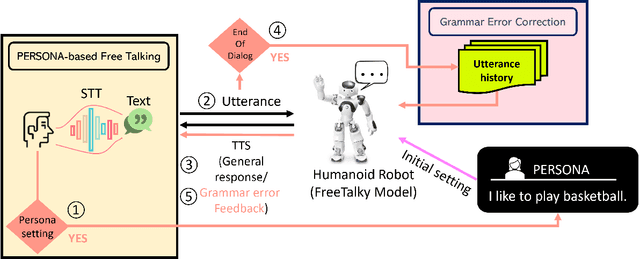

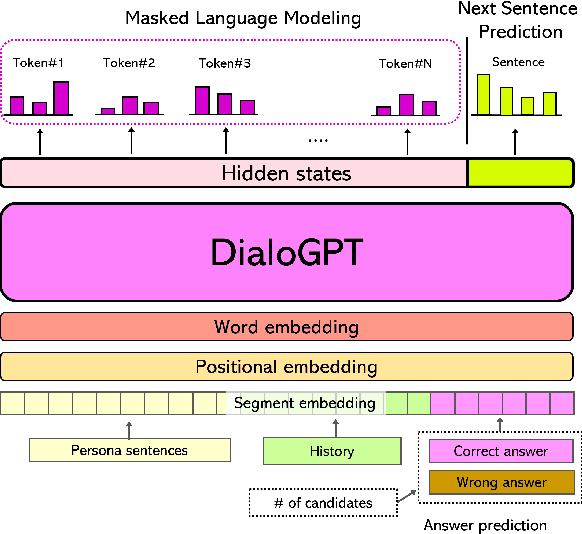
We propose a deep learning-based foreign language learning platform, named FreeTalky, for people who experience anxiety dealing with foreign languages, by employing a humanoid robot NAO and various deep learning models. A persona-based dialogue system that is embedded in NAO provides an interesting and consistent multi-turn dialogue for users. Also, an grammar error correction system promotes improvement in grammar skills of the users. Thus, our system enables personalized learning based on persona dialogue and facilitates grammar learning of a user using grammar error feedback. Furthermore, we verified whether FreeTalky provides practical help in alleviating xenoglossophobia by replacing the real human in the conversation with a NAO robot, through human evaluation.