 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCXReasonAgent: Evidence-Grounded Diagnostic Reasoning Agent for Chest X-rays
Feb 26, 2026Chest X-ray plays a central role in thoracic diagnosis, and its interpretation inherently requires multi-step, evidence-grounded reasoning. However, large vision-language models (LVLMs) often generate plausible responses that are not faithfully grounded in diagnostic evidence and provide limited visual evidence for verification, while also requiring costly retraining to support new diagnostic tasks, limiting their reliability and adaptability in clinical settings. To address these limitations, we present CXReasonAgent, a diagnostic agent that integrates a large language model (LLM) with clinically grounded diagnostic tools to perform evidence-grounded diagnostic reasoning using image-derived diagnostic and visual evidence. To evaluate these capabilities, we introduce CXReasonDial, a multi-turn dialogue benchmark with 1,946 dialogues across 12 diagnostic tasks, and show that CXReasonAgent produces faithfully grounded responses, enabling more reliable and verifiable diagnostic reasoning than LVLMs. These findings highlight the importance of integrating clinically grounded diagnostic tools, particularly in safety-critical clinical settings.
CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays
May 23, 2025Recent progress in Large Vision-Language Models (LVLMs) has enabled promising applications in medical tasks, such as report generation and visual question answering. However, existing benchmarks focus mainly on the final diagnostic answer, offering limited insight into whether models engage in clinically meaningful reasoning. To address this, we present CheXStruct and CXReasonBench, a structured pipeline and benchmark built on the publicly available MIMIC-CXR-JPG dataset. CheXStruct automatically derives a sequence of intermediate reasoning steps directly from chest X-rays, such as segmenting anatomical regions, deriving anatomical landmarks and diagnostic measurements, computing diagnostic indices, and applying clinical thresholds. CXReasonBench leverages this pipeline to evaluate whether models can perform clinically valid reasoning steps and to what extent they can learn from structured guidance, enabling fine-grained and transparent assessment of diagnostic reasoning. The benchmark comprises 18,988 QA pairs across 12 diagnostic tasks and 1,200 cases, each paired with up to 4 visual inputs, and supports multi-path, multi-stage evaluation including visual grounding via anatomical region selection and diagnostic measurements. Even the strongest of 10 evaluated LVLMs struggle with structured reasoning and generalization, often failing to link abstract knowledge with anatomically grounded visual interpretation. The code is available at https://github.com/ttumyche/CXReasonBench
Unified Chest X-ray and Radiology Report Generation Model with Multi-view Chest X-rays
Mar 01, 2023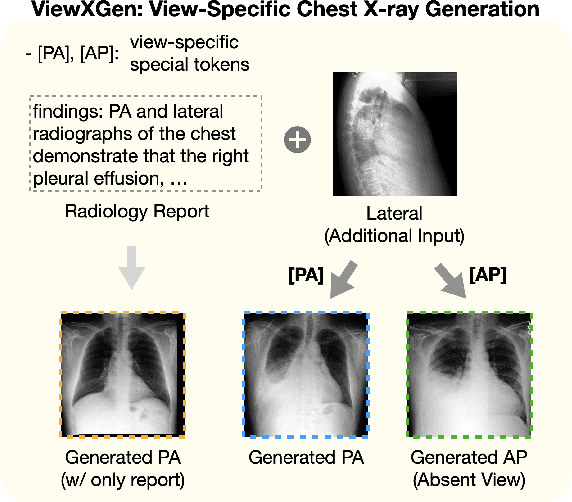
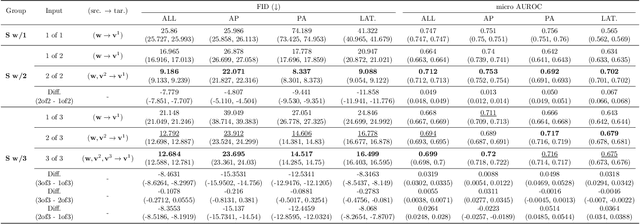
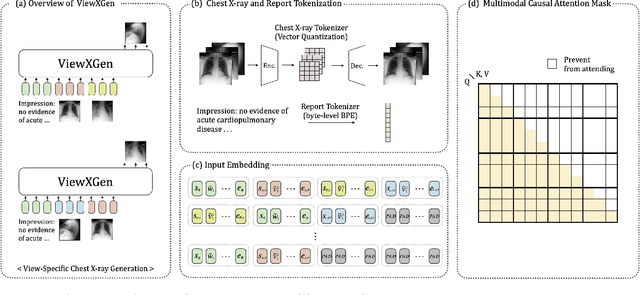
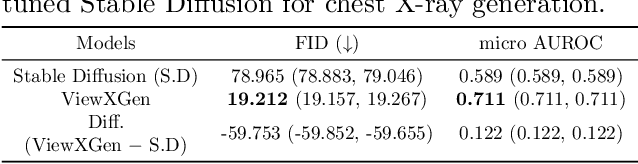
Generated synthetic data in medical research can substitute privacy and security-sensitive data with a large-scale curated dataset, reducing data collection and annotation costs. As part of this effort, we propose UniXGen, a unified chest X-ray and report generation model, with the following contributions. First, we design a unified model for bidirectional chest X-ray and report generation by adopting a vector quantization method to discretize chest X-rays into discrete visual tokens and formulating both tasks as sequence generation tasks. Second, we introduce several special tokens to generate chest X-rays with specific views that can be useful when the desired views are unavailable. Furthermore, UniXGen can flexibly take various inputs from single to multiple views to take advantage of the additional findings available in other X-ray views. We adopt an efficient transformer for computational and memory efficiency to handle the long-range input sequence of multi-view chest X-rays with high resolution and long paragraph reports. In extensive experiments, we show that our unified model has a synergistic effect on both generation tasks, as opposed to training only the task-specific models. We also find that view-specific special tokens can distinguish between different views and properly generate specific views even if they do not exist in the dataset, and utilizing multi-view chest X-rays can faithfully capture the abnormal findings in the additional X-rays. The source code is publicly available at: https://github.com/ttumyche/UniXGen.
Unconditional Image-Text Pair Generation with Multimodal Cross Quantizer
Apr 15, 2022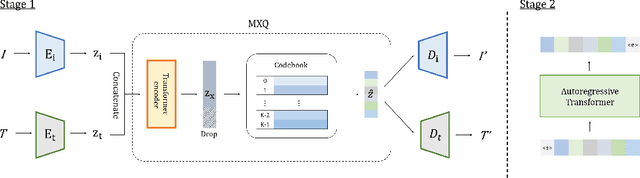
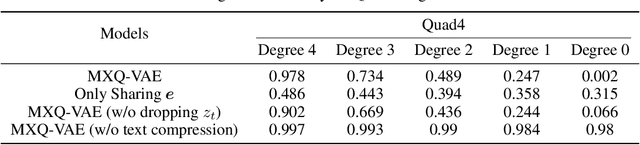
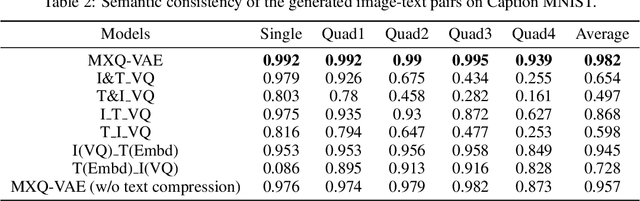

Though deep generative models have gained a lot of attention, most of the existing works are designed for the unimodal generation task. In this paper, we explore a new method for unconditional image-text pair generation. We propose MXQ-VAE, a vector quantization method for multimodal image-text representation. MXQ-VAE accepts a paired image and text as input, and learns a joint quantized representation space, so that the image-text pair can be converted to a sequence of unified indices. Then we can use autoregressive generative models to model the joint image-text representation, and even perform unconditional image-text pair generation. Extensive experimental results demonstrate that our approach effectively generates semantically consistent image-text pair and also enhances meaningful alignment between image and text.
Multi-modal Understanding and Generation for Medical Images and Text via Vision-Language Pre-Training
May 24, 2021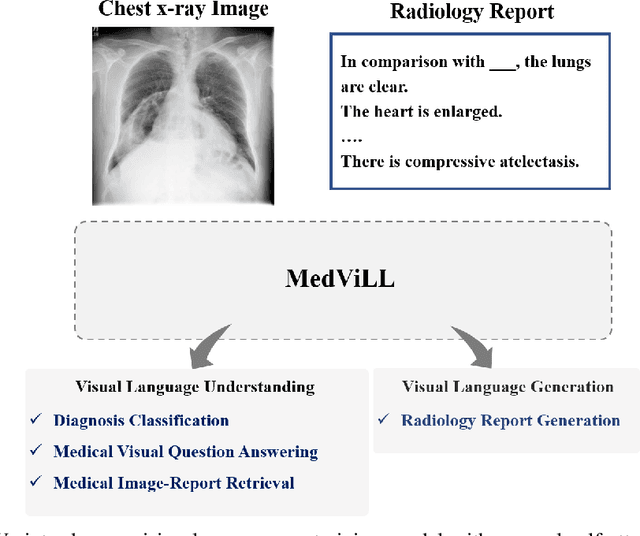

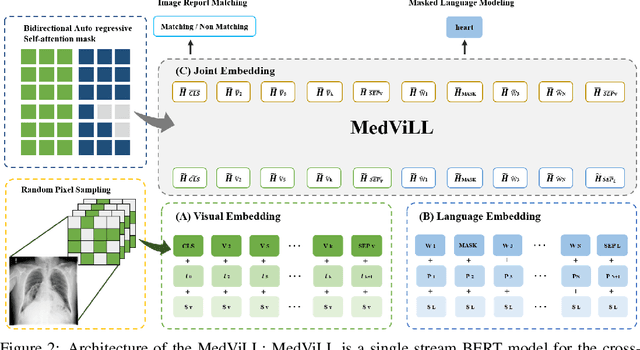
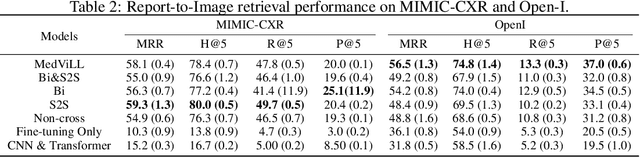
Recently a number of studies demonstrated impressive performance on diverse vision-language multi-modal tasks such as image captioning and visual question answering by extending the BERT architecture with multi-modal pre-training objectives. In this work we explore a broad set of multi-modal representation learning tasks in the medical domain, specifically using radiology images and the unstructured report. We propose Medical Vision Language Learner (MedViLL) which adopts a Transformer-based architecture combined with a novel multimodal attention masking scheme to maximize generalization performance for both vision-language understanding tasks (image-report retrieval, disease classification, medical visual question answering) and vision-language generation task (report generation). By rigorously evaluating the proposed model on four downstream tasks with two chest X-ray image datasets (MIMIC-CXR and Open-I), we empirically demonstrate the superior downstream task performance of MedViLL against various baselines including task-specific architectures.