 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIAGE: Dialectical Reasoning for Explainable Risk Prediction on Irregularly Sampled Medical Time Series with LLMs
Jun 08, 2026Clinical early warning systems built on electronic health records, in which clinical observations are recorded as irregularly sampled medical time series (ISMTS), must deliver both calibrated risk scores for patient triage and interpretable rationales that clinicians can verify. Large Language Models (LLMs) have been explored for this task, yet they collapse graded clinical risk into overconfident binary predictions. This risk polarization undermines both calibration and cross-patient comparability. To address this, we propose TRIAGE, a framework that trains an LLM to generate dialectical reasoning over competing clinical outcomes by eliciting outcome-specific rationales. This dialectical formulation mitigates risk polarization, enabling a single LLM to yield continuous risk scores grounded in explicit clinical reasoning. Evaluated on three ISMTS benchmarks, TRIAGE achieves an average AUPRC improvement of 3.3% and reduces calibration error by 81% compared to the competitive baselines. An LLM-as-a-judge assessment further shows that our rationales surpass post-hoc explanations from the baseline by 20% in clinical reasoning quality. The source code is available at https://github.com/HyeongWon-Jang/TRIAGE .
Towards Error-Free EHRs: Reasoning-Intensive Consistency Verification Between Clinical Notes and Structured Tables in Electronic Health Records
May 26, 2026Data consistency between unstructured clinical notes and structured tables in Electronic Health Records (EHRs) is essential for patient safety and clinical decision-making. However, existing work on note-table consistency verification mainly relies on surface-level matching of numeric values or simple events. Such approaches fail to capture the reasoning underlying real-world EHR documentation, including clinical interpretation, event relations, and temporal changes. To address this gap, we introduce EHR-ReasonCon, a reasoning-intensive benchmark for note-table consistency verification. Built on MIMIC-III with expert-guided annotations, it comprises 8,048 entities derived from clinical notes and provides high-quality ground-truth labels. The annotation protocol is supported by specialized table-exploration tools to ensure systematic evidence retrieval and reliable consistency assessment. We also propose EHR-Inspector, an LLM-based framework that segments notes, extracts anchor entities and temporal references, and uses table-exploration tools to verify consistency against structured tables. Evaluated using expert-validated LLM-as-a-judge metrics under harsh and lenient criteria, EHR-Inspector achieves state-of-the-art performance across multiple model backbones. Analyses further demonstrate the effectiveness of its components and highlight differences from human verification.
ECG-Reasoning-Benchmark: A Benchmark for Evaluating Clinical Reasoning Capabilities in ECG Interpretation
Mar 15, 2026While Multimodal Large Language Models (MLLMs) show promising performance in automated electrocardiogram interpretation, it remains unclear whether they genuinely perform actual step-by-step reasoning or just rely on superficial visual cues. To investigate this, we introduce \textbf{ECG-Reasoning-Benchmark}, a novel multi-turn evaluation framework comprising over 6,400 samples to systematically assess step-by-step reasoning across 17 core ECG diagnoses. Our comprehensive evaluation of state-of-the-art models reveals a critical failure in executing multi-step logical deduction. Although models possess the medical knowledge to retrieve clinical criteria for a diagnosis, they exhibit near-zero success rates (6% Completion) in maintaining a complete reasoning chain, primarily failing to ground the corresponding ECG findings to the actual visual evidence in the ECG signal. These results demonstrate that current MLLMs bypass actual visual interpretation, exposing a critical flaw in existing training paradigms and underscoring the necessity for robust, reasoning-centric medical AI. The code and data are available at https://github.com/Jwoo5/ecg-reasoning-benchmark.
CXReasonAgent: Evidence-Grounded Diagnostic Reasoning Agent for Chest X-rays
Feb 26, 2026Chest X-ray plays a central role in thoracic diagnosis, and its interpretation inherently requires multi-step, evidence-grounded reasoning. However, large vision-language models (LVLMs) often generate plausible responses that are not faithfully grounded in diagnostic evidence and provide limited visual evidence for verification, while also requiring costly retraining to support new diagnostic tasks, limiting their reliability and adaptability in clinical settings. To address these limitations, we present CXReasonAgent, a diagnostic agent that integrates a large language model (LLM) with clinically grounded diagnostic tools to perform evidence-grounded diagnostic reasoning using image-derived diagnostic and visual evidence. To evaluate these capabilities, we introduce CXReasonDial, a multi-turn dialogue benchmark with 1,946 dialogues across 12 diagnostic tasks, and show that CXReasonAgent produces faithfully grounded responses, enabling more reliable and verifiable diagnostic reasoning than LVLMs. These findings highlight the importance of integrating clinically grounded diagnostic tools, particularly in safety-critical clinical settings.
Instruction-Guided Lesion Segmentation for Chest X-rays with Automatically Generated Large-Scale Dataset
Nov 19, 2025The applicability of current lesion segmentation models for chest X-rays (CXRs) has been limited both by a small number of target labels and the reliance on long, detailed expert-level text inputs, creating a barrier to practical use. To address these limitations, we introduce a new paradigm: instruction-guided lesion segmentation (ILS), which is designed to segment diverse lesion types based on simple, user-friendly instructions. Under this paradigm, we construct MIMIC-ILS, the first large-scale instruction-answer dataset for CXR lesion segmentation, using our fully automated multimodal pipeline that generates annotations from chest X-ray images and their corresponding reports. MIMIC-ILS contains 1.1M instruction-answer pairs derived from 192K images and 91K unique segmentation masks, covering seven major lesion types. To empirically demonstrate its utility, we introduce ROSALIA, a vision-language model fine-tuned on MIMIC-ILS. ROSALIA can segment diverse lesions and provide textual explanations in response to user instructions. The model achieves high segmentation and textual accuracy in our newly proposed task, highlighting the effectiveness of our pipeline and the value of MIMIC-ILS as a foundational resource for pixel-level CXR lesion grounding.
Modeling Clinical Uncertainty in Radiology Reports: from Explicit Uncertainty Markers to Implicit Reasoning Pathways
Nov 06, 2025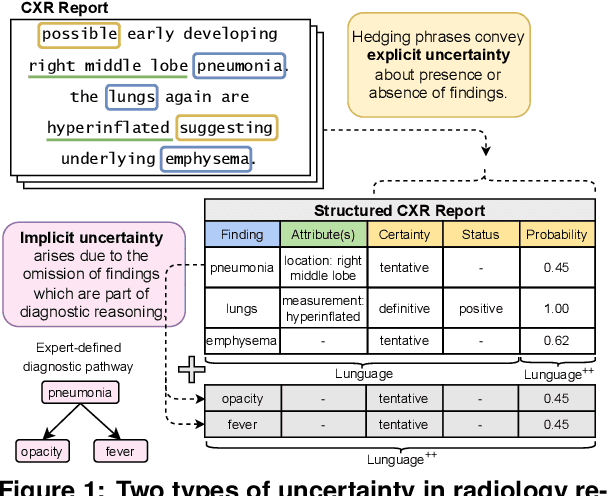
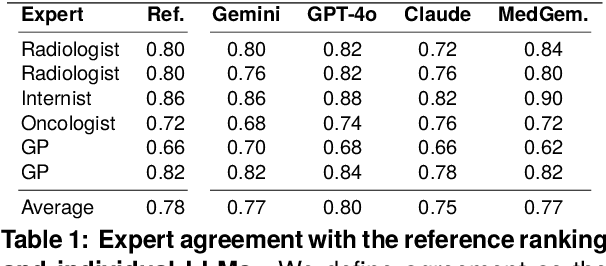
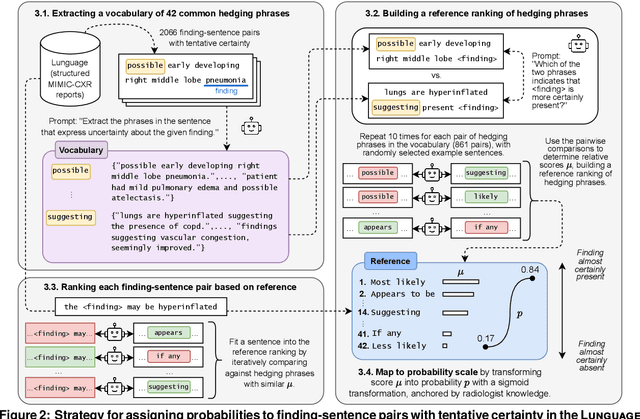
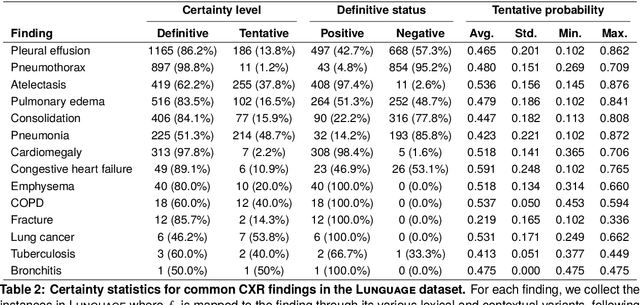
Radiology reports are invaluable for clinical decision-making and hold great potential for automated analysis when structured into machine-readable formats. These reports often contain uncertainty, which we categorize into two distinct types: (i) Explicit uncertainty reflects doubt about the presence or absence of findings, conveyed through hedging phrases. These vary in meaning depending on the context, making rule-based systems insufficient to quantify the level of uncertainty for specific findings; (ii) Implicit uncertainty arises when radiologists omit parts of their reasoning, recording only key findings or diagnoses. Here, it is often unclear whether omitted findings are truly absent or simply unmentioned for brevity. We address these challenges with a two-part framework. We quantify explicit uncertainty by creating an expert-validated, LLM-based reference ranking of common hedging phrases, and mapping each finding to a probability value based on this reference. In addition, we model implicit uncertainty through an expansion framework that systematically adds characteristic sub-findings derived from expert-defined diagnostic pathways for 14 common diagnoses. Using these methods, we release Lunguage++, an expanded, uncertainty-aware version of the Lunguage benchmark of fine-grained structured radiology reports. This enriched resource enables uncertainty-aware image classification, faithful diagnostic reasoning, and new investigations into the clinical impact of diagnostic uncertainty.
Lunguage: A Benchmark for Structured and Sequential Chest X-ray Interpretation
May 27, 2025Radiology reports convey detailed clinical observations and capture diagnostic reasoning that evolves over time. However, existing evaluation methods are limited to single-report settings and rely on coarse metrics that fail to capture fine-grained clinical semantics and temporal dependencies. We introduce LUNGUAGE,a benchmark dataset for structured radiology report generation that supports both single-report evaluation and longitudinal patient-level assessment across multiple studies. It contains 1,473 annotated chest X-ray reports, each reviewed by experts, and 80 of them contain longitudinal annotations to capture disease progression and inter-study intervals, also reviewed by experts. Using this benchmark, we develop a two-stage framework that transforms generated reports into fine-grained, schema-aligned structured representations, enabling longitudinal interpretation. We also propose LUNGUAGESCORE, an interpretable metric that compares structured outputs at the entity, relation, and attribute level while modeling temporal consistency across patient timelines. These contributions establish the first benchmark dataset, structuring framework, and evaluation metric for sequential radiology reporting, with empirical results demonstrating that LUNGUAGESCORE effectively supports structured report evaluation. The code is available at: https://github.com/SuperSupermoon/Lunguage
CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays
May 23, 2025Recent progress in Large Vision-Language Models (LVLMs) has enabled promising applications in medical tasks, such as report generation and visual question answering. However, existing benchmarks focus mainly on the final diagnostic answer, offering limited insight into whether models engage in clinically meaningful reasoning. To address this, we present CheXStruct and CXReasonBench, a structured pipeline and benchmark built on the publicly available MIMIC-CXR-JPG dataset. CheXStruct automatically derives a sequence of intermediate reasoning steps directly from chest X-rays, such as segmenting anatomical regions, deriving anatomical landmarks and diagnostic measurements, computing diagnostic indices, and applying clinical thresholds. CXReasonBench leverages this pipeline to evaluate whether models can perform clinically valid reasoning steps and to what extent they can learn from structured guidance, enabling fine-grained and transparent assessment of diagnostic reasoning. The benchmark comprises 18,988 QA pairs across 12 diagnostic tasks and 1,200 cases, each paired with up to 4 visual inputs, and supports multi-path, multi-stage evaluation including visual grounding via anatomical region selection and diagnostic measurements. Even the strongest of 10 evaluated LVLMs struggle with structured reasoning and generalization, often failing to link abstract knowledge with anatomically grounded visual interpretation. The code is available at https://github.com/ttumyche/CXReasonBench
Med-PerSAM: One-Shot Visual Prompt Tuning for Personalized Segment Anything Model in Medical Domain
Nov 25, 2024



Leveraging pre-trained models with tailored prompts for in-context learning has proven highly effective in NLP tasks. Building on this success, recent studies have applied a similar approach to the Segment Anything Model (SAM) within a ``one-shot" framework, where only a single reference image and its label are employed. However, these methods face limitations in the medical domain, primarily due to SAM's essential requirement for visual prompts and the over-reliance on pixel similarity for generating them. This dependency may lead to (1) inaccurate prompt generation and (2) clustering of point prompts, resulting in suboptimal outcomes. To address these challenges, we introduce \textbf{Med-PerSAM}, a novel and straightforward one-shot framework designed for the medical domain. Med-PerSAM uses only visual prompt engineering and eliminates the need for additional training of the pretrained SAM or human intervention, owing to our novel automated prompt generation process. By integrating our lightweight warping-based prompt tuning model with SAM, we enable the extraction and iterative refinement of visual prompts, enhancing the performance of the pre-trained SAM. This advancement is particularly meaningful in the medical domain, where creating visual prompts poses notable challenges for individuals lacking medical expertise. Our model outperforms various foundational models and previous SAM-based approaches across diverse 2D medical imaging datasets.
Data-Efficient Unsupervised Interpolation Without Any Intermediate Frame for 4D Medical Images
Apr 01, 2024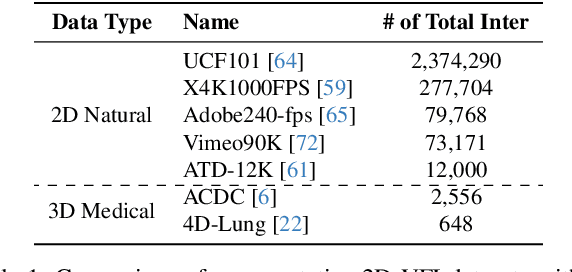
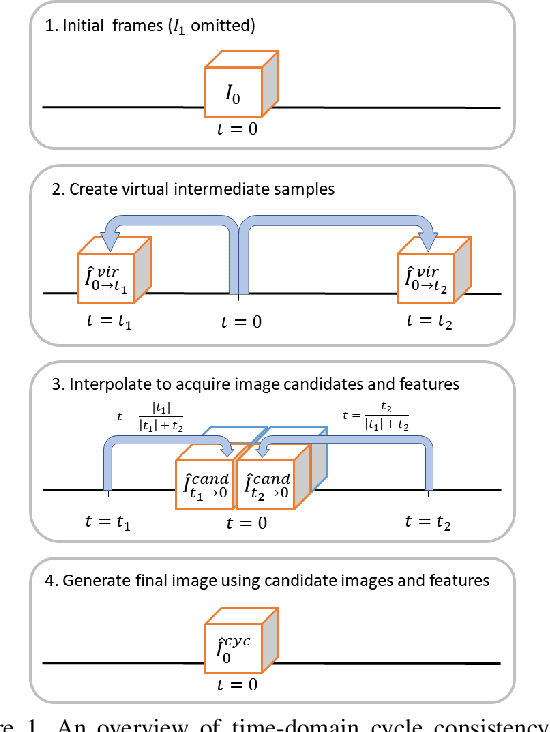


4D medical images, which represent 3D images with temporal information, are crucial in clinical practice for capturing dynamic changes and monitoring long-term disease progression. However, acquiring 4D medical images poses challenges due to factors such as radiation exposure and imaging duration, necessitating a balance between achieving high temporal resolution and minimizing adverse effects. Given these circumstances, not only is data acquisition challenging, but increasing the frame rate for each dataset also proves difficult. To address this challenge, this paper proposes a simple yet effective Unsupervised Volumetric Interpolation framework, UVI-Net. This framework facilitates temporal interpolation without the need for any intermediate frames, distinguishing it from the majority of other existing unsupervised methods. Experiments on benchmark datasets demonstrate significant improvements across diverse evaluation metrics compared to unsupervised and supervised baselines. Remarkably, our approach achieves this superior performance even when trained with a dataset as small as one, highlighting its exceptional robustness and efficiency in scenarios with sparse supervision. This positions UVI-Net as a compelling alternative for 4D medical imaging, particularly in settings where data availability is limited. The source code is available at https://github.com/jungeun122333/UVI-Net.