 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformGen: An AI Copilot for Accurate and Compliant Clinical Research Consent Document Generation
Apr 01, 2025Leveraging large language models (LLMs) to generate high-stakes documents, such as informed consent forms (ICFs), remains a significant challenge due to the extreme need for regulatory compliance and factual accuracy. Here, we present InformGen, an LLM-driven copilot for accurate and compliant ICF drafting by optimized knowledge document parsing and content generation, with humans in the loop. We further construct a benchmark dataset comprising protocols and ICFs from 900 clinical trials. Experimental results demonstrate that InformGen achieves near 100% compliance with 18 core regulatory rules derived from FDA guidelines, outperforming a vanilla GPT-4o model by up to 30%. Additionally, a user study with five annotators shows that InformGen, when integrated with manual intervention, attains over 90% factual accuracy, significantly surpassing the vanilla GPT-4o model's 57%-82%. Crucially, InformGen ensures traceability by providing inline citations to source protocols, enabling easy verification and maintaining the highest standards of factual integrity.
EHRNoteQA: A Patient-Specific Question Answering Benchmark for Evaluating Large Language Models in Clinical Settings
Feb 27, 2024
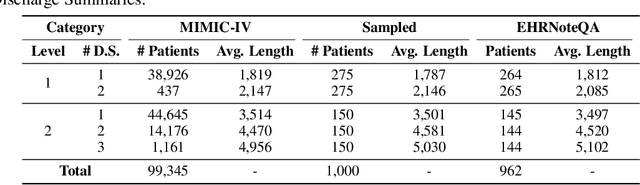


This study introduces EHRNoteQA, a novel patient-specific question answering benchmark tailored for evaluating Large Language Models (LLMs) in clinical environments. Based on MIMIC-IV Electronic Health Record (EHR), a team of three medical professionals has curated the dataset comprising 962 unique questions, each linked to a specific patient's EHR clinical notes. What makes EHRNoteQA distinct from existing EHR-based benchmarks is as follows: Firstly, it is the first dataset to adopt a multi-choice question answering format, a design choice that effectively evaluates LLMs with reliable scores in the context of automatic evaluation, compared to other formats. Secondly, it requires an analysis of multiple clinical notes to answer a single question, reflecting the complex nature of real-world clinical decision-making where clinicians review extensive records of patient histories. Our comprehensive evaluation on various large language models showed that their scores on EHRNoteQA correlate more closely with their performance in addressing real-world medical questions evaluated by clinicians than their scores from other LLM benchmarks. This underscores the significance of EHRNoteQA in evaluating LLMs for medical applications and highlights its crucial role in facilitating the integration of LLMs into healthcare systems. The dataset will be made available to the public under PhysioNet credential access, promoting further research in this vital field.
KorNAT: LLM Alignment Benchmark for Korean Social Values and Common Knowledge
Feb 22, 2024For Large Language Models (LLMs) to be effectively deployed in a specific country, they must possess an understanding of the nation's culture and basic knowledge. To this end, we introduce National Alignment, which measures an alignment between an LLM and a targeted country from two aspects: social value alignment and common knowledge alignment. Social value alignment evaluates how well the model understands nation-specific social values, while common knowledge alignment examines how well the model captures basic knowledge related to the nation. We constructed KorNAT, the first benchmark that measures national alignment with South Korea. For the social value dataset, we obtained ground truth labels from a large-scale survey involving 6,174 unique Korean participants. For the common knowledge dataset, we constructed samples based on Korean textbooks and GED reference materials. KorNAT contains 4K and 6K multiple-choice questions for social value and common knowledge, respectively. Our dataset creation process is meticulously designed and based on statistical sampling theory and was refined through multiple rounds of human review. The experiment results of seven LLMs reveal that only a few models met our reference score, indicating a potential for further enhancement. KorNAT has received government approval after passing an assessment conducted by a government-affiliated organization dedicated to evaluating dataset quality. Samples and detailed evaluation protocols of our dataset can be found in https://selectstar.ai/ko/papers-national-alignment
VisAlign: Dataset for Measuring the Degree of Alignment between AI and Humans in Visual Perception
Aug 03, 2023



AI alignment refers to models acting towards human-intended goals, preferences, or ethical principles. Given that most large-scale deep learning models act as black boxes and cannot be manually controlled, analyzing the similarity between models and humans can be a proxy measure for ensuring AI safety. In this paper, we focus on the models' visual perception alignment with humans, further referred to as AI-human visual alignment. Specifically, we propose a new dataset for measuring AI-human visual alignment in terms of image classification, a fundamental task in machine perception. In order to evaluate AI-human visual alignment, a dataset should encompass samples with various scenarios that may arise in the real world and have gold human perception labels. Our dataset consists of three groups of samples, namely Must-Act (i.e., Must-Classify), Must-Abstain, and Uncertain, based on the quantity and clarity of visual information in an image and further divided into eight categories. All samples have a gold human perception label; even Uncertain (severely blurry) sample labels were obtained via crowd-sourcing. The validity of our dataset is verified by sampling theory, statistical theories related to survey design, and experts in the related fields. Using our dataset, we analyze the visual alignment and reliability of five popular visual perception models and seven abstention methods. Our code and data is available at \url{https://github.com/jiyounglee-0523/VisAlign}.