 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Multi-Table Time Series EHR from Latent Space with Minimal Preprocessing
Jul 09, 2025Electronic Health Records (EHR) are time-series relational databases that record patient interactions and medical events over time, serving as a critical resource for healthcare research and applications. However, privacy concerns and regulatory restrictions limit the sharing and utilization of such sensitive data, necessitating the generation of synthetic EHR datasets. Unlike previous EHR synthesis methods, which typically generate medical records consisting of expert-chosen features (e.g. a few vital signs or structured codes only), we introduce RawMed, the first framework to synthesize multi-table, time-series EHR data that closely resembles raw EHRs. Using text-based representation and compression techniques, RawMed captures complex structures and temporal dynamics with minimal preprocessing. We also propose a new evaluation framework for multi-table time-series synthetic EHRs, assessing distributional similarity, inter-table relationships, temporal dynamics, and privacy. Validated on two open-source EHR datasets, RawMed outperforms baseline models in fidelity and utility. The code is available at https://github.com/eunbyeol-cho/RawMed.
Lunguage: A Benchmark for Structured and Sequential Chest X-ray Interpretation
May 27, 2025Radiology reports convey detailed clinical observations and capture diagnostic reasoning that evolves over time. However, existing evaluation methods are limited to single-report settings and rely on coarse metrics that fail to capture fine-grained clinical semantics and temporal dependencies. We introduce LUNGUAGE,a benchmark dataset for structured radiology report generation that supports both single-report evaluation and longitudinal patient-level assessment across multiple studies. It contains 1,473 annotated chest X-ray reports, each reviewed by experts, and 80 of them contain longitudinal annotations to capture disease progression and inter-study intervals, also reviewed by experts. Using this benchmark, we develop a two-stage framework that transforms generated reports into fine-grained, schema-aligned structured representations, enabling longitudinal interpretation. We also propose LUNGUAGESCORE, an interpretable metric that compares structured outputs at the entity, relation, and attribute level while modeling temporal consistency across patient timelines. These contributions establish the first benchmark dataset, structuring framework, and evaluation metric for sequential radiology reporting, with empirical results demonstrating that LUNGUAGESCORE effectively supports structured report evaluation. The code is available at: https://github.com/SuperSupermoon/Lunguage
EHRFL: Federated Learning Framework for Heterogeneous EHRs and Precision-guided Selection of Participating Clients
Apr 20, 2024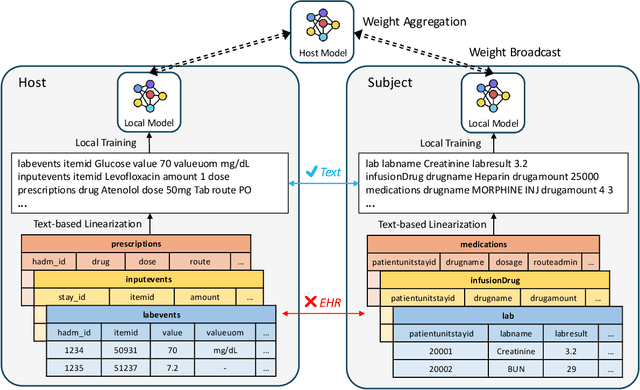
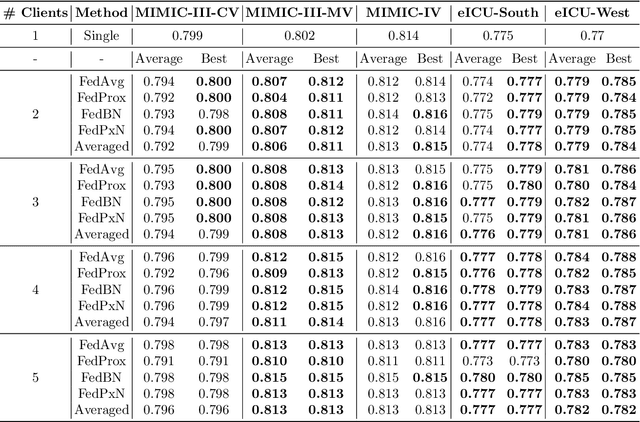
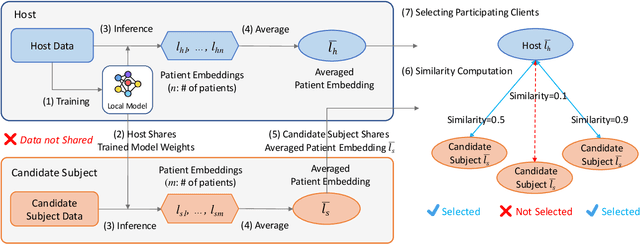
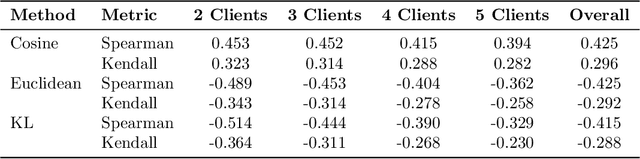
In this study, we provide solutions to two practical yet overlooked scenarios in federated learning for electronic health records (EHRs): firstly, we introduce EHRFL, a framework that facilitates federated learning across healthcare institutions with distinct medical coding systems and database schemas using text-based linearization of EHRs. Secondly, we focus on a scenario where a single healthcare institution initiates federated learning to build a model tailored for itself, in which the number of clients must be optimized in order to reduce expenses incurred by the host. For selecting participating clients, we present a novel precision-based method, leveraging data latents to identify suitable participants for the institution. Our empirical results show that EHRFL effectively enables federated learning across hospitals with different EHR systems. Furthermore, our results demonstrate the efficacy of our precision-based method in selecting reduced number of participating clients without compromising model performance, resulting in lower operational costs when constructing institution-specific models. We believe this work lays a foundation for the broader adoption of federated learning on EHRs.
EHRNoteQA: A Patient-Specific Question Answering Benchmark for Evaluating Large Language Models in Clinical Settings
Feb 27, 2024
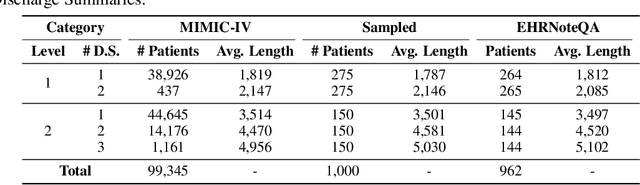


This study introduces EHRNoteQA, a novel patient-specific question answering benchmark tailored for evaluating Large Language Models (LLMs) in clinical environments. Based on MIMIC-IV Electronic Health Record (EHR), a team of three medical professionals has curated the dataset comprising 962 unique questions, each linked to a specific patient's EHR clinical notes. What makes EHRNoteQA distinct from existing EHR-based benchmarks is as follows: Firstly, it is the first dataset to adopt a multi-choice question answering format, a design choice that effectively evaluates LLMs with reliable scores in the context of automatic evaluation, compared to other formats. Secondly, it requires an analysis of multiple clinical notes to answer a single question, reflecting the complex nature of real-world clinical decision-making where clinicians review extensive records of patient histories. Our comprehensive evaluation on various large language models showed that their scores on EHRNoteQA correlate more closely with their performance in addressing real-world medical questions evaluated by clinicians than their scores from other LLM benchmarks. This underscores the significance of EHRNoteQA in evaluating LLMs for medical applications and highlights its crucial role in facilitating the integration of LLMs into healthcare systems. The dataset will be made available to the public under PhysioNet credential access, promoting further research in this vital field.
Publicly Shareable Clinical Large Language Model Built on Synthetic Clinical Notes
Sep 06, 2023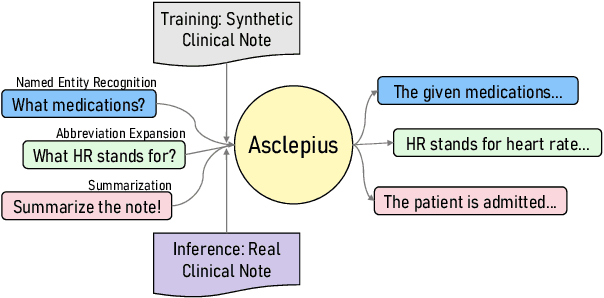
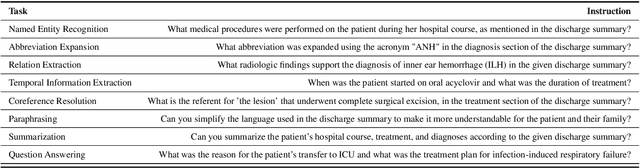
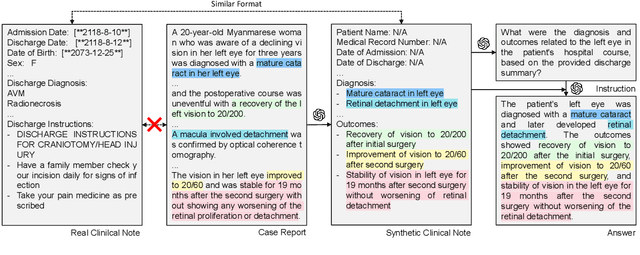
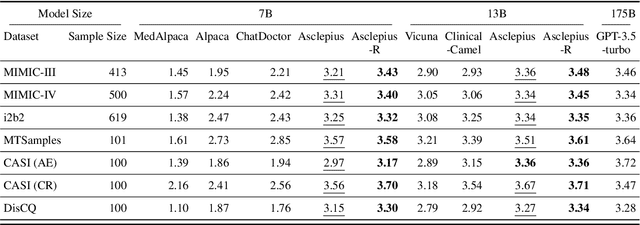
The development of large language models tailored for handling patients' clinical notes is often hindered by the limited accessibility and usability of these notes due to strict privacy regulations. To address these challenges, we first create synthetic large-scale clinical notes using publicly available case reports extracted from biomedical literature. We then use these synthetic notes to train our specialized clinical large language model, Asclepius. While Asclepius is trained on synthetic data, we assess its potential performance in real-world applications by evaluating it using real clinical notes. We benchmark Asclepius against several other large language models, including GPT-3.5-turbo and other open-source alternatives. To further validate our approach using synthetic notes, we also compare Asclepius with its variants trained on real clinical notes. Our findings convincingly demonstrate that synthetic clinical notes can serve as viable substitutes for real ones when constructing high-performing clinical language models. This conclusion is supported by detailed evaluations conducted by both GPT-4 and medical professionals. All resources including weights, codes, and data used in the development of Asclepius are made publicly accessible for future research.
Rediscovery of CNN's Versatility for Text-based Encoding of Raw Electronic Health Records
Mar 15, 2023Making the most use of abundant information in electronic health records (EHR) is rapidly becoming an important topic in the medical domain. Recent work presented a promising framework that embeds entire features in raw EHR data regardless of its form and medical code standards. The framework, however, only focuses on encoding EHR with minimal preprocessing and fails to consider how to learn efficient EHR representation in terms of computation and memory usage. In this paper, we search for a versatile encoder not only reducing the large data into a manageable size but also well preserving the core information of patients to perform diverse clinical tasks. We found that hierarchically structured Convolutional Neural Network (CNN) often outperforms the state-of-the-art model on diverse tasks such as reconstruction, prediction, and generation, even with fewer parameters and less training time. Moreover, it turns out that making use of the inherent hierarchy of EHR data can boost the performance of any kind of backbone models and clinical tasks performed. Through extensive experiments, we present concrete evidence to generalize our research findings into real-world practice. We give a clear guideline on building the encoder based on the research findings captured while exploring numerous settings.
UniHPF : Universal Healthcare Predictive Framework with Zero Domain Knowledge
Nov 15, 2022
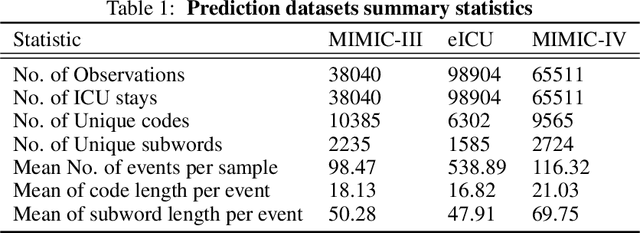


Despite the abundance of Electronic Healthcare Records (EHR), its heterogeneity restricts the utilization of medical data in building predictive models. To address this challenge, we propose Universal Healthcare Predictive Framework (UniHPF), which requires no medical domain knowledge and minimal pre-processing for multiple prediction tasks. Experimental results demonstrate that UniHPF is capable of building large-scale EHR models that can process any form of medical data from distinct EHR systems. We believe that our findings can provide helpful insights for further research on the multi-source learning of EHRs.