 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Multi-Table Time Series EHR from Latent Space with Minimal Preprocessing
Jul 09, 2025Electronic Health Records (EHR) are time-series relational databases that record patient interactions and medical events over time, serving as a critical resource for healthcare research and applications. However, privacy concerns and regulatory restrictions limit the sharing and utilization of such sensitive data, necessitating the generation of synthetic EHR datasets. Unlike previous EHR synthesis methods, which typically generate medical records consisting of expert-chosen features (e.g. a few vital signs or structured codes only), we introduce RawMed, the first framework to synthesize multi-table, time-series EHR data that closely resembles raw EHRs. Using text-based representation and compression techniques, RawMed captures complex structures and temporal dynamics with minimal preprocessing. We also propose a new evaluation framework for multi-table time-series synthetic EHRs, assessing distributional similarity, inter-table relationships, temporal dynamics, and privacy. Validated on two open-source EHR datasets, RawMed outperforms baseline models in fidelity and utility. The code is available at https://github.com/eunbyeol-cho/RawMed.
DialSim: A Real-Time Simulator for Evaluating Long-Term Dialogue Understanding of Conversational Agents
Jun 19, 2024



Recent advancements in Large Language Models (LLMs) have significantly enhanced the capabilities of conversational agents, making them applicable to various fields (e.g., education). Despite their progress, the evaluation of the agents often overlooks the complexities of real-world conversations, such as real-time interactions, multi-party dialogues, and extended contextual dependencies. To bridge this gap, we introduce DialSim, a real-time dialogue simulator. In this simulator, an agent is assigned the role of a character from popular TV shows, requiring it to respond to spontaneous questions using past dialogue information and to distinguish between known and unknown information. Key features of DialSim include evaluating the agent's ability to respond within a reasonable time limit, handling long-term multi-party dialogues, and managing adversarial settings (e.g., swap character names) to challenge the agent's reliance on pre-trained knowledge. We utilized this simulator to evaluate the latest conversational agents and analyze their limitations. Our experiments highlight both the strengths and weaknesses of these agents, providing valuable insights for future improvements in the field of conversational AI. DialSim is available at https://github.com/jiho283/Simulator.
EHRXQA: A Multi-Modal Question Answering Dataset for Electronic Health Records with Chest X-ray Images
Oct 28, 2023



Electronic Health Records (EHRs), which contain patients' medical histories in various multi-modal formats, often overlook the potential for joint reasoning across imaging and table modalities underexplored in current EHR Question Answering (QA) systems. In this paper, we introduce EHRXQA, a novel multi-modal question answering dataset combining structured EHRs and chest X-ray images. To develop our dataset, we first construct two uni-modal resources: 1) The MIMIC- CXR-VQA dataset, our newly created medical visual question answering (VQA) benchmark, specifically designed to augment the imaging modality in EHR QA, and 2) EHRSQL (MIMIC-IV), a refashioned version of a previously established table-based EHR QA dataset. By integrating these two uni-modal resources, we successfully construct a multi-modal EHR QA dataset that necessitates both uni-modal and cross-modal reasoning. To address the unique challenges of multi-modal questions within EHRs, we propose a NeuralSQL-based strategy equipped with an external VQA API. This pioneering endeavor enhances engagement with multi-modal EHR sources and we believe that our dataset can catalyze advances in real-world medical scenarios such as clinical decision-making and research. EHRXQA is available at https://github.com/baeseongsu/ehrxqa.
Publicly Shareable Clinical Large Language Model Built on Synthetic Clinical Notes
Sep 06, 2023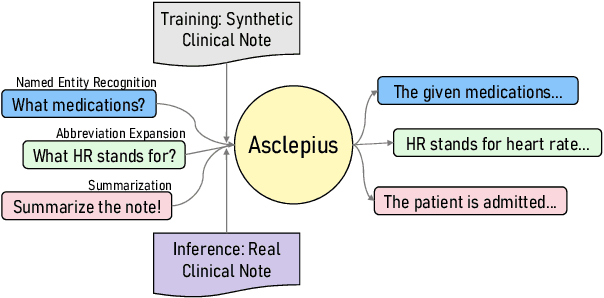
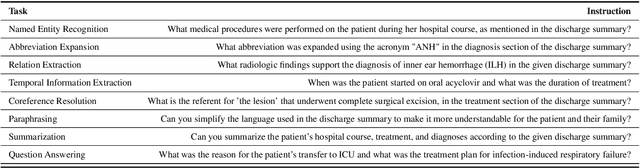
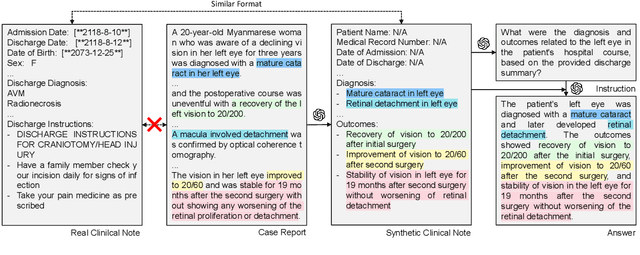
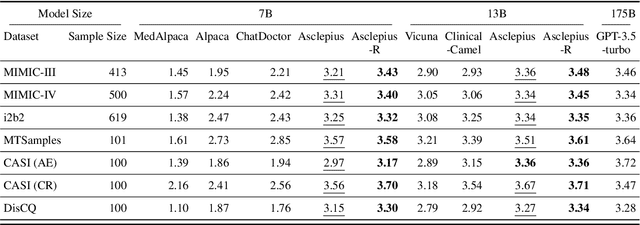
The development of large language models tailored for handling patients' clinical notes is often hindered by the limited accessibility and usability of these notes due to strict privacy regulations. To address these challenges, we first create synthetic large-scale clinical notes using publicly available case reports extracted from biomedical literature. We then use these synthetic notes to train our specialized clinical large language model, Asclepius. While Asclepius is trained on synthetic data, we assess its potential performance in real-world applications by evaluating it using real clinical notes. We benchmark Asclepius against several other large language models, including GPT-3.5-turbo and other open-source alternatives. To further validate our approach using synthetic notes, we also compare Asclepius with its variants trained on real clinical notes. Our findings convincingly demonstrate that synthetic clinical notes can serve as viable substitutes for real ones when constructing high-performing clinical language models. This conclusion is supported by detailed evaluations conducted by both GPT-4 and medical professionals. All resources including weights, codes, and data used in the development of Asclepius are made publicly accessible for future research.
Rediscovery of CNN's Versatility for Text-based Encoding of Raw Electronic Health Records
Mar 15, 2023Making the most use of abundant information in electronic health records (EHR) is rapidly becoming an important topic in the medical domain. Recent work presented a promising framework that embeds entire features in raw EHR data regardless of its form and medical code standards. The framework, however, only focuses on encoding EHR with minimal preprocessing and fails to consider how to learn efficient EHR representation in terms of computation and memory usage. In this paper, we search for a versatile encoder not only reducing the large data into a manageable size but also well preserving the core information of patients to perform diverse clinical tasks. We found that hierarchically structured Convolutional Neural Network (CNN) often outperforms the state-of-the-art model on diverse tasks such as reconstruction, prediction, and generation, even with fewer parameters and less training time. Moreover, it turns out that making use of the inherent hierarchy of EHR data can boost the performance of any kind of backbone models and clinical tasks performed. Through extensive experiments, we present concrete evidence to generalize our research findings into real-world practice. We give a clear guideline on building the encoder based on the research findings captured while exploring numerous settings.
UniHPF : Universal Healthcare Predictive Framework with Zero Domain Knowledge
Nov 15, 2022
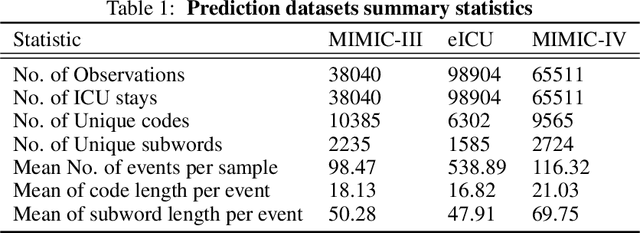


Despite the abundance of Electronic Healthcare Records (EHR), its heterogeneity restricts the utilization of medical data in building predictive models. To address this challenge, we propose Universal Healthcare Predictive Framework (UniHPF), which requires no medical domain knowledge and minimal pre-processing for multiple prediction tasks. Experimental results demonstrate that UniHPF is capable of building large-scale EHR models that can process any form of medical data from distinct EHR systems. We believe that our findings can provide helpful insights for further research on the multi-source learning of EHRs.