 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECG-Reasoning-Benchmark: A Benchmark for Evaluating Clinical Reasoning Capabilities in ECG Interpretation
Mar 15, 2026While Multimodal Large Language Models (MLLMs) show promising performance in automated electrocardiogram interpretation, it remains unclear whether they genuinely perform actual step-by-step reasoning or just rely on superficial visual cues. To investigate this, we introduce \textbf{ECG-Reasoning-Benchmark}, a novel multi-turn evaluation framework comprising over 6,400 samples to systematically assess step-by-step reasoning across 17 core ECG diagnoses. Our comprehensive evaluation of state-of-the-art models reveals a critical failure in executing multi-step logical deduction. Although models possess the medical knowledge to retrieve clinical criteria for a diagnosis, they exhibit near-zero success rates (6% Completion) in maintaining a complete reasoning chain, primarily failing to ground the corresponding ECG findings to the actual visual evidence in the ECG signal. These results demonstrate that current MLLMs bypass actual visual interpretation, exposing a critical flaw in existing training paradigms and underscoring the necessity for robust, reasoning-centric medical AI. The code and data are available at https://github.com/Jwoo5/ecg-reasoning-benchmark.
ECG-Agent: On-Device Tool-Calling Agent for ECG Multi-Turn Dialogue
Jan 28, 2026Recent advances in Multimodal Large Language Models have rapidly expanded to electrocardiograms, focusing on classification, report generation, and single-turn QA tasks. However, these models fall short in real-world scenarios, lacking multi-turn conversational ability, on-device efficiency, and precise understanding of ECG measurements such as the PQRST intervals. To address these limitations, we introduce ECG-Agent, the first LLM-based tool-calling agent for multi-turn ECG dialogue. To facilitate its development and evaluation, we also present ECG-Multi-Turn-Dialogue (ECG-MTD) dataset, a collection of realistic user-assistant multi-turn dialogues for diverse ECG lead configurations. We develop ECG-Agents in various sizes, from on-device capable to larger agents. Experimental results show that ECG-Agents outperform baseline ECG-LLMs in response accuracy. Furthermore, on-device agents achieve comparable performance to larger agents in various evaluations that assess response accuracy, tool-calling ability, and hallucinations, demonstrating their viability for real-world applications.
PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions
May 23, 2025
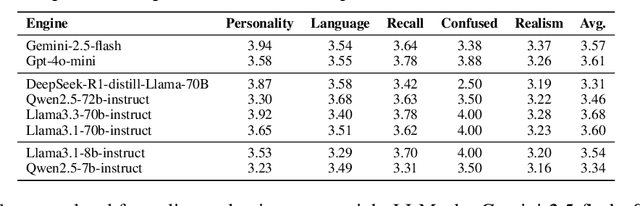
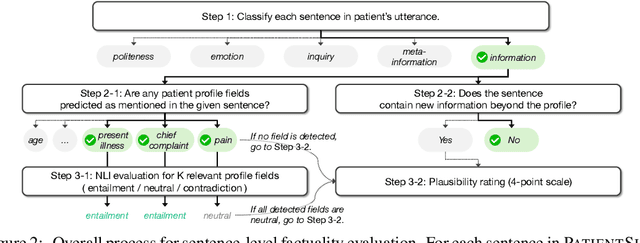
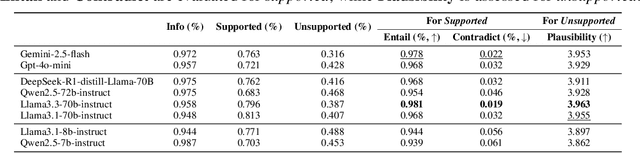
Doctor-patient consultations require multi-turn, context-aware communication tailored to diverse patient personas. Training or evaluating doctor LLMs in such settings requires realistic patient interaction systems. However, existing simulators often fail to reflect the full range of personas seen in clinical practice. To address this, we introduce PatientSim, a patient simulator that generates realistic and diverse patient personas for clinical scenarios, grounded in medical expertise. PatientSim operates using: 1) clinical profiles, including symptoms and medical history, derived from real-world data in the MIMIC-ED and MIMIC-IV datasets, and 2) personas defined by four axes: personality, language proficiency, medical history recall level, and cognitive confusion level, resulting in 37 unique combinations. We evaluated eight LLMs for factual accuracy and persona consistency. The top-performing open-source model, Llama 3.3, was validated by four clinicians to confirm the robustness of our framework. As an open-source, customizable platform, PatientSim provides a reproducible and scalable solution that can be customized for specific training needs. Offering a privacy-compliant environment, it serves as a robust testbed for evaluating medical dialogue systems across diverse patient presentations and shows promise as an educational tool for healthcare.
Time is Not Enough: Time-Frequency based Explanation for Time-Series Black-Box Models
Aug 07, 2024



Despite the massive attention given to time-series explanations due to their extensive applications, a notable limitation in existing approaches is their primary reliance on the time-domain. This overlooks the inherent characteristic of time-series data containing both time and frequency features. In this work, we present Spectral eXplanation (SpectralX), an XAI framework that provides time-frequency explanations for time-series black-box classifiers. This easily adaptable framework enables users to "plug-in" various perturbation-based XAI methods for any pre-trained time-series classification models to assess their impact on the explanation quality without having to modify the framework architecture. Additionally, we introduce Feature Importance Approximations (FIA), a new perturbation-based XAI method. These methods consist of feature insertion, deletion, and combination techniques to enhance computational efficiency and class-specific explanations in time-series classification tasks. We conduct extensive experiments in the generated synthetic dataset and various UCR Time-Series datasets to first compare the explanation performance of FIA and other existing perturbation-based XAI methods in both time-domain and time-frequency domain, and then show the superiority of our FIA in the time-frequency domain with the SpectralX framework. Finally, we conduct a user study to confirm the practicality of our FIA in SpectralX framework for class-specific time-frequency based time-series explanations. The source code is available in https://github.com/gustmd0121/Time_is_not_Enough
DialSim: A Real-Time Simulator for Evaluating Long-Term Dialogue Understanding of Conversational Agents
Jun 19, 2024



Recent advancements in Large Language Models (LLMs) have significantly enhanced the capabilities of conversational agents, making them applicable to various fields (e.g., education). Despite their progress, the evaluation of the agents often overlooks the complexities of real-world conversations, such as real-time interactions, multi-party dialogues, and extended contextual dependencies. To bridge this gap, we introduce DialSim, a real-time dialogue simulator. In this simulator, an agent is assigned the role of a character from popular TV shows, requiring it to respond to spontaneous questions using past dialogue information and to distinguish between known and unknown information. Key features of DialSim include evaluating the agent's ability to respond within a reasonable time limit, handling long-term multi-party dialogues, and managing adversarial settings (e.g., swap character names) to challenge the agent's reliance on pre-trained knowledge. We utilized this simulator to evaluate the latest conversational agents and analyze their limitations. Our experiments highlight both the strengths and weaknesses of these agents, providing valuable insights for future improvements in the field of conversational AI. DialSim is available at https://github.com/jiho283/Simulator.
Text-to-ECG: 12-Lead Electrocardiogram Synthesis conditioned on Clinical Text Reports
Mar 09, 2023



Electrocardiogram (ECG) synthesis is the area of research focused on generating realistic synthetic ECG signals for medical use without concerns over annotation costs or clinical data privacy restrictions. Traditional ECG generation models consider a single ECG lead and utilize GAN-based generative models. These models can only generate single lead samples and require separate training for each diagnosis class. The diagnosis classes of ECGs are insufficient to capture the intricate differences between ECGs depending on various features (e.g. patient demographic details, co-existing diagnosis classes, etc.). To alleviate these challenges, we present a text-to-ECG task, in which textual inputs are used to produce ECG outputs. Then we propose Auto-TTE, an autoregressive generative model conditioned on clinical text reports to synthesize 12-lead ECGs, for the first time to our knowledge. We compare the performance of our model with other representative models in text-to-speech and text-to-image. Experimental results show the superiority of our model in various quantitative evaluations and qualitative analysis. Finally, we conduct a user study with three board-certified cardiologists to confirm the fidelity and semantic alignment of generated samples. our code will be available at https://github.com/TClife/text_to_ecg
Lead-agnostic Self-supervised Learning for Local and Global Representations of Electrocardiogram
Mar 18, 2022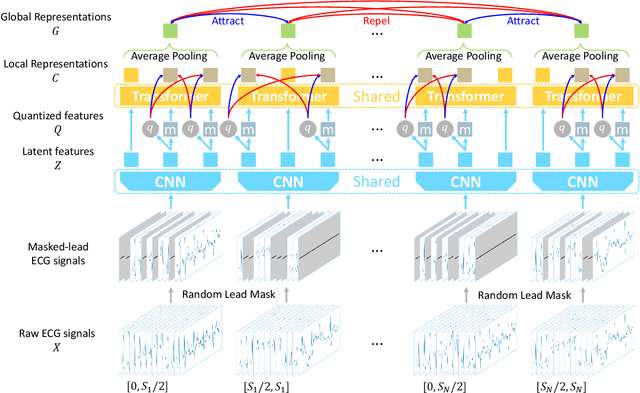
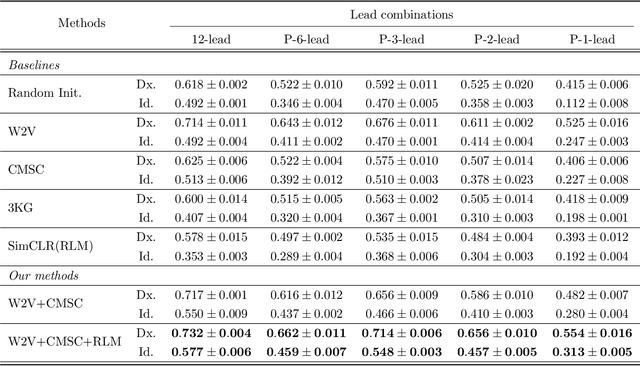
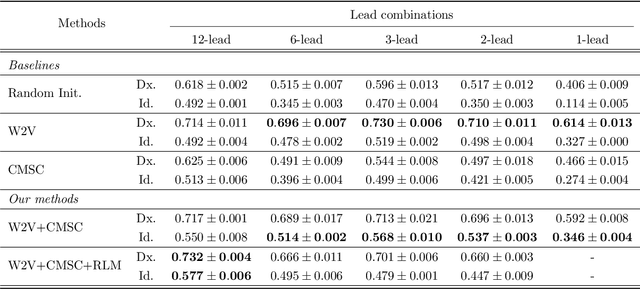
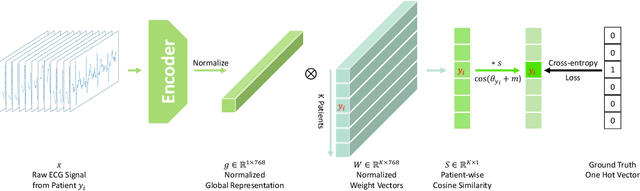
In recent years, self-supervised learning methods have shown significant improvement for pre-training with unlabeled data and have proven helpful for electrocardiogram signals. However, most previous pre-training methods for electrocardiogram focused on capturing only global contextual representations. This inhibits the models from learning fruitful representation of electrocardiogram, which results in poor performance on downstream tasks. Additionally, they cannot fine-tune the model with an arbitrary set of electrocardiogram leads unless the models were pre-trained on the same set of leads. In this work, we propose an ECG pre-training method that learns both local and global contextual representations for better generalizability and performance on downstream tasks. In addition, we propose random lead masking as an ECG-specific augmentation method to make our proposed model robust to an arbitrary set of leads. Experimental results on two downstream tasks, cardiac arrhythmia classification and patient identification, show that our proposed approach outperforms other state-of-the-art methods.
Reinforce-Aligner: Reinforcement Alignment Search for Robust End-to-End Text-to-Speech
Jun 05, 2021



Text-to-speech (TTS) synthesis is the process of producing synthesized speech from text or phoneme input. Traditional TTS models contain multiple processing steps and require external aligners, which provide attention alignments of phoneme-to-frame sequences. As the complexity increases and efficiency decreases with every additional step, there is expanding demand in modern synthesis pipelines for end-to-end TTS with efficient internal aligners. In this work, we propose an end-to-end text-to-waveform network with a novel reinforcement learning based duration search method. Our proposed generator is feed-forward and the aligner trains the agent to make optimal duration predictions by receiving active feedback from actions taken to maximize cumulative reward. We demonstrate accurate alignments of phoneme-to-frame sequence generated from trained agents enhance fidelity and naturalness of synthesized audio. Experimental results also show the superiority of our proposed model compared to other state-of-the-art TTS models with internal and external aligners.
Rotation Invariant Aerial Image Retrieval with Group Convolutional Metric Learning
Oct 19, 2020
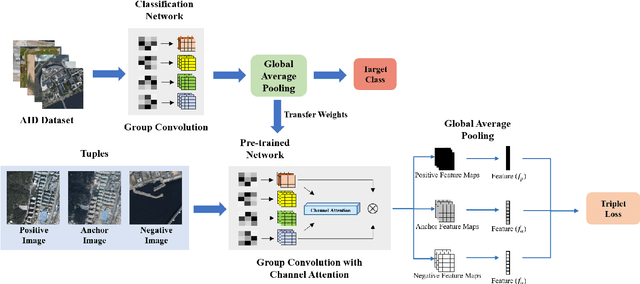

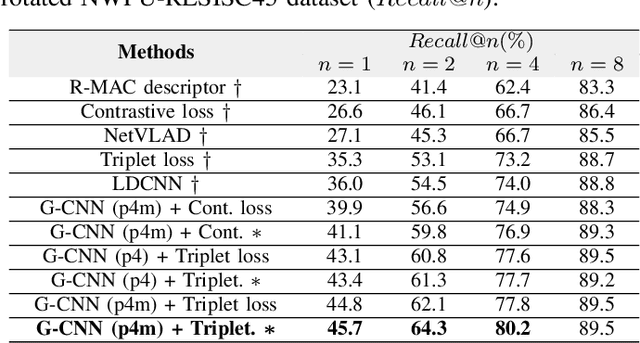
Remote sensing image retrieval (RSIR) is the process of ranking database images depending on the degree of similarity compared to the query image. As the complexity of RSIR increases due to the diversity in shooting range, angle, and location of remote sensors, there is an increasing demand for methods to address these issues and improve retrieval performance. In this work, we introduce a novel method for retrieving aerial images by merging group convolution with attention mechanism and metric learning, resulting in robustness to rotational variations. For refinement and emphasis on important features, we applied channel attention in each group convolution stage. By utilizing the characteristics of group convolution and channel-wise attention, it is possible to acknowledge the equality among rotated but identically located images. The training procedure has two main steps: (i) training the network with Aerial Image Dataset (AID) for classification, (ii) fine-tuning the network with triplet-loss for retrieval with Google Earth South Korea and NWPU-RESISC45 datasets. Results show that the proposed method performance exceeds other state-of-the-art retrieval methods in both rotated and original environments. Furthermore, we utilize class activation maps (CAM) to visualize the distinct difference of main features between our method and baseline, resulting in better adaptability in rotated environments.