 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSCAR: Optical-aware Semantic Control for Aleatoric Refinement in Sar-to-Optical Translation
Jan 11, 2026Synthetic Aperture Radar (SAR) provides robust all-weather imaging capabilities; however, translating SAR observations into photo-realistic optical images remains a fundamentally ill-posed problem. Current approaches are often hindered by the inherent speckle noise and geometric distortions of SAR data, which frequently result in semantic misinterpretation, ambiguous texture synthesis, and structural hallucinations. To address these limitations, a novel SAR-to-Optical (S2O) translation framework is proposed, integrating three core technical contributions: (i) Cross-Modal Semantic Alignment, which establishes an Optical-Aware SAR Encoder by distilling robust semantic priors from an Optical Teacher into a SAR Student (ii) Semantically-Grounded Generative Guidance, realized by a Semantically-Grounded ControlNet that integrates class-aware text prompts for global context with hierarchical visual prompts for local spatial guidance; and (iii) an Uncertainty-Aware Objective, which explicitly models aleatoric uncertainty to dynamically modulate the reconstruction focus, effectively mitigating artifacts caused by speckle-induced ambiguity. Extensive experiments demonstrate that the proposed method achieves superior perceptual quality and semantic consistency compared to state-of-the-art approaches.
Appearance Debiased Gaze Estimation via Stochastic Subject-Wise Adversarial Learning
Jan 25, 2024



Recently, appearance-based gaze estimation has been attracting attention in computer vision, and remarkable improvements have been achieved using various deep learning techniques. Despite such progress, most methods aim to infer gaze vectors from images directly, which causes overfitting to person-specific appearance factors. In this paper, we address these challenges and propose a novel framework: Stochastic subject-wise Adversarial gaZE learning (SAZE), which trains a network to generalize the appearance of subjects. We design a Face generalization Network (Fgen-Net) using a face-to-gaze encoder and face identity classifier and a proposed adversarial loss. The proposed loss generalizes face appearance factors so that the identity classifier inferences a uniform probability distribution. In addition, the Fgen-Net is trained by a learning mechanism that optimizes the network by reselecting a subset of subjects at every training step to avoid overfitting. Our experimental results verify the robustness of the method in that it yields state-of-the-art performance, achieving 3.89 and 4.42 on the MPIIGaze and EyeDiap datasets, respectively. Furthermore, we demonstrate the positive generalization effect by conducting further experiments using face images involving different styles generated from the generative model.
Towards Better Visualizing the Decision Basis of Networks via Unfold and Conquer Attribution Guidance
Dec 21, 2023Revealing the transparency of Deep Neural Networks (DNNs) has been widely studied to describe the decision mechanisms of network inner structures. In this paper, we propose a novel post-hoc framework, Unfold and Conquer Attribution Guidance (UCAG), which enhances the explainability of the network decision by spatially scrutinizing the input features with respect to the model confidence. Addressing the phenomenon of missing detailed descriptions, UCAG sequentially complies with the confidence of slices of the image, leading to providing an abundant and clear interpretation. Therefore, it is possible to enhance the representation ability of explanation by preserving the detailed descriptions of assistant input features, which are commonly overwhelmed by the main meaningful regions. We conduct numerous evaluations to validate the performance in several metrics: i) deletion and insertion, ii) (energy-based) pointing games, and iii) positive and negative density maps. Experimental results, including qualitative comparisons, demonstrate that our method outperforms the existing methods with the nature of clear and detailed explanations and applicability.
Multi-Contextual Predictions with Vision Transformer for Video Anomaly Detection
Jun 17, 2022
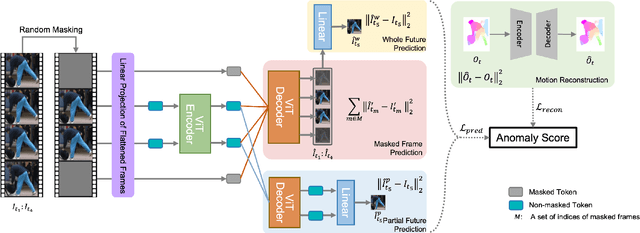

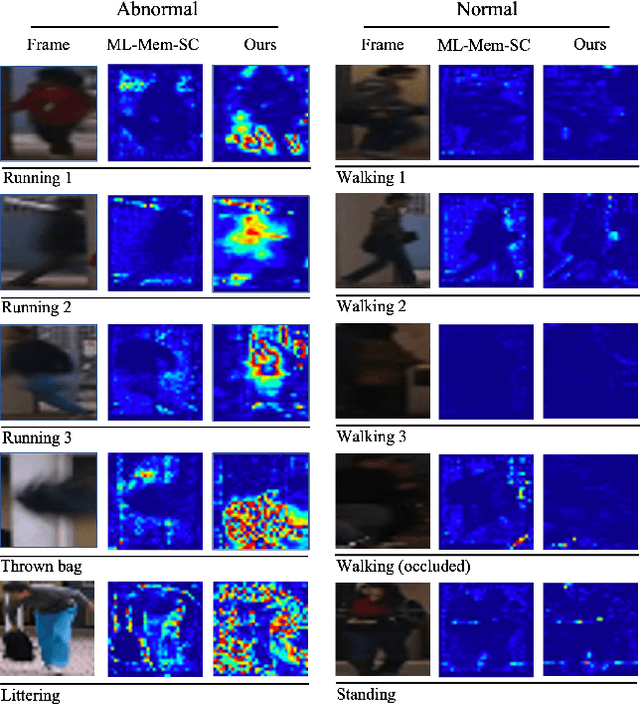
Video Anomaly Detection(VAD) has been traditionally tackled in two main methodologies: the reconstruction-based approach and the prediction-based one. As the reconstruction-based methods learn to generalize the input image, the model merely learns an identity function and strongly causes the problem called generalizing issue. On the other hand, since the prediction-based ones learn to predict a future frame given several previous frames, they are less sensitive to the generalizing issue. However, it is still uncertain if the model can learn the spatio-temporal context of a video. Our intuition is that the understanding of the spatio-temporal context of a video plays a vital role in VAD as it provides precise information on how the appearance of an event in a video clip changes. Hence, to fully exploit the context information for anomaly detection in video circumstances, we designed the transformer model with three different contextual prediction streams: masked, whole and partial. By learning to predict the missing frames of consecutive normal frames, our model can effectively learn various normality patterns in the video, which leads to a high reconstruction error at the abnormal cases that are unsuitable to the learned context. To verify the effectiveness of our approach, we assess our model on the public benchmark datasets: USCD Pedestrian 2, CUHK Avenue and ShanghaiTech and evaluate the performance with the anomaly score metric of reconstruction error. The results demonstrate that our proposed approach achieves a competitive performance compared to the existing video anomaly detection methods.
Gradient Hedging for Intensively Exploring Salient Interpretation beyond Neuron Activation
May 23, 2022
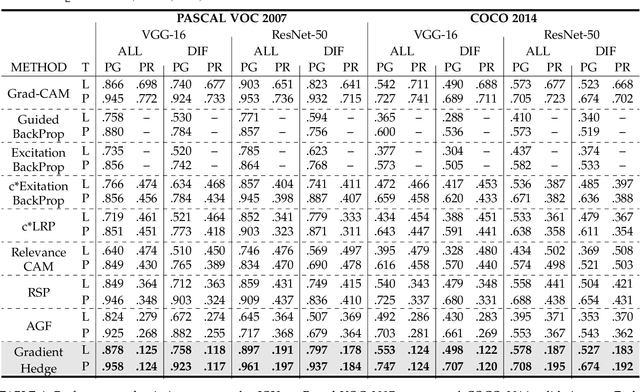
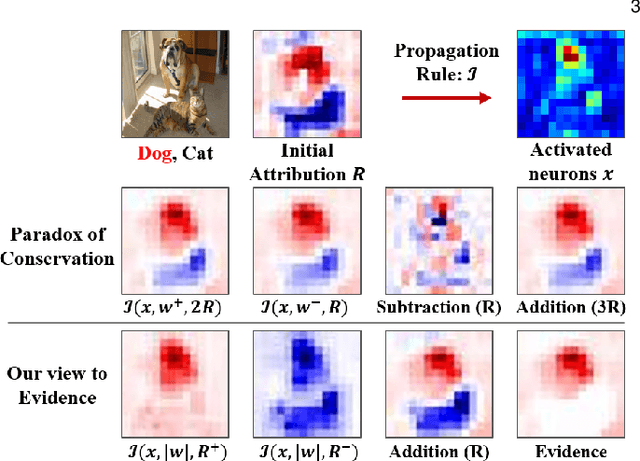
Hedging is a strategy for reducing the potential risks in various types of investments by adopting an opposite position in a related asset. Motivated by the equity technique, we introduce a method for decomposing output predictions into intensive salient attributions by hedging the evidence for a decision. We analyze the conventional approach applied to the evidence for a decision and discuss the paradox of the conservation rule. Subsequently, we define the viewpoint of evidence as a gap of positive and negative influence among the gradient-derived initial contribution maps and propagate the antagonistic elements to the evidence as suppressors, following the criterion of the degree of positive attribution defined by user preference. In addition, we reflect the severance or sparseness contribution of inactivated neurons, which are mostly irrelevant to a decision, resulting in increased robustness to interpretability. We conduct the following assessments in a verified experimental environment: pointing game, most relevant first region insertion, outside-inside relevance ratio, and mean average precision on the PASCAL VOC 2007, MS COCO 2014, and ImageNet datasets. The results demonstrate that our method outperforms existing attribution methods in distinctive, intensive, and intuitive visualization with robustness and applicability in general models.
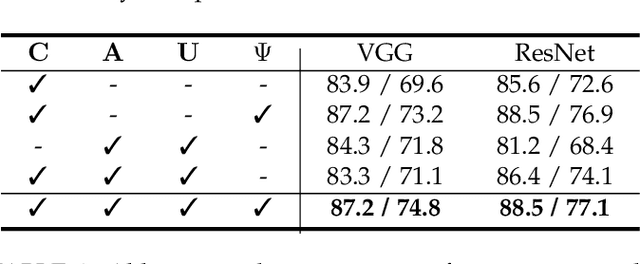
Few-Shot Object Detection with Proposal Balance Refinement
Apr 22, 2022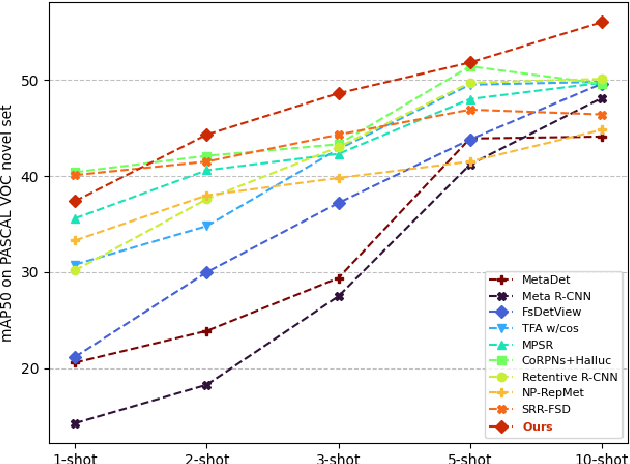
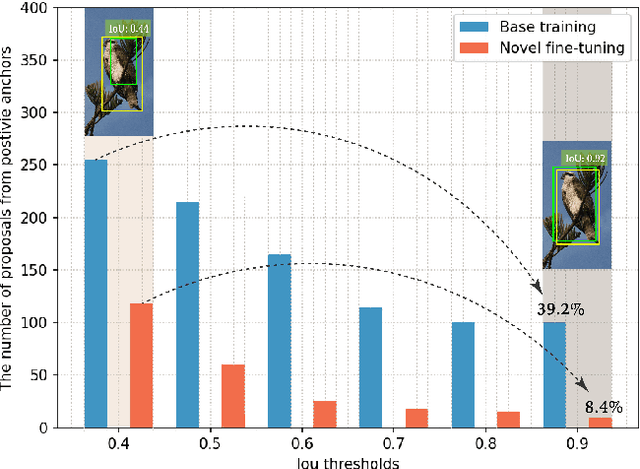
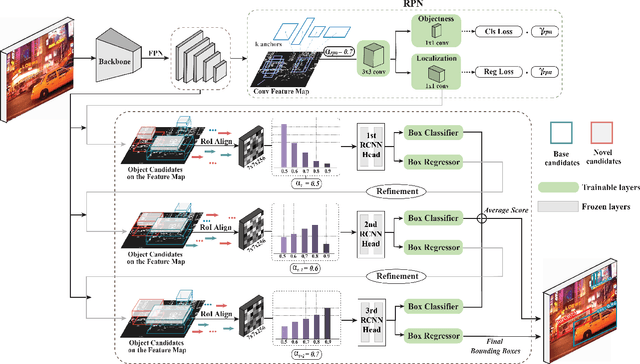

Few-shot object detection has gained significant attention in recent years as it has the potential to greatly reduce the reliance on large amounts of manually annotated bounding boxes. While most existing few-shot object detection literature primarily focuses on bounding box classification by obtaining as discriminative feature embeddings as possible, we emphasize the necessity of handling the lack of intersection-over-union (IoU) variations induced by a biased distribution of novel samples. In this paper, we analyze the IoU imbalance that is caused by the relatively high number of low-quality region proposals, and reveal that it plays a critical role in improving few-shot learning capabilities. The well-known two stage fine-tuning technique causes insufficient quality and quantity of the novel positive samples, which hinders the effective object detection of unseen novel classes. To alleviate this issue, we present a few-shot object detection model with proposal balance refinement, a simple yet effective approach in learning object proposals using an auxiliary sequential bounding box refinement process. This process enables the detector to be optimized on the various IoU scores through additional novel class samples. To fully exploit our sequential stage architecture, we revise the fine-tuning strategy and expose the Region Proposal Network to the novel classes in order to provide increased learning opportunities for the region-of-interest (RoI) classifiers and regressors. Our extensive assessments on PASCAL VOC and COCO demonstrate that our framework substantially outperforms other existing few-shot object detection approaches.
Style-Guided Domain Adaptation for Face Presentation Attack Detection
Mar 28, 2022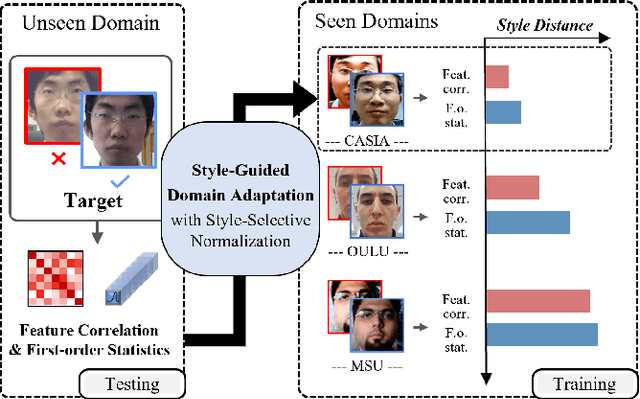
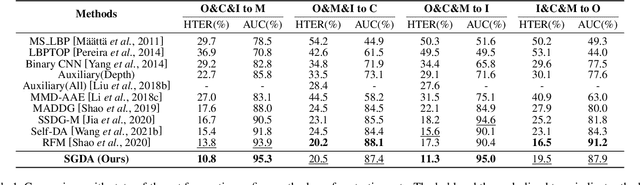
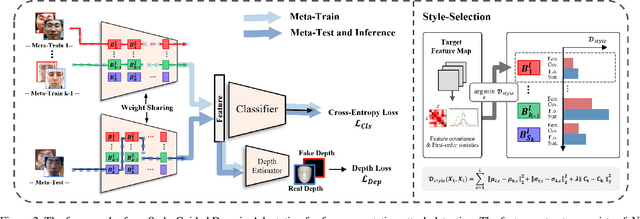

Domain adaptation (DA) or domain generalization (DG) for face presentation attack detection (PAD) has attracted attention recently with its robustness against unseen attack scenarios. Existing DA/DG-based PAD methods, however, have not yet fully explored the domain-specific style information that can provide knowledge regarding attack styles (e.g., materials, background, illumination and resolution). In this paper, we introduce a novel Style-Guided Domain Adaptation (SGDA) framework for inference-time adaptive PAD. Specifically, Style-Selective Normalization (SSN) is proposed to explore the domain-specific style information within the high-order feature statistics. The proposed SSN enables the adaptation of the model to the target domain by reducing the style difference between the target and the source domains. Moreover, we carefully design Style-Aware Meta-Learning (SAML) to boost the adaptation ability, which simulates the inference-time adaptation with style selection process on virtual test domain. In contrast to previous domain adaptation approaches, our method does not require either additional auxiliary models (e.g., domain adaptors) or the unlabeled target domain during training, which makes our method more practical to PAD task. To verify our experiments, we utilize the public datasets: MSU-MFSD, CASIA-FASD, OULU-NPU and Idiap REPLAYATTACK. In most assessments, the result demonstrates a notable gap of performance compared to the conventional DA/DG-based PAD methods.
Improving Interpretability of Deep Neural Networks in Medical Diagnosis by Investigating the Individual Units
Jul 19, 2021

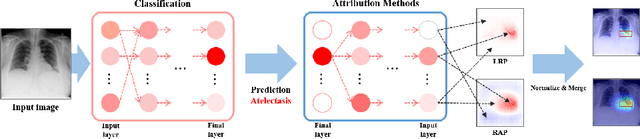
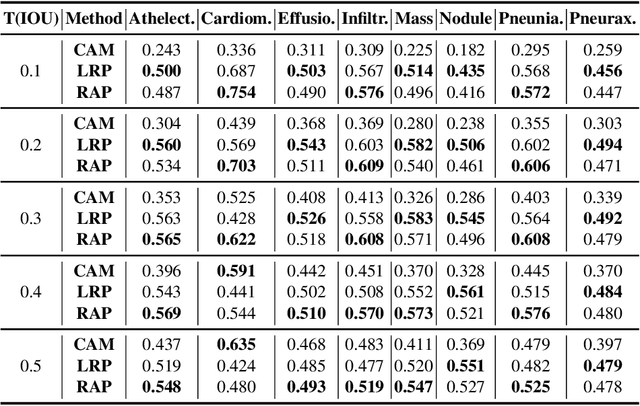
As interpretability has been pointed out as the obstacle to the adoption of Deep Neural Networks (DNNs), there is an increasing interest in solving a transparency issue to guarantee the impressive performance. In this paper, we demonstrate the efficiency of recent attribution techniques to explain the diagnostic decision by visualizing the significant factors in the input image. By utilizing the characteristics of objectness that DNNs have learned, fully decomposing the network prediction visualizes clear localization of target lesion. To verify our work, we conduct our experiments on Chest X-ray diagnosis with publicly accessible datasets. As an intuitive assessment metric for explanations, we report the performance of intersection of Union between visual explanation and bounding box of lesions. Experiment results show that recently proposed attribution methods visualize the more accurate localization for the diagnostic decision compared to the traditionally used CAM. Furthermore, we analyze the inconsistency of intentions between humans and DNNs, which is easily obscured by high performance. By visualizing the relevant factors, it is possible to confirm that the criterion for decision is in line with the learning strategy. Our analysis of unmasking machine intelligence represents the necessity of explainability in the medical diagnostic decision.
Interpreting Deep Neural Networks with Relative Sectional Propagation by Analyzing Comparative Gradients and Hostile Activations
Dec 12, 2020
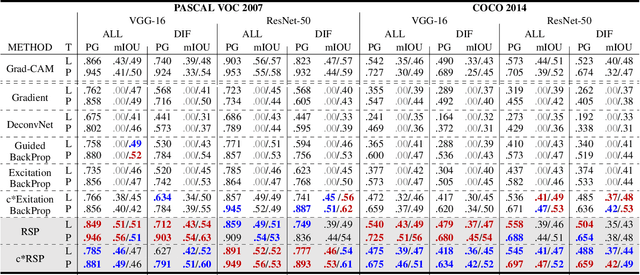
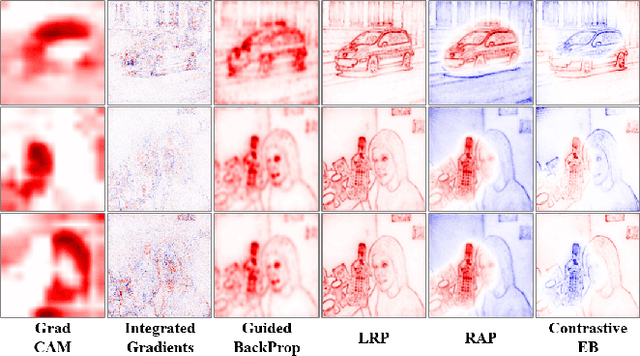
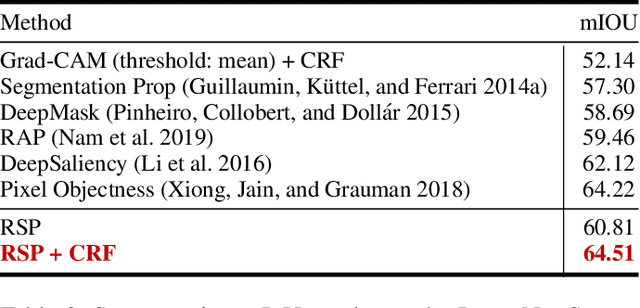
The clear transparency of Deep Neural Networks (DNNs) is hampered by complex internal structures and nonlinear transformations along deep hierarchies. In this paper, we propose a new attribution method, Relative Sectional Propagation (RSP), for fully decomposing the output predictions with the characteristics of class-discriminative attributions and clear objectness. We carefully revisit some shortcomings of backpropagation-based attribution methods, which are trade-off relations in decomposing DNNs. We define hostile factor as an element that interferes with finding the attributions of the target and propagate it in a distinguishable way to overcome the non-suppressed nature of activated neurons. As a result, it is possible to assign the bi-polar relevance scores of the target (positive) and hostile (negative) attributions while maintaining each attribution aligned with the importance. We also present the purging techniques to prevent the decrement of the gap between the relevance scores of the target and hostile attributions during backward propagation by eliminating the conflicting units to channel attribution map. Therefore, our method makes it possible to decompose the predictions of DNNs with clearer class-discriminativeness and detailed elucidations of activation neurons compared to the conventional attribution methods. In a verified experimental environment, we report the results of the assessments: (i) Pointing Game, (ii) mIoU, and (iii) Model Sensitivity with PASCAL VOC 2007, MS COCO 2014, and ImageNet datasets. The results demonstrate that our method outperforms existing backward decomposition methods, including distinctive and intuitive visualizations.
Rotation Invariant Aerial Image Retrieval with Group Convolutional Metric Learning
Oct 19, 2020
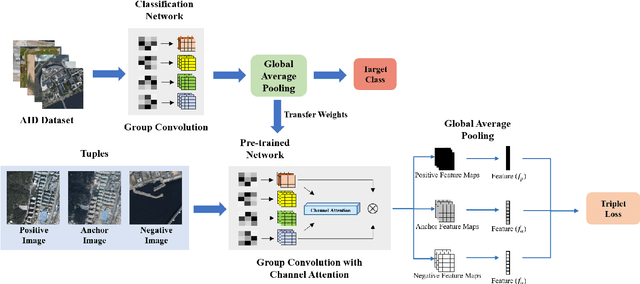

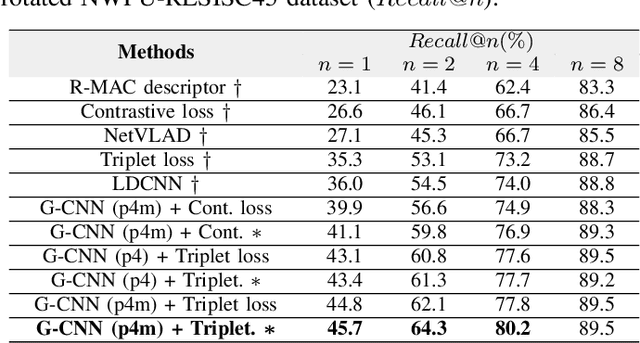
Remote sensing image retrieval (RSIR) is the process of ranking database images depending on the degree of similarity compared to the query image. As the complexity of RSIR increases due to the diversity in shooting range, angle, and location of remote sensors, there is an increasing demand for methods to address these issues and improve retrieval performance. In this work, we introduce a novel method for retrieving aerial images by merging group convolution with attention mechanism and metric learning, resulting in robustness to rotational variations. For refinement and emphasis on important features, we applied channel attention in each group convolution stage. By utilizing the characteristics of group convolution and channel-wise attention, it is possible to acknowledge the equality among rotated but identically located images. The training procedure has two main steps: (i) training the network with Aerial Image Dataset (AID) for classification, (ii) fine-tuning the network with triplet-loss for retrieval with Google Earth South Korea and NWPU-RESISC45 datasets. Results show that the proposed method performance exceeds other state-of-the-art retrieval methods in both rotated and original environments. Furthermore, we utilize class activation maps (CAM) to visualize the distinct difference of main features between our method and baseline, resulting in better adaptability in rotated environments.