 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
EHRNoteQA: A Patient-Specific Question Answering Benchmark for Evaluating Large Language Models in Clinical Settings
Feb 27, 2024
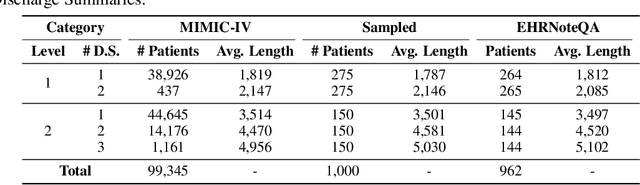


This study introduces EHRNoteQA, a novel patient-specific question answering benchmark tailored for evaluating Large Language Models (LLMs) in clinical environments. Based on MIMIC-IV Electronic Health Record (EHR), a team of three medical professionals has curated the dataset comprising 962 unique questions, each linked to a specific patient's EHR clinical notes. What makes EHRNoteQA distinct from existing EHR-based benchmarks is as follows: Firstly, it is the first dataset to adopt a multi-choice question answering format, a design choice that effectively evaluates LLMs with reliable scores in the context of automatic evaluation, compared to other formats. Secondly, it requires an analysis of multiple clinical notes to answer a single question, reflecting the complex nature of real-world clinical decision-making where clinicians review extensive records of patient histories. Our comprehensive evaluation on various large language models showed that their scores on EHRNoteQA correlate more closely with their performance in addressing real-world medical questions evaluated by clinicians than their scores from other LLM benchmarks. This underscores the significance of EHRNoteQA in evaluating LLMs for medical applications and highlights its crucial role in facilitating the integration of LLMs into healthcare systems. The dataset will be made available to the public under PhysioNet credential access, promoting further research in this vital field.
Drug-disease Graph: Predicting Adverse Drug Reaction Signals via Graph Neural Network with Clinical Data
Apr 01, 2020

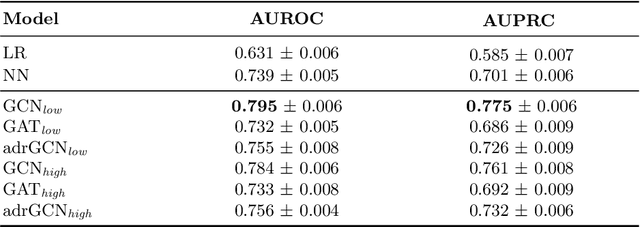

Adverse Drug Reaction (ADR) is a significant public health concern world-wide. Numerous graph-based methods have been applied to biomedical graphs for predicting ADRs in pre-marketing phases. ADR detection in post-market surveillance is no less important than pre-marketing assessment, and ADR detection with large-scale clinical data have attracted much attention in recent years. However, there are not many studies considering graph structures from clinical data for detecting an ADR signal, which is a pair of a prescription and a diagnosis that might be a potential ADR. In this study, we develop a novel graph-based framework for ADR signal detection using healthcare claims data. We construct a Drug-disease graph with nodes representing the medical codes. The edges are given as the relationships between two codes, computed using the data. We apply Graph Neural Network to predict ADR signals, using labels from the Side Effect Resource database. The model shows improved AUROC and AUPRC performance of 0.795 and 0.775, compared to other algorithms, showing that it successfully learns node representations expressive of those relationships. Furthermore, our model predicts ADR pairs that do not exist in the established ADR database, showing its capability to supplement the ADR database.