 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisAlign: Dataset for Measuring the Degree of Alignment between AI and Humans in Visual Perception
Aug 03, 2023



AI alignment refers to models acting towards human-intended goals, preferences, or ethical principles. Given that most large-scale deep learning models act as black boxes and cannot be manually controlled, analyzing the similarity between models and humans can be a proxy measure for ensuring AI safety. In this paper, we focus on the models' visual perception alignment with humans, further referred to as AI-human visual alignment. Specifically, we propose a new dataset for measuring AI-human visual alignment in terms of image classification, a fundamental task in machine perception. In order to evaluate AI-human visual alignment, a dataset should encompass samples with various scenarios that may arise in the real world and have gold human perception labels. Our dataset consists of three groups of samples, namely Must-Act (i.e., Must-Classify), Must-Abstain, and Uncertain, based on the quantity and clarity of visual information in an image and further divided into eight categories. All samples have a gold human perception label; even Uncertain (severely blurry) sample labels were obtained via crowd-sourcing. The validity of our dataset is verified by sampling theory, statistical theories related to survey design, and experts in the related fields. Using our dataset, we analyze the visual alignment and reliability of five popular visual perception models and seven abstention methods. Our code and data is available at \url{https://github.com/jiyounglee-0523/VisAlign}.
X-MAS: Extremely Large-Scale Multi-Modal Sensor Dataset for Outdoor Surveillance in Real Environments
Dec 30, 2022



In robotics and computer vision communities, extensive studies have been widely conducted regarding surveillance tasks, including human detection, tracking, and motion recognition with a camera. Additionally, deep learning algorithms are widely utilized in the aforementioned tasks as in other computer vision tasks. Existing public datasets are insufficient to develop learning-based methods that handle various surveillance for outdoor and extreme situations such as harsh weather and low illuminance conditions. Therefore, we introduce a new large-scale outdoor surveillance dataset named eXtremely large-scale Multi-modAl Sensor dataset (X-MAS) containing more than 500,000 image pairs and the first-person view data annotated by well-trained annotators. Moreover, a single pair contains multi-modal data (e.g. an IR image, an RGB image, a thermal image, a depth image, and a LiDAR scan). This is the first large-scale first-person view outdoor multi-modal dataset focusing on surveillance tasks to the best of our knowledge. We present an overview of the proposed dataset with statistics and present methods of exploiting our dataset with deep learning-based algorithms. The latest information on the dataset and our study are available at https://github.com/lge-robot-navi, and the dataset will be available for download through a server.
Part-Aware Data Augmentation for 3D Object Detection in Point Cloud
Jul 27, 2020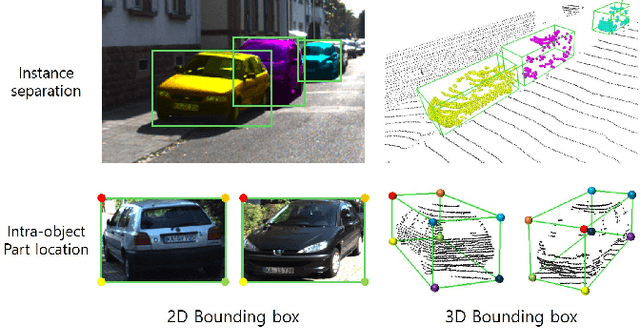
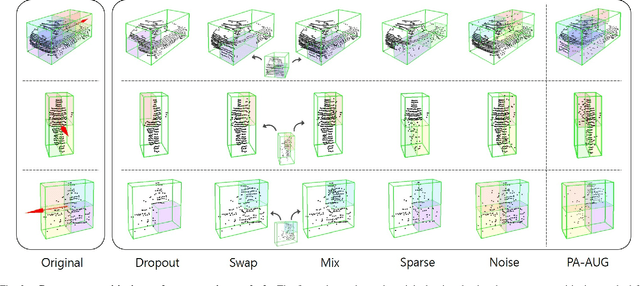
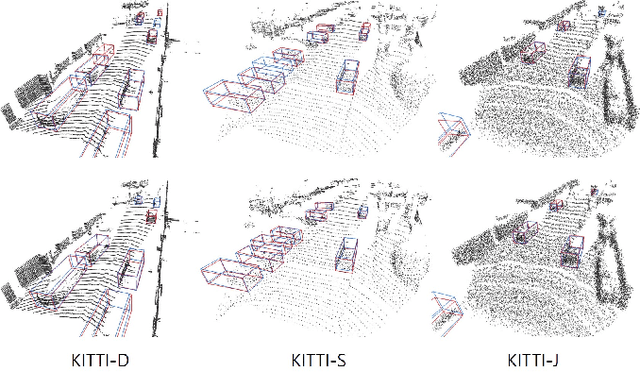
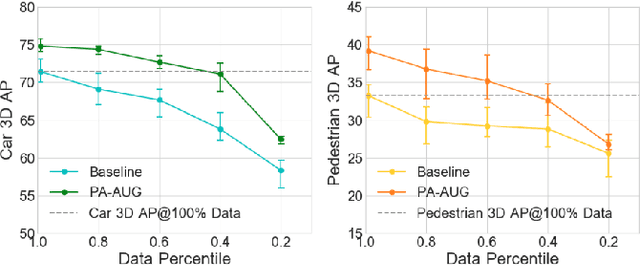
Data augmentation has greatly contributed to improving the performance in image recognition tasks, and a lot of related studies have been conducted. However, data augmentation on 3D point cloud data has not been much explored. 3D label has more sophisticated and rich structural information than the 2D label, so it enables more diverse and effective data augmentation. In this paper, we propose part-aware data augmentation (PA-AUG) that can better utilize rich information of 3D label to enhance the performance of 3D object detectors. PA-AUG divides objects into partitions and stochastically applies five novel augmentation methods to each local region. It is compatible with existing point cloud data augmentation methods and can be used universally regardless of the detector's architecture. PA-AUG has improved the performance of state-of-the-art 3D object detector for all classes of the KITTI dataset and has the equivalent effect of increasing the train data by about 2.5$\times$. We also show that PA-AUG not only increases performance for a given dataset but also is robust to corrupted data. CODE WILL BE AVAILABLE.
KL-Divergence-Based Region Proposal Network for Object Detection
May 22, 2020

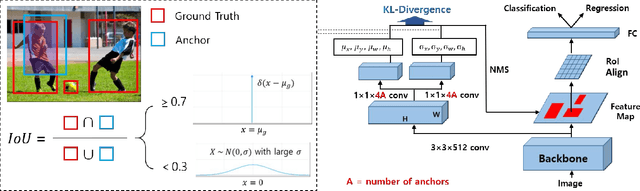

The learning of the region proposal in object detection using the deep neural networks (DNN) is divided into two tasks: binary classification and bounding box regression task. However, traditional RPN (Region Proposal Network) defines these two tasks as different problems, and they are trained independently. In this paper, we propose a new region proposal learning method that considers the bounding box offset's uncertainty in the objectness score. Our method redefines RPN to a problem of minimizing the KL-divergence, difference between the two probability distributions. We applied KL-RPN, which performs region proposal using KL-Divergence, to the existing two-stage object detection framework and showed that it can improve the performance of the existing method. Experiments show that it achieves 2.6% and 2.0% AP improvements on MS COCO test-dev in Faster R-CNN with VGG-16 and R-FCN with ResNet-101 backbone, respectively.
BOOK: Storing Algorithm-Invariant Episodes for Deep Reinforcement Learning
Feb 12, 2018


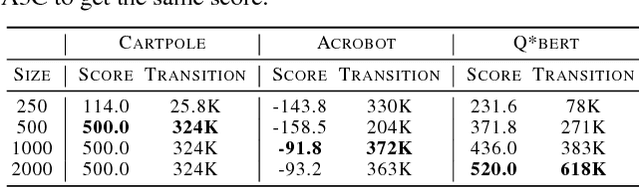
We introduce a novel method to train agents of reinforcement learning (RL) by sharing knowledge in a way similar to the concept of using a book. The recorded information in the form of a book is the main means by which humans learn knowledge. Nevertheless, the conventional deep RL methods have mainly focused either on experiential learning where the agent learns through interactions with the environment from the start or on imitation learning that tries to mimic the teacher. Contrary to these, our proposed book learning shares key information among different agents in a book-like manner by delving into the following two characteristic features: (1) By defining the linguistic function, input states can be clustered semantically into a relatively small number of core clusters, which are forwarded to other RL agents in a prescribed manner. (2) By defining state priorities and the contents for recording, core experiences can be selected and stored in a small container. We call this container as `BOOK'. Our method learns hundreds to thousand times faster than the conventional methods by learning only a handful of core cluster information, which shows that deep RL agents can effectively learn through the shared knowledge from other agents.
Residual Features and Unified Prediction Network for Single Stage Detection
Jan 05, 2018

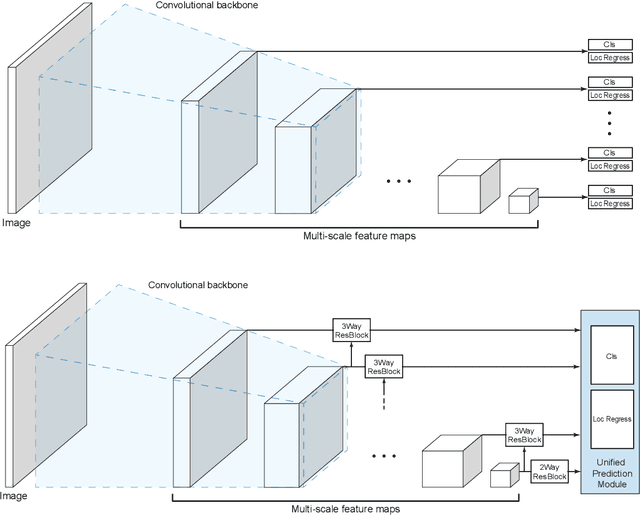
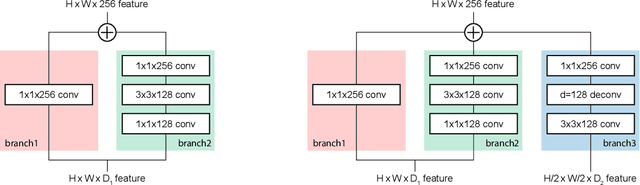
Recently, a lot of single stage detectors using multi-scale features have been actively proposed. They are much faster than two stage detectors that use region proposal networks (RPN) without much degradation in the detection performances. However, the feature maps in the lower layers close to the input which are responsible for detecting small objects in a single stage detector have a problem of insufficient representation power because they are too shallow. There is also a structural contradiction that the feature maps have to deliver low-level information to next layers as well as contain high-level abstraction for prediction. In this paper, we propose a method to enrich the representation power of feature maps using Resblock and deconvolution layers. In addition, a unified prediction module is applied to generalize output results and boost earlier layers' representation power for prediction. The proposed method enables more precise prediction, which achieved higher score than SSD on PASCAL VOC and MS COCO. In addition, it maintains the advantage of fast computation of a single stage detector, which requires much less computation than other detectors with similar performance. Code is available at https://github.com/kmlee-snu/run