 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Finely-Categorized Image-Text Retrieval by Selecting Hard Negative Unpaired Samples
May 25, 2024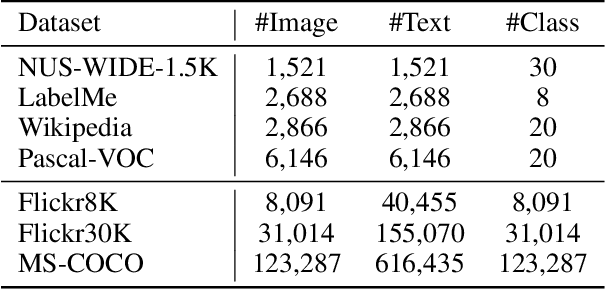

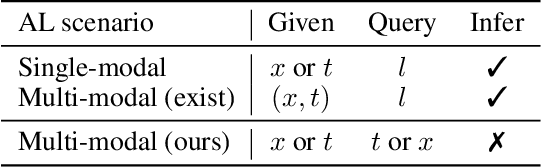
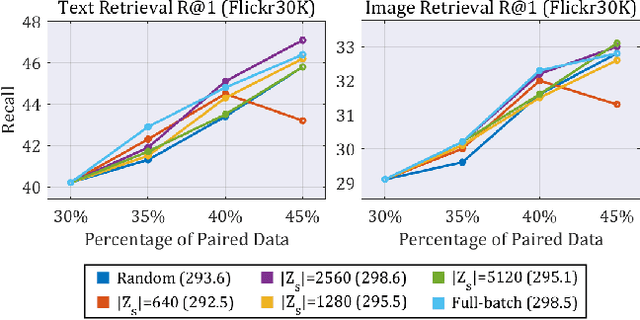
Securing a sufficient amount of paired data is important to train an image-text retrieval (ITR) model, but collecting paired data is very expensive. To address this issue, in this paper, we propose an active learning algorithm for ITR that can collect paired data cost-efficiently. Previous studies assume that image-text pairs are given and their category labels are asked to the annotator. However, in the recent ITR studies, the importance of category label is decreased since a retrieval model can be trained with only image-text pairs. For this reason, we set up an active learning scenario where unpaired images (or texts) are given and the annotator provides corresponding texts (or images) to make paired data. The key idea of the proposed AL algorithm is to select unpaired images (or texts) that can be hard negative samples for existing texts (or images). To this end, we introduce a novel scoring function to choose hard negative samples. We validate the effectiveness of the proposed method on Flickr30K and MS-COCO datasets.
X-MAS: Extremely Large-Scale Multi-Modal Sensor Dataset for Outdoor Surveillance in Real Environments
Dec 30, 2022



In robotics and computer vision communities, extensive studies have been widely conducted regarding surveillance tasks, including human detection, tracking, and motion recognition with a camera. Additionally, deep learning algorithms are widely utilized in the aforementioned tasks as in other computer vision tasks. Existing public datasets are insufficient to develop learning-based methods that handle various surveillance for outdoor and extreme situations such as harsh weather and low illuminance conditions. Therefore, we introduce a new large-scale outdoor surveillance dataset named eXtremely large-scale Multi-modAl Sensor dataset (X-MAS) containing more than 500,000 image pairs and the first-person view data annotated by well-trained annotators. Moreover, a single pair contains multi-modal data (e.g. an IR image, an RGB image, a thermal image, a depth image, and a LiDAR scan). This is the first large-scale first-person view outdoor multi-modal dataset focusing on surveillance tasks to the best of our knowledge. We present an overview of the proposed dataset with statistics and present methods of exploiting our dataset with deep learning-based algorithms. The latest information on the dataset and our study are available at https://github.com/lge-robot-navi, and the dataset will be available for download through a server.
Font Representation Learning via Paired-glyph Matching
Nov 20, 2022



Fonts can convey profound meanings of words in various forms of glyphs. Without typography knowledge, manually selecting an appropriate font or designing a new font is a tedious and painful task. To allow users to explore vast font styles and create new font styles, font retrieval and font style transfer methods have been proposed. These tasks increase the need for learning high-quality font representations. Therefore, we propose a novel font representation learning scheme to embed font styles into the latent space. For the discriminative representation of a font from others, we propose a paired-glyph matching-based font representation learning model that attracts the representations of glyphs in the same font to one another, but pushes away those of other fonts. Through evaluations on font retrieval with query glyphs on new fonts, we show our font representation learning scheme achieves better generalization performance than the existing font representation learning techniques. Finally on the downstream font style transfer and generation tasks, we confirm the benefits of transfer learning with the proposed method. The source code is available at https://github.com/junhocho/paired-glyph-matching.
Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning
Aug 07, 2019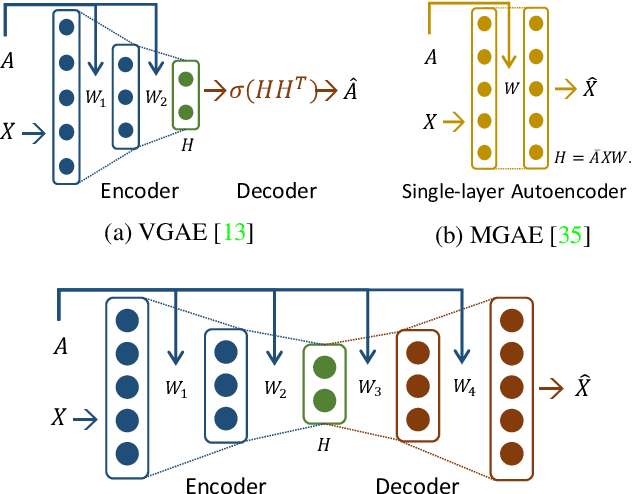
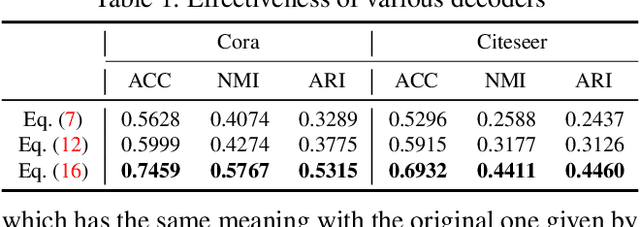

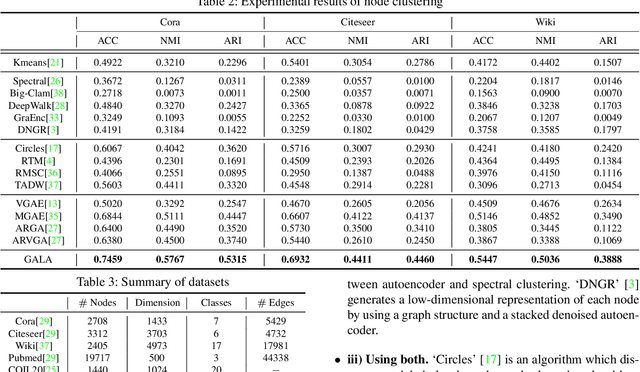
We propose a symmetric graph convolutional autoencoder which produces a low-dimensional latent representation from a graph. In contrast to the existing graph autoencoders with asymmetric decoder parts, the proposed autoencoder has a newly designed decoder which builds a completely symmetric autoencoder form. For the reconstruction of node features, the decoder is designed based on Laplacian sharpening as the counterpart of Laplacian smoothing of the encoder, which allows utilizing the graph structure in the whole processes of the proposed autoencoder architecture. In order to prevent the numerical instability of the network caused by the Laplacian sharpening introduction, we further propose a new numerically stable form of the Laplacian sharpening by incorporating the signed graphs. In addition, a new cost function which finds a latent representation and a latent affinity matrix simultaneously is devised to boost the performance of image clustering tasks. The experimental results on clustering, link prediction and visualization tasks strongly support that the proposed model is stable and outperforms various state-of-the-art algorithms.
Context-aware Deep Feature Compression for High-speed Visual Tracking
Mar 28, 2018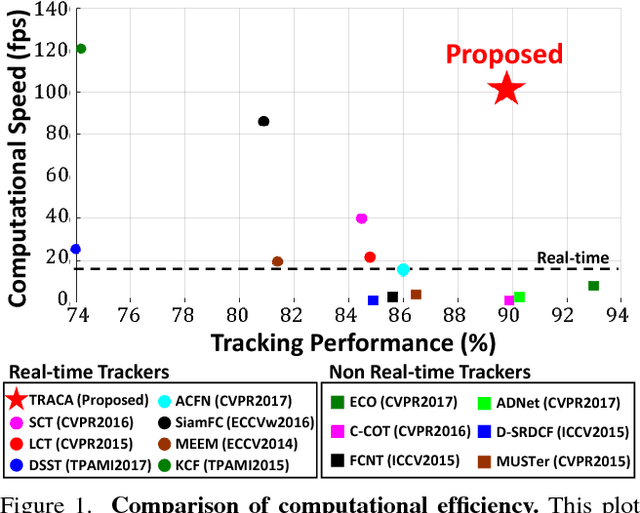
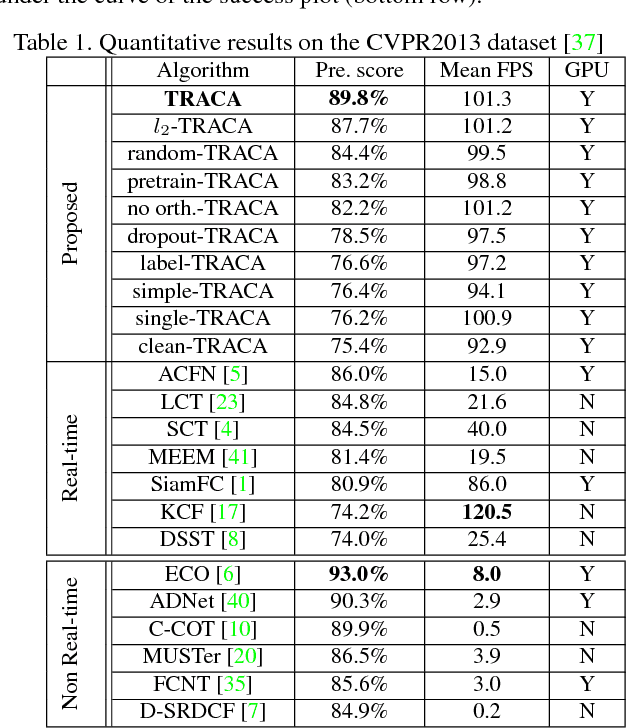
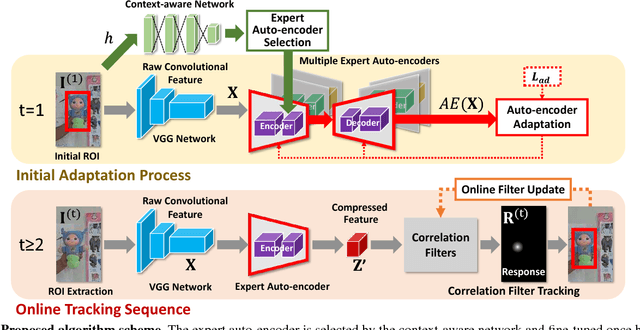
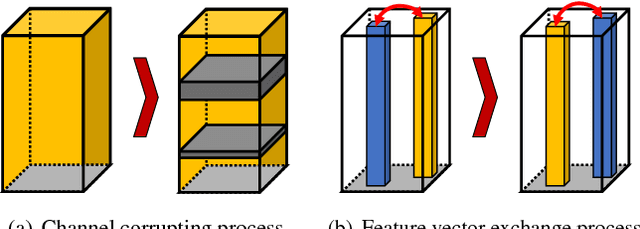
We propose a new context-aware correlation filter based tracking framework to achieve both high computational speed and state-of-the-art performance among real-time trackers. The major contribution to the high computational speed lies in the proposed deep feature compression that is achieved by a context-aware scheme utilizing multiple expert auto-encoders; a context in our framework refers to the coarse category of the tracking target according to appearance patterns. In the pre-training phase, one expert auto-encoder is trained per category. In the tracking phase, the best expert auto-encoder is selected for a given target, and only this auto-encoder is used. To achieve high tracking performance with the compressed feature map, we introduce extrinsic denoising processes and a new orthogonality loss term for pre-training and fine-tuning of the expert auto-encoders. We validate the proposed context-aware framework through a number of experiments, where our method achieves a comparable performance to state-of-the-art trackers which cannot run in real-time, while running at a significantly fast speed of over 100 fps.
Joint Person Re-identification and Camera Network Topology Inference in Multiple Cameras
Oct 03, 2017
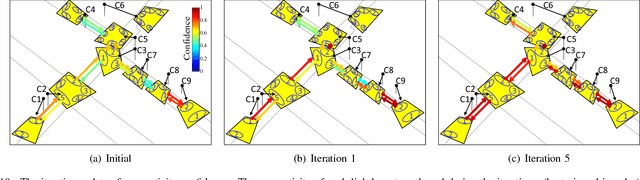
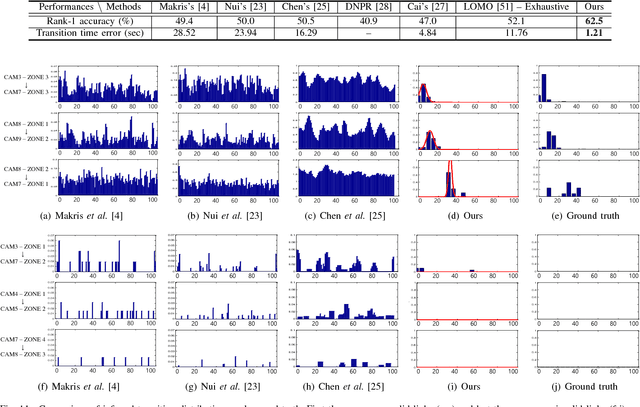

Person re-identification is the task of recognizing or identifying a person across multiple views in multi-camera networks. Although there has been much progress in person re-identification, person re-identification in large-scale multi-camera networks still remains a challenging task because of the large spatio-temporal uncertainty and high complexity due to a large number of cameras and people. To handle these difficulties, additional information such as camera network topology should be provided, which is also difficult to automatically estimate, unfortunately. In this study, we propose a unified framework which jointly solves both person re-identification and camera network topology inference problems with minimal prior knowledge about the environments. The proposed framework takes general multi-camera network environments into account and can be applied to online person re-identification in large-scale multi-camera networks. In addition, to effectively show the superiority of the proposed framework, we provide a new person re-identification dataset with full annotations, named SLP, captured in the multi-camera network consisting of nine non-overlapping cameras. Experimental results using our person re-identification and public datasets show that the proposed methods are promising for both person re-identification and camera topology inference tasks.
Unified Framework for Automated Person Re-identification and Camera Network Topology Inference in Camera Networks
Oct 02, 2017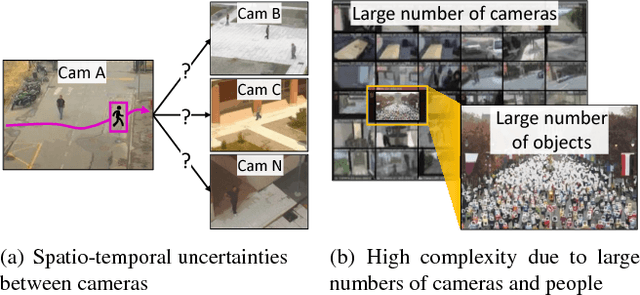

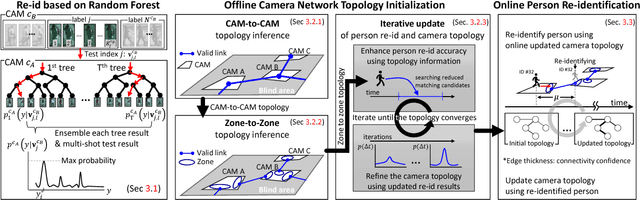
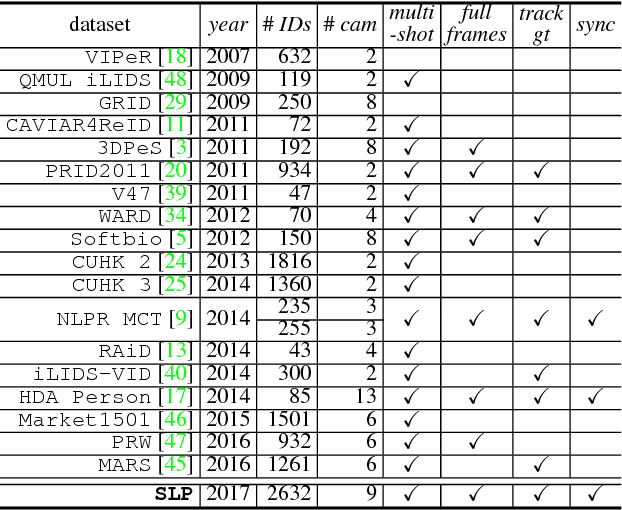
Person re-identification in large-scale multi-camera networks is a challenging task because of the spatio-temporal uncertainty and high complexity due to large numbers of cameras and people. To handle these difficulties, additional information such as camera network topology should be provided, which is also difficult to automatically estimate. In this paper, we propose a unified framework which jointly solves both person re-id and camera network topology inference problems. The proposed framework takes general multi-camera network environments into account. To effectively show the superiority of the proposed framework, we also provide a new person re-id dataset with full annotations, named SLP, captured in the synchronized multi-camera network. Experimental results show that the proposed methods are promising for both person re-id and camera topology inference tasks.