 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANCE: Density-agnostic and Class-aware Network for Point Cloud Completion
Nov 17, 2025Point cloud completion aims to recover missing geometric structures from incomplete 3D scans, which often suffer from occlusions or limited sensor viewpoints. Existing methods typically assume fixed input/output densities or rely on image-based representations, making them less suitable for real-world scenarios with variable sparsity and limited supervision. In this paper, we introduce Density-agnostic and Class-aware Network (DANCE), a novel framework that completes only the missing regions while preserving the observed geometry. DANCE generates candidate points via ray-based sampling from multiple viewpoints. A transformer decoder then refines their positions and predicts opacity scores, which determine the validity of each point for inclusion in the final surface. To incorporate semantic guidance, a lightweight classification head is trained directly on geometric features, enabling category-consistent completion without external image supervision. Extensive experiments on the PCN and MVP benchmarks show that DANCE outperforms state-of-the-art methods in accuracy and structural consistency, while remaining robust to varying input densities and noise levels.
RS-Net: Context-Aware Relation Scoring for Dynamic Scene Graph Generation
Nov 11, 2025Dynamic Scene Graph Generation (DSGG) models how object relations evolve over time in videos. However, existing methods are trained only on annotated object pairs and lack guidance for non-related pairs, making it difficult to identify meaningful relations during inference. In this paper, we propose Relation Scoring Network (RS-Net), a modular framework that scores the contextual importance of object pairs using both spatial interactions and long-range temporal context. RS-Net consists of a spatial context encoder with learnable context tokens and a temporal encoder that aggregates video-level information. The resulting relation scores are integrated into a unified triplet scoring mechanism to enhance relation prediction. RS-Net can be easily integrated into existing DSGG models without architectural changes. Experiments on the Action Genome dataset show that RS-Net consistently improves both Recall and Precision across diverse baselines, with notable gains in mean Recall, highlighting its ability to address the long-tailed distribution of relations. Despite the increased number of parameters, RS-Net maintains competitive efficiency, achieving superior performance over state-of-the-art methods.
CSF-Net: Context-Semantic Fusion Network for Large Mask Inpainting
Nov 11, 2025In this paper, we propose a semantic-guided framework to address the challenging problem of large-mask image inpainting, where essential visual content is missing and contextual cues are limited. To compensate for the limited context, we leverage a pretrained Amodal Completion (AC) model to generate structure-aware candidates that serve as semantic priors for the missing regions. We introduce Context-Semantic Fusion Network (CSF-Net), a transformer-based fusion framework that fuses these candidates with contextual features to produce a semantic guidance image for image inpainting. This guidance improves inpainting quality by promoting structural accuracy and semantic consistency. CSF-Net can be seamlessly integrated into existing inpainting models without architectural changes and consistently enhances performance across diverse masking conditions. Extensive experiments on the Places365 and COCOA datasets demonstrate that CSF-Net effectively reduces object hallucination while enhancing visual realism and semantic alignment. The code for CSF-Net is available at https://github.com/chaeyeonheo/CSF-Net.
NOVO: Bridging LLaVA and SAM with Visual-only Prompts for Reasoning Segmentation
Nov 10, 2025


In this study, we propose NOVO (NO text, Visual-Only prompts), a novel framework that bridges vision-language models (VLMs) and segmentation models through visual-only prompts. Unlike prior approaches that feed text-derived SEG token embeddings into segmentation models, NOVO instead generates a coarse mask and point prompts from the VLM output. These visual prompts are compatible with the Segment Anything Model (SAM), preserving alignment with its pretrained capabilities. To further enhance boundary quality and enable instance-level segmentation, we introduce a training-free refinement module that reduces visual artifacts and improves the quality of segmentation masks. We also present RISeg, a new benchmark comprising 918 images, 2,533 instance-level masks, and diverse reasoning queries to evaluate this task. Experiments demonstrate that NOVO achieves state-of-the-art performance across multiple metrics and model sizes, demonstrating its effectiveness and scalability in reasoning segmentation.
Med-SORA: Symptom to Organ Reasoning in Abdomen CT Images
Nov 10, 2025Understanding symptom-image associations is crucial for clinical reasoning. However, existing medical multimodal models often rely on simple one-to-one hard labeling, oversimplifying clinical reality where symptoms relate to multiple organs. In addition, they mainly use single-slice 2D features without incorporating 3D information, limiting their ability to capture full anatomical context. In this study, we propose Med-SORA, a framework for symptom-to-organ reasoning in abdominal CT images. Med-SORA introduces RAG-based dataset construction, soft labeling with learnable organ anchors to capture one-to-many symptom-organ relationships, and a 2D-3D cross-attention architecture to fuse local and global image features. To our knowledge, this is the first work to address symptom-to-organ reasoning in medical multimodal learning. Experimental results show that Med-SORA outperforms existing medical multimodal models and enables accurate 3D clinical reasoning.
PointCubeNet: 3D Part-level Reasoning with 3x3x3 Point Cloud Blocks
Nov 10, 2025In this paper, we propose PointCubeNet, a novel multi-modal 3D understanding framework that achieves part-level reasoning without requiring any part annotations. PointCubeNet comprises global and local branches. The proposed local branch, structured into 3x3x3 local blocks, enables part-level analysis of point cloud sub-regions with the corresponding local text labels. Leveraging the proposed pseudo-labeling method and local loss function, PointCubeNet is effectively trained in an unsupervised manner. The experimental results demonstrate that understanding 3D object parts enhances the understanding of the overall 3D object. In addition, this is the first attempt to perform unsupervised 3D part-level reasoning and achieves reliable and meaningful results.
DroneKey: Drone 3D Pose Estimation in Image Sequences using Gated Key-representation and Pose-adaptive Learning
Aug 25, 2025



Estimating the 3D pose of a drone is important for anti-drone systems, but existing methods struggle with the unique challenges of drone keypoint detection. Drone propellers serve as keypoints but are difficult to detect due to their high visual similarity and diversity of poses. To address these challenges, we propose DroneKey, a framework that combines a 2D keypoint detector and a 3D pose estimator specifically designed for drones. In the keypoint detection stage, we extract two key-representations (intermediate and compact) from each transformer encoder layer and optimally combine them using a gated sum. We also introduce a pose-adaptive Mahalanobis distance in the loss function to ensure stable keypoint predictions across extreme poses. We built new datasets of drone 2D keypoints and 3D pose to train and evaluate our method, which have been publicly released. Experiments show that our method achieves an AP of 99.68% (OKS) in keypoint detection, outperforming existing methods. Ablation studies confirm that the pose-adaptive Mahalanobis loss function improves keypoint prediction stability and accuracy. Additionally, improvements in the encoder design enable real-time processing at 44 FPS. For 3D pose estimation, our method achieved an MAE-angle of 10.62{\deg}, an RMSE of 0.221m, and an MAE-absolute of 0.076m, demonstrating high accuracy and reliability. The code and dataset are available at https://github.com/kkanuseobin/DroneKey.
Object Re-identification via Spatial-temporal Fusion Networks and Causal Identity Matching
Aug 10, 2024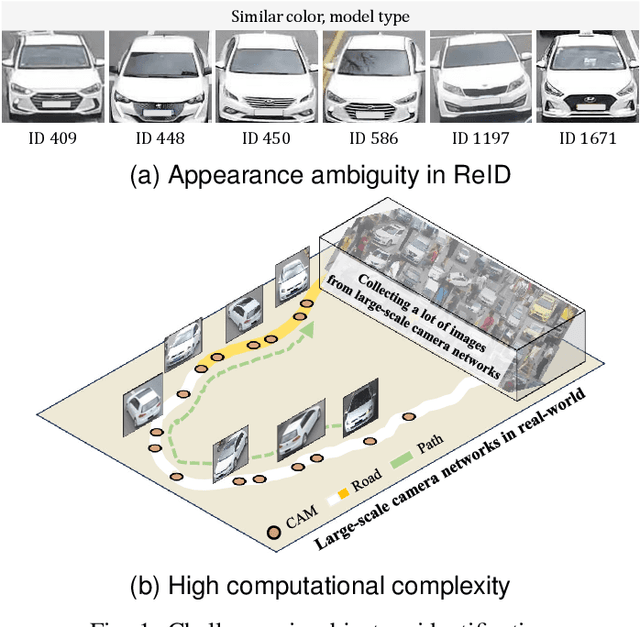


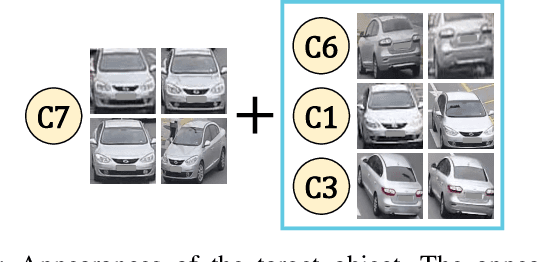
Object re-identification (ReID) in large camera networks has many challenges. First, the similar appearances of objects degrade ReID performances. This challenge cannot be addressed by existing appearance-based ReID methods. Second, most ReID studies are performed in laboratory settings and do not consider ReID problems in real-world scenarios. To overcome these challenges, we introduce a novel ReID framework that leverages a spatial-temporal fusion network and causal identity matching (CIM). The framework estimates camera network topology using the proposed adaptive Parzen window and combines appearance features with spatial-temporal cue within the Fusion Network. It achieved outstanding performance across several datasets, including VeRi776, Vehicle-3I, and Market-1501, achieving up to 99.70% rank-1 accuracy and 95.5% mAP. Furthermore, the proposed CIM approach, which dynamically assigns gallery sets based on the camera network topology, further improved ReID accuracy and robustness in real-world settings, evidenced by a 94.95% mAP and 95.19% F1 score on the Vehicle-3I dataset. The experimental results support the effectiveness of incorporating spatial-temporal information and CIM for real-world ReID scenarios regardless of the data domain (e.g., vehicle, person).
Flatfish Disease Detection Based on Part Segmentation Approach and Disease Image Generation
Jul 16, 2024



The flatfish is a major farmed species consumed globally in large quantities. However, due to the densely populated farming environment, flatfish are susceptible to injuries and diseases, making early disease detection crucial. Traditionally, diseases were detected through visual inspection, but observing large numbers of fish is challenging. Automated approaches based on deep learning technologies have been widely used, to address this problem, but accurate detection remains difficult due to the diversity of the fish and the lack of the fish disease dataset. In this study, augments fish disease images using generative adversarial networks and image harmonization methods. Next, disease detectors are trained separately for three body parts (head, fins, and body) to address individual diseases properly. In addition, a flatfish disease image dataset called \texttt{FlatIMG} is created and verified on the dataset using the proposed methods. A flash salmon disease dataset is also tested to validate the generalizability of the proposed methods. The results achieved 12\% higher performance than the baseline framework. This study is the first attempt to create a large-scale flatfish disease image dataset and propose an effective disease detection framework. Automatic disease monitoring could be achieved in farming environments based on the proposed methods and dataset.
Spatial-temporal Vehicle Re-identification
Sep 03, 2023Vehicle re-identification (ReID) in a large-scale camera network is important in public safety, traffic control, and security. However, due to the appearance ambiguities of vehicle, the previous appearance-based ReID methods often fail to track vehicle across multiple cameras. To overcome the challenge, we propose a spatial-temporal vehicle ReID framework that estimates reliable camera network topology based on the adaptive Parzen window method and optimally combines the appearance and spatial-temporal similarities through the fusion network. Based on the proposed methods, we performed superior performance on the public dataset (VeRi776) by 99.64% of rank-1 accuracy. The experimental results support that utilizing spatial and temporal information for ReID can leverage the accuracy of appearance-based methods and effectively deal with appearance ambiguities.