 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLQ-rPPG: A Label-Quantized Coarse-to-Fine Learning Framework for Remote Physiological Measurement
May 22, 2026Remote photoplethysmography (rPPG) enables non-contact measurement of physiological signals from facial videos, offering strong potential for remote healthcare and daily health monitoring. Driven by this potential, various deep learning-based rPPG methods have been proposed to improve rPPG estimation. However, previous deep learning-based rPPG methods have paid little attention to the quality of training labels and their impact on model learning. Contact-based PPG signals used as training labels often contain noise and variability caused by motion artifacts, inconsistent sensor contact, and morphological distortions. Such label inconsistency can lead models to overfit to the label noise and variability and consequently degrade generalization performance. To address this issue, we propose LQ-rPPG, a label-quantized coarse-to-fine learning framework for robust rPPG estimation. LQ-rPPG consists of a label quantization module and a coarse-to-fine rPPG estimation model. The label quantization module transforms continuous PPG signals into multi-bit quantized pseudo labels with reduced noise and variability. The coarse-to-fine estimation model progressively refines rPPG signals under hierarchical supervision guided by the multi-bit pseudo labels. This design alleviates overfitting to label-specific variations and enables the model to learn structured and consistent representations. As a result, LQ-rPPG achieves robust and generalizable rPPG estimation even under challenging conditions. Experiments on multiple benchmark datasets demonstrate that LQ-rPPG achieves strong performance in both intra- and cross-dataset evaluations, while reducing parameters and multiply-accumulate operations by 88% and 29%, respectively, and increasing throughput by 191%. The code is available at https://github.com/Anonymous-repo-code/LQ-rPPG.
E2EGS: Event-to-Edge Gaussian Splatting for Pose-Free 3D Reconstruction
Mar 16, 2026The emergence of neural radiance fields (NeRF) and 3D Gaussian splatting (3DGS) has advanced novel view synthesis (NVS). These methods, however, require high-quality RGB inputs and accurate corresponding poses, limiting robustness under real-world conditions such as fast camera motion or adverse lighting. Event cameras, which capture brightness changes at each pixel with high temporal resolution and wide dynamic range, enable precise sensing of dynamic scenes and offer a promising solution. However, existing event-based NVS methods either assume known poses or rely on depth estimation models that are bounded by their initial observations, failing to generalize as the camera traverses previously unseen regions. We present E2EGS, a pose-free framework operating solely on event streams. Our key insight is that edge information provides rich structural cues essential for accurate trajectory estimation and high-quality NVS. To extract edges from noisy event streams, we exploit the distinct spatio-temporal characteristics of edges and non-edge regions. The event camera's movement induces consistent events along edges, while non-edge regions produce sparse noise. We leverage this through a patch-based temporal coherence analysis that measures local variance to extract edges while robustly suppressing noise. The extracted edges guide structure-aware Gaussian initialization and enable edge-weighted losses throughout initialization, tracking, and bundle adjustment. Extensive experiments on both synthetic and real datasets demonstrate that E2EGS achieves superior reconstruction quality and trajectory accuracy, establishing a fully pose-free paradigm for event-based 3D reconstruction.
VIRD: View-Invariant Representation through Dual-Axis Transformation for Cross-View Pose Estimation
Mar 13, 2026Accurate global localization is crucial for autonomous driving and robotics, but GNSS-based approaches often degrade due to occlusion and multipath effects. As an emerging alternative, cross-view pose estimation predicts the 3-DoF camera pose corresponding to a ground-view image with respect to a geo-referenced satellite image. However, existing methods struggle to bridge the significant viewpoint gap between the ground and satellite views mainly due to limited spatial correspondences. We propose a novel cross-view pose estimation method that constructs view-invariant representations through dual-axis transformation (VIRD). VIRD first applies a polar transformation to the satellite view to establish horizontal correspondence, then uses context-enhanced positional attention on the ground and polar-transformed satellite features to resolve vertical misalignment, explicitly mitigating the viewpoint gap. A view-reconstruction loss is introduced to strengthen the view invariance further, encouraging the derived representations to reconstruct the original and cross-view images. Experiments on the KITTI and VIGOR datasets demonstrate that VIRD outperforms the state-of-the-art methods without orientation priors, reducing median position and orientation errors by 50.7% and 76.5% on KITTI, and 18.0% and 46.8% on VIGOR, respectively.
PIDLoc: Cross-View Pose Optimization Network Inspired by PID Controllers
Mar 04, 2025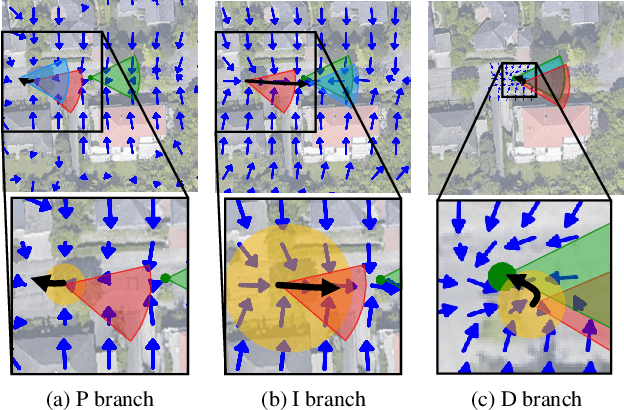
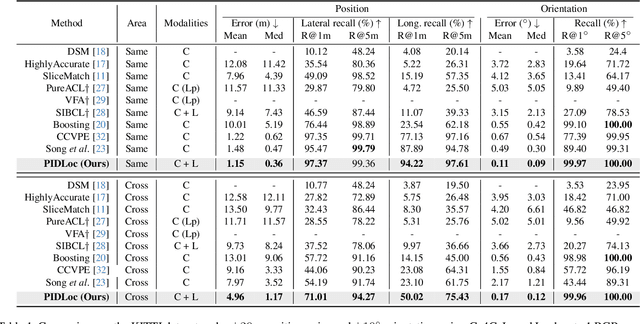
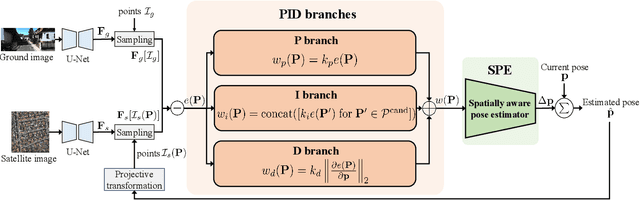
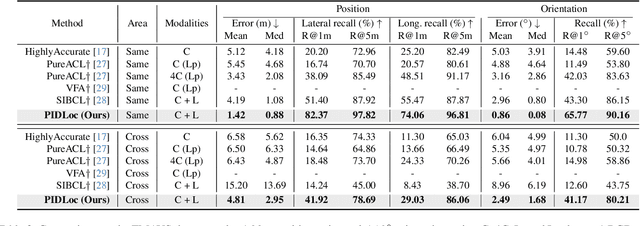
Accurate localization is essential for autonomous driving, but GNSS-based methods struggle in challenging environments such as urban canyons. Cross-view pose optimization offers an effective solution by directly estimating vehicle pose using satellite-view images. However, existing methods primarily rely on cross-view features at a given pose, neglecting fine-grained contexts for precision and global contexts for robustness against large initial pose errors. To overcome these limitations, we propose PIDLoc, a novel cross-view pose optimization approach inspired by the proportional-integral-derivative (PID) controller. Using RGB images and LiDAR, the PIDLoc comprises the PID branches to model cross-view feature relationships and the spatially aware pose estimator (SPE) to estimate the pose from these relationships. The PID branches leverage feature differences for local context (P), aggregated feature differences for global context (I), and gradients of feature differences for precise pose adjustment (D) to enhance localization accuracy under large initial pose errors. Integrated with the PID branches, the SPE captures spatial relationships within the PID-branch features for consistent localization. Experimental results demonstrate that the PIDLoc achieves state-of-the-art performance in cross-view pose estimation for the KITTI dataset, reducing position error by $37.8\%$ compared with the previous state-of-the-art.
Contextrast: Contextual Contrastive Learning for Semantic Segmentation
Apr 16, 2024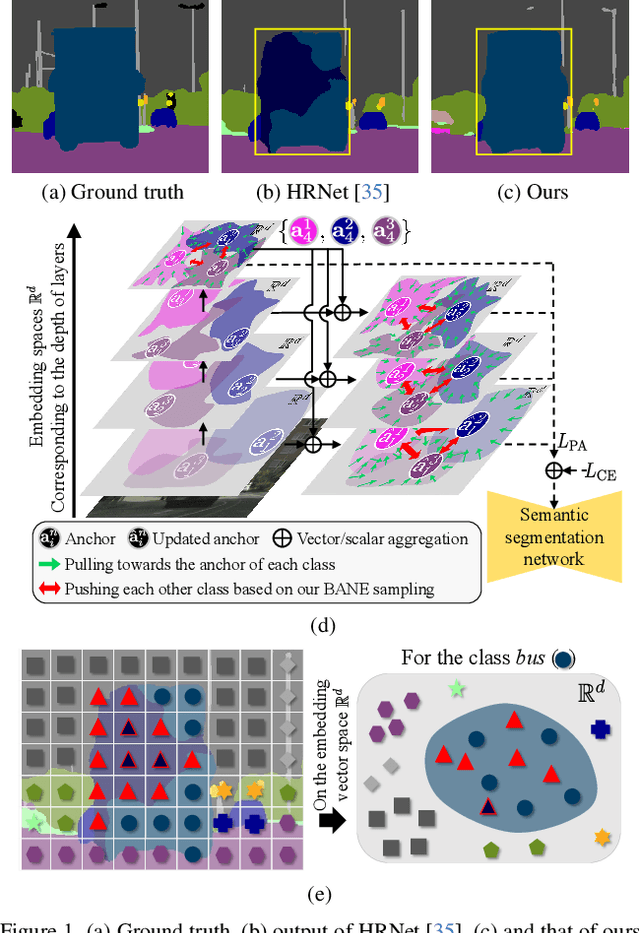

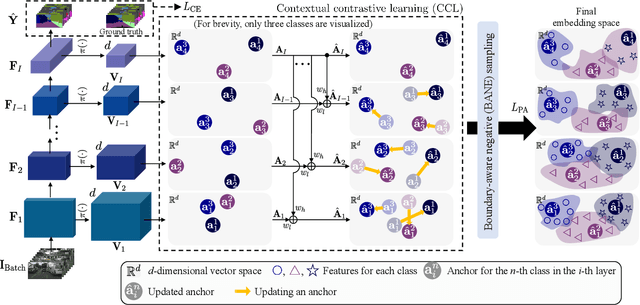
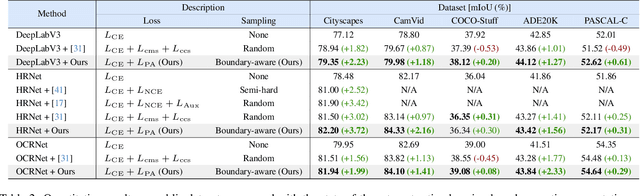
Despite great improvements in semantic segmentation, challenges persist because of the lack of local/global contexts and the relationship between them. In this paper, we propose Contextrast, a contrastive learning-based semantic segmentation method that allows to capture local/global contexts and comprehend their relationships. Our proposed method comprises two parts: a) contextual contrastive learning (CCL) and b) boundary-aware negative (BANE) sampling. Contextual contrastive learning obtains local/global context from multi-scale feature aggregation and inter/intra-relationship of features for better discrimination capabilities. Meanwhile, BANE sampling selects embedding features along the boundaries of incorrectly predicted regions to employ them as harder negative samples on our contrastive learning, resolving segmentation issues along the boundary region by exploiting fine-grained details. We demonstrate that our Contextrast substantially enhances the performance of semantic segmentation networks, outperforming state-of-the-art contrastive learning approaches on diverse public datasets, e.g. Cityscapes, CamVid, PASCAL-C, COCO-Stuff, and ADE20K, without an increase in computational cost during inference.
X-MAS: Extremely Large-Scale Multi-Modal Sensor Dataset for Outdoor Surveillance in Real Environments
Dec 30, 2022



In robotics and computer vision communities, extensive studies have been widely conducted regarding surveillance tasks, including human detection, tracking, and motion recognition with a camera. Additionally, deep learning algorithms are widely utilized in the aforementioned tasks as in other computer vision tasks. Existing public datasets are insufficient to develop learning-based methods that handle various surveillance for outdoor and extreme situations such as harsh weather and low illuminance conditions. Therefore, we introduce a new large-scale outdoor surveillance dataset named eXtremely large-scale Multi-modAl Sensor dataset (X-MAS) containing more than 500,000 image pairs and the first-person view data annotated by well-trained annotators. Moreover, a single pair contains multi-modal data (e.g. an IR image, an RGB image, a thermal image, a depth image, and a LiDAR scan). This is the first large-scale first-person view outdoor multi-modal dataset focusing on surveillance tasks to the best of our knowledge. We present an overview of the proposed dataset with statistics and present methods of exploiting our dataset with deep learning-based algorithms. The latest information on the dataset and our study are available at https://github.com/lge-robot-navi, and the dataset will be available for download through a server.