 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRD: View-Invariant Representation through Dual-Axis Transformation for Cross-View Pose Estimation
Mar 13, 2026Accurate global localization is crucial for autonomous driving and robotics, but GNSS-based approaches often degrade due to occlusion and multipath effects. As an emerging alternative, cross-view pose estimation predicts the 3-DoF camera pose corresponding to a ground-view image with respect to a geo-referenced satellite image. However, existing methods struggle to bridge the significant viewpoint gap between the ground and satellite views mainly due to limited spatial correspondences. We propose a novel cross-view pose estimation method that constructs view-invariant representations through dual-axis transformation (VIRD). VIRD first applies a polar transformation to the satellite view to establish horizontal correspondence, then uses context-enhanced positional attention on the ground and polar-transformed satellite features to resolve vertical misalignment, explicitly mitigating the viewpoint gap. A view-reconstruction loss is introduced to strengthen the view invariance further, encouraging the derived representations to reconstruct the original and cross-view images. Experiments on the KITTI and VIGOR datasets demonstrate that VIRD outperforms the state-of-the-art methods without orientation priors, reducing median position and orientation errors by 50.7% and 76.5% on KITTI, and 18.0% and 46.8% on VIGOR, respectively.
CoCoA-Mix: Confusion-and-Confidence-Aware Mixture Model for Context Optimization
Jun 09, 2025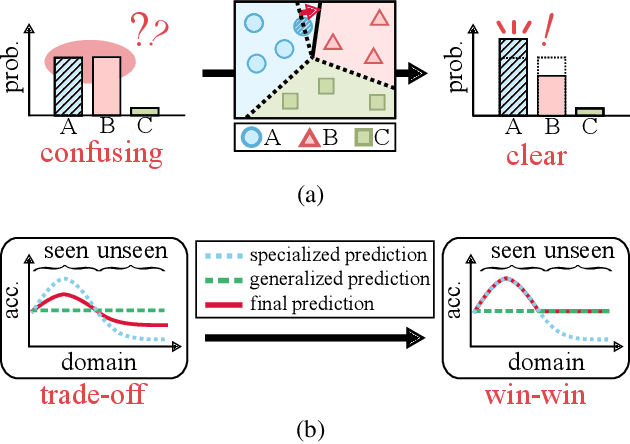



Prompt tuning, which adapts vision-language models by freezing model parameters and optimizing only the prompt, has proven effective for task-specific adaptations. The core challenge in prompt tuning is improving specialization for a specific task and generalization for unseen domains. However, frozen encoders often produce misaligned features, leading to confusion between classes and limiting specialization. To overcome this issue, we propose a confusion-aware loss (CoA-loss) that improves specialization by refining the decision boundaries between confusing classes. Additionally, we mathematically demonstrate that a mixture model can enhance generalization without compromising specialization. This is achieved using confidence-aware weights (CoA-weights), which adjust the weights of each prediction in the mixture model based on its confidence within the class domains. Extensive experiments show that CoCoA-Mix, a mixture model with CoA-loss and CoA-weights, outperforms state-of-the-art methods by enhancing specialization and generalization. Our code is publicly available at https://github.com/url-kaist/CoCoA-Mix.
PIDLoc: Cross-View Pose Optimization Network Inspired by PID Controllers
Mar 04, 2025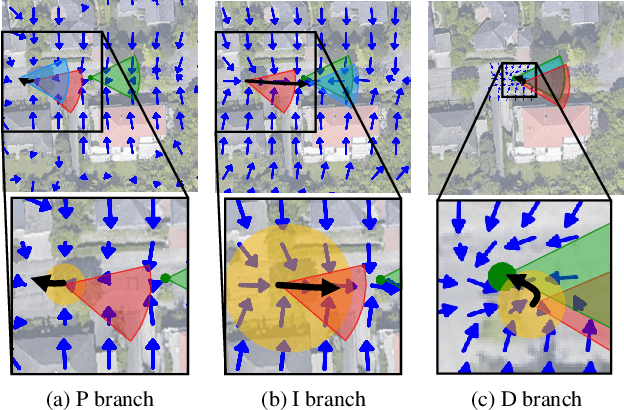
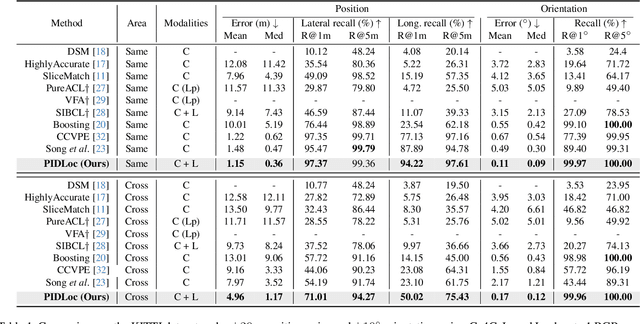
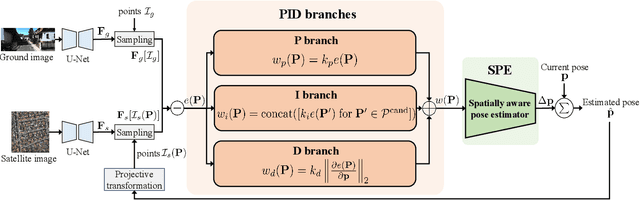
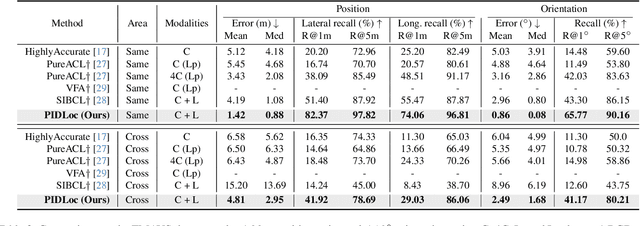
Accurate localization is essential for autonomous driving, but GNSS-based methods struggle in challenging environments such as urban canyons. Cross-view pose optimization offers an effective solution by directly estimating vehicle pose using satellite-view images. However, existing methods primarily rely on cross-view features at a given pose, neglecting fine-grained contexts for precision and global contexts for robustness against large initial pose errors. To overcome these limitations, we propose PIDLoc, a novel cross-view pose optimization approach inspired by the proportional-integral-derivative (PID) controller. Using RGB images and LiDAR, the PIDLoc comprises the PID branches to model cross-view feature relationships and the spatially aware pose estimator (SPE) to estimate the pose from these relationships. The PID branches leverage feature differences for local context (P), aggregated feature differences for global context (I), and gradients of feature differences for precise pose adjustment (D) to enhance localization accuracy under large initial pose errors. Integrated with the PID branches, the SPE captures spatial relationships within the PID-branch features for consistent localization. Experimental results demonstrate that the PIDLoc achieves state-of-the-art performance in cross-view pose estimation for the KITTI dataset, reducing position error by $37.8\%$ compared with the previous state-of-the-art.
Contextrast: Contextual Contrastive Learning for Semantic Segmentation
Apr 16, 2024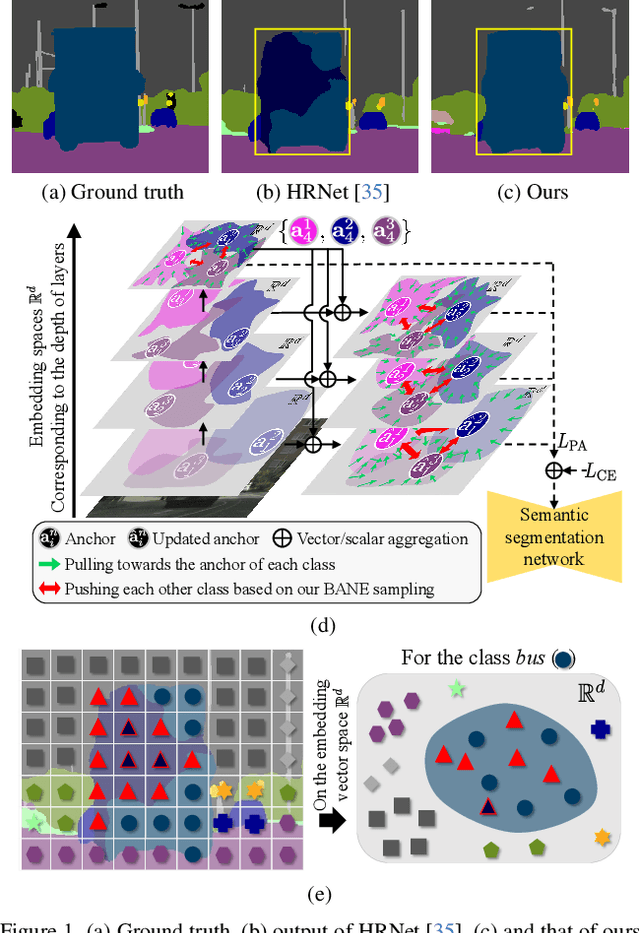

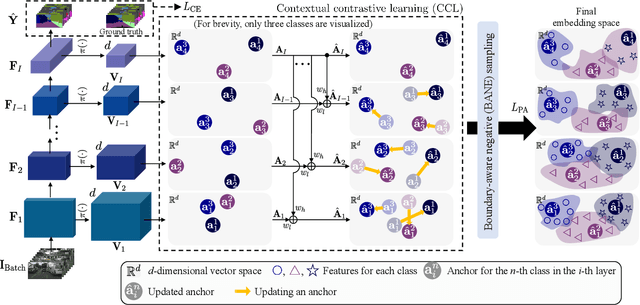
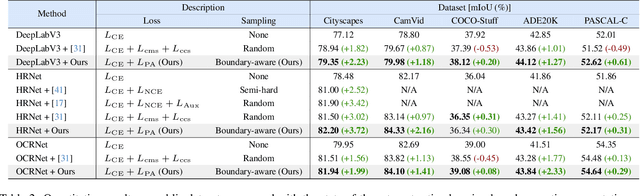
Despite great improvements in semantic segmentation, challenges persist because of the lack of local/global contexts and the relationship between them. In this paper, we propose Contextrast, a contrastive learning-based semantic segmentation method that allows to capture local/global contexts and comprehend their relationships. Our proposed method comprises two parts: a) contextual contrastive learning (CCL) and b) boundary-aware negative (BANE) sampling. Contextual contrastive learning obtains local/global context from multi-scale feature aggregation and inter/intra-relationship of features for better discrimination capabilities. Meanwhile, BANE sampling selects embedding features along the boundaries of incorrectly predicted regions to employ them as harder negative samples on our contrastive learning, resolving segmentation issues along the boundary region by exploiting fine-grained details. We demonstrate that our Contextrast substantially enhances the performance of semantic segmentation networks, outperforming state-of-the-art contrastive learning approaches on diverse public datasets, e.g. Cityscapes, CamVid, PASCAL-C, COCO-Stuff, and ADE20K, without an increase in computational cost during inference.
Domain Generalization with Vital Phase Augmentation
Jan 08, 2024Deep neural networks have shown remarkable performance in image classification. However, their performance significantly deteriorates with corrupted input data. Domain generalization methods have been proposed to train robust models against out-of-distribution data. Data augmentation in the frequency domain is one of such approaches that enable a model to learn phase features to establish domain-invariant representations. This approach changes the amplitudes of the input data while preserving the phases. However, using fixed phases leads to susceptibility to phase fluctuations because amplitudes and phase fluctuations commonly occur in out-of-distribution. In this study, to address this problem, we introduce an approach using finite variation of the phases of input data rather than maintaining fixed phases. Based on the assumption that the degree of domain-invariant features varies for each phase, we propose a method to distinguish phases based on this degree. In addition, we propose a method called vital phase augmentation (VIPAug) that applies the variation to the phases differently according to the degree of domain-invariant features of given phases. The model depends more on the vital phases that contain more domain-invariant features for attaining robustness to amplitude and phase fluctuations. We present experimental evaluations of our proposed approach, which exhibited improved performance for both clean and corrupted data. VIPAug achieved SOTA performance on the benchmark CIFAR-10 and CIFAR-100 datasets, as well as near-SOTA performance on the ImageNet-100 and ImageNet datasets. Our code is available at https://github.com/excitedkid/vipaug.
Object-Aware Domain Generalization for Object Detection
Dec 19, 2023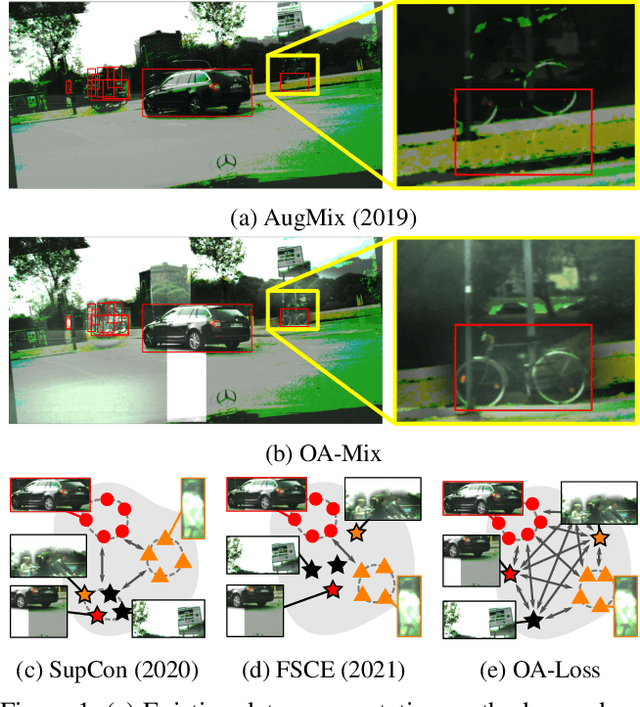
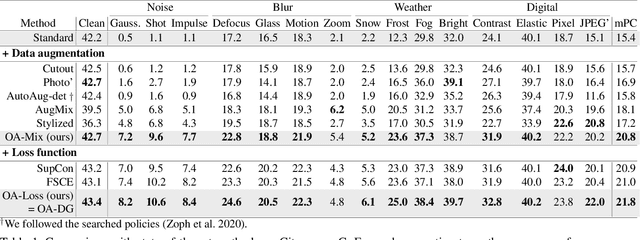
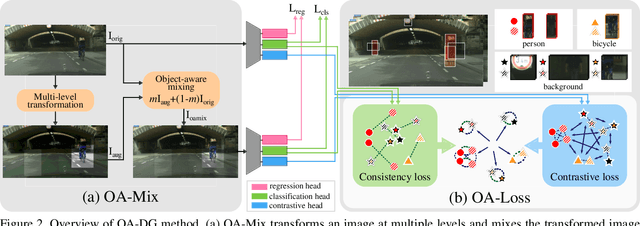
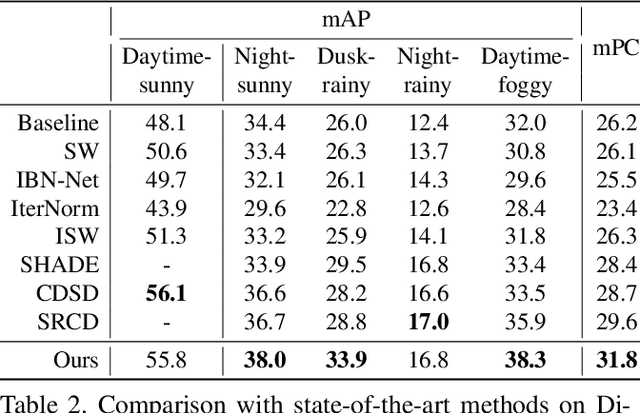
Single-domain generalization (S-DG) aims to generalize a model to unseen environments with a single-source domain. However, most S-DG approaches have been conducted in the field of classification. When these approaches are applied to object detection, the semantic features of some objects can be damaged, which can lead to imprecise object localization and misclassification. To address these problems, we propose an object-aware domain generalization (OA-DG) method for single-domain generalization in object detection. Our method consists of data augmentation and training strategy, which are called OA-Mix and OA-Loss, respectively. OA-Mix generates multi-domain data with multi-level transformation and object-aware mixing strategy. OA-Loss enables models to learn domain-invariant representations for objects and backgrounds from the original and OA-Mixed images. Our proposed method outperforms state-of-the-art works on standard benchmarks. Our code is available at https://github.com/WoojuLee24/OA-DG.
Adversarial Attack for Asynchronous Event-based Data
Dec 27, 2021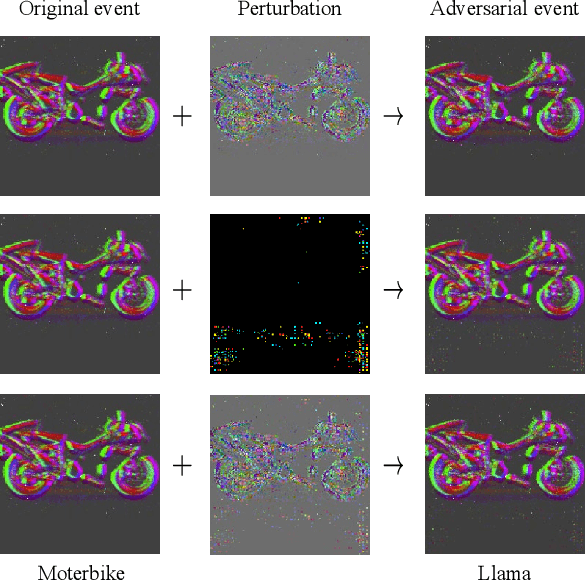
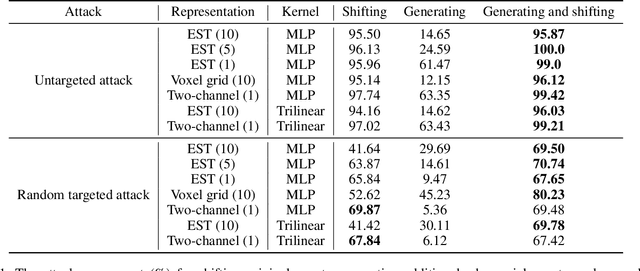
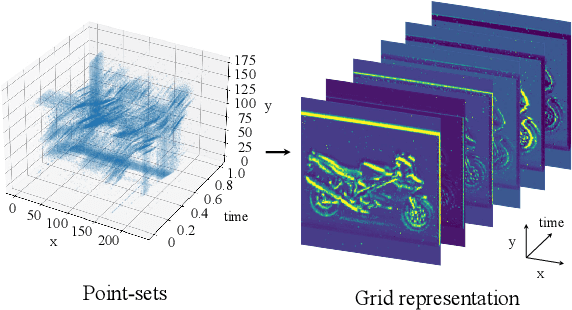
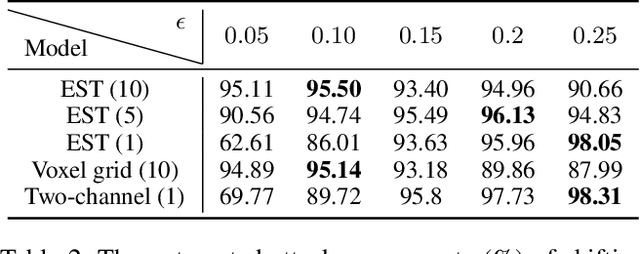
Deep neural networks (DNNs) are vulnerable to adversarial examples that are carefully designed to cause the deep learning model to make mistakes. Adversarial examples of 2D images and 3D point clouds have been extensively studied, but studies on event-based data are limited. Event-based data can be an alternative to a 2D image under high-speed movements, such as autonomous driving. However, the given adversarial events make the current deep learning model vulnerable to safety issues. In this work, we generate adversarial examples and then train the robust models for event-based data, for the first time. Our algorithm shifts the time of the original events and generates additional adversarial events. Additional adversarial events are generated in two stages. First, null events are added to the event-based data to generate additional adversarial events. The perturbation size can be controlled with the number of null events. Second, the location and time of additional adversarial events are set to mislead DNNs in a gradient-based attack. Our algorithm achieves an attack success rate of 97.95\% on the N-Caltech101 dataset. Furthermore, the adversarial training model improves robustness on the adversarial event data compared to the original model.