 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Optimal Video Moment without Training: Gaussian Boundary Optimization for Weakly Supervised Video Grounding
Feb 03, 2026Weakly supervised temporal video grounding aims to localize query-relevant segments in untrimmed videos using only video-sentence pairs, without requiring ground-truth segment annotations that specify exact temporal boundaries. Recent approaches tackle this task by utilizing Gaussian-based temporal proposals to represent query-relevant segments. However, their inference strategies rely on heuristic mappings from Gaussian parameters to segment boundaries, resulting in suboptimal localization performance. To address this issue, we propose Gaussian Boundary Optimization (GBO), a novel inference framework that predicts segment boundaries by solving a principled optimization problem that balances proposal coverage and segment compactness. We derive a closed-form solution for this problem and rigorously analyze the optimality conditions under varying penalty regimes. Beyond its theoretical foundations, GBO offers several practical advantages: it is training-free and compatible with both single-Gaussian and mixture-based proposal architectures. Our experiments show that GBO significantly improves localization, achieving state-of-the-art results across standard benchmarks. Extensive experiments demonstrate the efficiency and generalizability of GBO across various proposal schemes. The code is available at \href{https://github.com/sunoh-kim/gbo}{https://github.com/sunoh-kim/gbo}.
Enhancing Weakly Supervised Video Grounding via Diverse Inference Strategies for Boundary and Prediction Selection
Mar 29, 2025Weakly supervised video grounding aims to localize temporal boundaries relevant to a given query without explicit ground-truth temporal boundaries. While existing methods primarily use Gaussian-based proposals, they overlook the importance of (1) boundary prediction and (2) top-1 prediction selection during inference. In their boundary prediction, boundaries are simply set at half a standard deviation away from a Gaussian mean on both sides, which may not accurately capture the optimal boundaries. In the top-1 prediction process, these existing methods rely heavily on intersections with other proposals, without considering the varying quality of each proposal. To address these issues, we explore various inference strategies by introducing (1) novel boundary prediction methods to capture diverse boundaries from multiple Gaussians and (2) new selection methods that take proposal quality into account. Extensive experiments on the ActivityNet Captions and Charades-STA datasets validate the effectiveness of our inference strategies, demonstrating performance improvements without requiring additional training.
Confidence-Based Feature Imputation for Graphs with Partially Known Features
May 29, 2023



This paper investigates a missing feature imputation problem for graph learning tasks. Several methods have previously addressed learning tasks on graphs with missing features. However, in cases of high rates of missing features, they were unable to avoid significant performance degradation. To overcome this limitation, we introduce a novel concept of channel-wise confidence in a node feature, which is assigned to each imputed channel feature of a node for reflecting certainty of the imputation. We then design pseudo-confidence using the channel-wise shortest path distance between a missing-feature node and its nearest known-feature node to replace unavailable true confidence in an actual learning process. Based on the pseudo-confidence, we propose a novel feature imputation scheme that performs channel-wise inter-node diffusion and node-wise inter-channel propagation. The scheme can endure even at an exceedingly high missing rate (e.g., 99.5\%) and it achieves state-of-the-art accuracy for both semi-supervised node classification and link prediction on various datasets containing a high rate of missing features. Codes are available at https://github.com/daehoum1/pcfi.
RoCOCO: Robust Benchmark MS-COCO to Stress-test Robustness of Image-Text Matching Models
Apr 21, 2023Recently, large-scale vision-language pre-training models and visual semantic embedding methods have significantly improved image-text matching (ITM) accuracy on MS COCO 5K test set. However, it is unclear how robust these state-of-the-art (SOTA) models are when using them in the wild. In this paper, we propose a novel evaluation benchmark to stress-test the robustness of ITM models. To this end, we add various fooling images and captions to a retrieval pool. Specifically, we change images by inserting unrelated images, and change captions by substituting a noun, which can change the meaning of a sentence. We discover that just adding these newly created images and captions to the test set can degrade performances (i.e., Recall@1) of a wide range of SOTA models (e.g., 81.9% $\rightarrow$ 64.5% in BLIP, 66.1% $\rightarrow$ 37.5% in VSE$\infty$). We expect that our findings can provide insights for improving the robustness of the vision-language models and devising more diverse stress-test methods in cross-modal retrieval task. Source code and dataset will be available at https://github.com/pseulki/rococo.
X-MAS: Extremely Large-Scale Multi-Modal Sensor Dataset for Outdoor Surveillance in Real Environments
Dec 30, 2022



In robotics and computer vision communities, extensive studies have been widely conducted regarding surveillance tasks, including human detection, tracking, and motion recognition with a camera. Additionally, deep learning algorithms are widely utilized in the aforementioned tasks as in other computer vision tasks. Existing public datasets are insufficient to develop learning-based methods that handle various surveillance for outdoor and extreme situations such as harsh weather and low illuminance conditions. Therefore, we introduce a new large-scale outdoor surveillance dataset named eXtremely large-scale Multi-modAl Sensor dataset (X-MAS) containing more than 500,000 image pairs and the first-person view data annotated by well-trained annotators. Moreover, a single pair contains multi-modal data (e.g. an IR image, an RGB image, a thermal image, a depth image, and a LiDAR scan). This is the first large-scale first-person view outdoor multi-modal dataset focusing on surveillance tasks to the best of our knowledge. We present an overview of the proposed dataset with statistics and present methods of exploiting our dataset with deep learning-based algorithms. The latest information on the dataset and our study are available at https://github.com/lge-robot-navi, and the dataset will be available for download through a server.
Class-Attentive Diffusion Network for Semi-Supervised Classification
Jun 18, 2020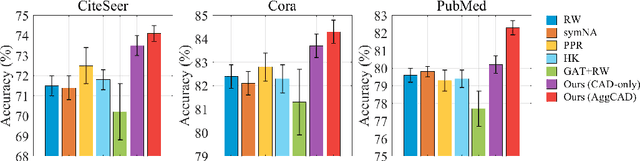

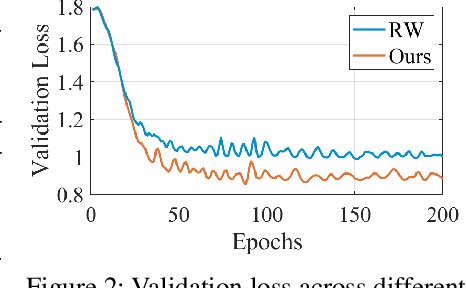

We propose Aggregation with Class-Attentive Diffusion (AggCAD), a novel aggregation scheme for semi-supervised classification on graphs, which enables the model to embed more favorable node representations for better class separation. To this end, we propose a novel Class-Attentive Diffusion (CAD) which strengthens attention to intra-class nodes and attenuates attention to inter-class nodes. In contrast to the existing diffusion methods with a transition matrix determined solely by the graph structure, CAD considers both the node features and the graph structure with the design of the class-attentive transition matrix which utilizes the classifier. In addition, we further propose an adaptive scheme for AggCAD that leverages different reflection ratios of the diffusion result for each node depending on the local class-context. As the main advantage, AggCAD alleviates the problem of undesired mixing of inter-class features caused by discrepancies between node labels and the graph structure. Built on AggCAD, we construct Class-Attentive Diffusion Network for semi-supervised classification. Comprehensive experiments demonstrate the validity of AggCAD and the results show that the proposed method significantly outperforms the state-of-the-art methods on three benchmark datasets.