 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Finely-Categorized Image-Text Retrieval by Selecting Hard Negative Unpaired Samples
May 25, 2024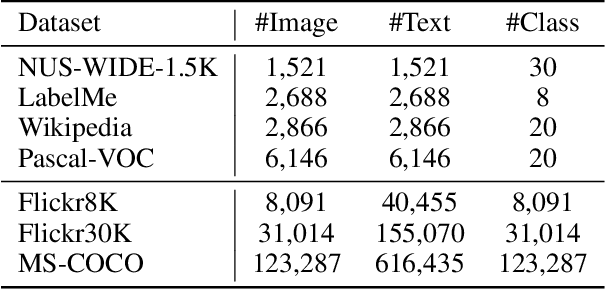

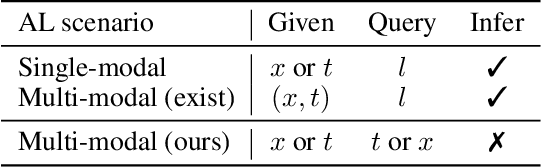
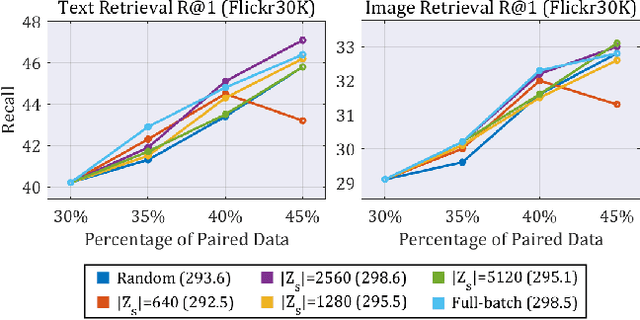
Securing a sufficient amount of paired data is important to train an image-text retrieval (ITR) model, but collecting paired data is very expensive. To address this issue, in this paper, we propose an active learning algorithm for ITR that can collect paired data cost-efficiently. Previous studies assume that image-text pairs are given and their category labels are asked to the annotator. However, in the recent ITR studies, the importance of category label is decreased since a retrieval model can be trained with only image-text pairs. For this reason, we set up an active learning scenario where unpaired images (or texts) are given and the annotator provides corresponding texts (or images) to make paired data. The key idea of the proposed AL algorithm is to select unpaired images (or texts) that can be hard negative samples for existing texts (or images). To this end, we introduce a novel scoring function to choose hard negative samples. We validate the effectiveness of the proposed method on Flickr30K and MS-COCO datasets.
Over-Fit: Noisy-Label Detection based on the Overfitted Model Property
Jun 14, 2021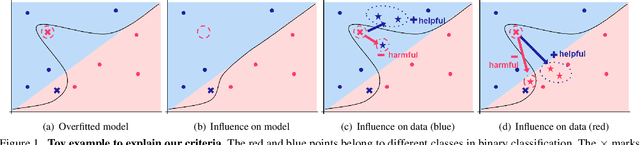
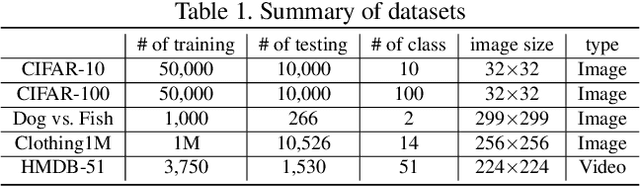
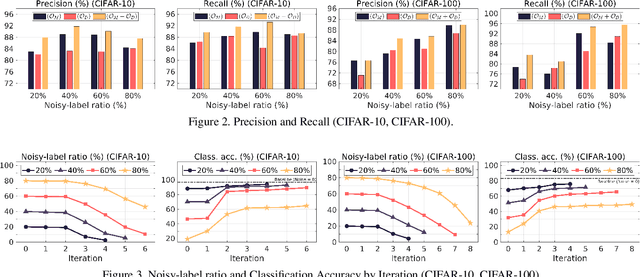
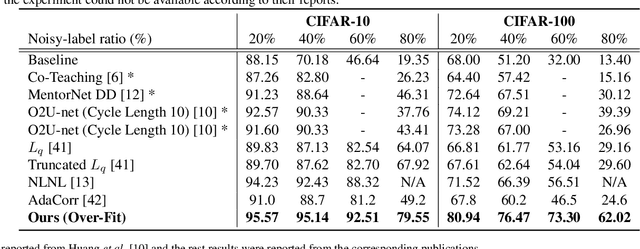
Due to the increasing need to handle the noisy label problem in a massive dataset, learning with noisy labels has received much attention in recent years. As a promising approach, there have been recent studies to select clean training data by finding small-loss instances before a deep neural network overfits the noisy-label data. However, it is challenging to prevent overfitting. In this paper, we propose a novel noisy-label detection algorithm by employing the property of overfitting on individual data points. To this end, we present two novel criteria that statistically measure how much each training sample abnormally affects the model and clean validation data. Using the criteria, our iterative algorithm removes noisy-label samples and retrains the model alternately until no further performance improvement is made. In experiments on multiple benchmark datasets, we demonstrate the validity of our algorithm and show that our algorithm outperforms the state-of-the-art methods when the exact noise rates are not given. Furthermore, we show that our method can not only be expanded to a real-world video dataset but also can be viewed as a regularization method to solve problems caused by overfitting.
Class-Attentive Diffusion Network for Semi-Supervised Classification
Jun 18, 2020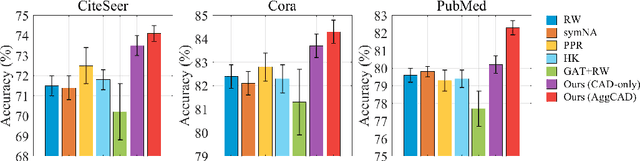


We propose Aggregation with Class-Attentive Diffusion (AggCAD), a novel aggregation scheme for semi-supervised classification on graphs, which enables the model to embed more favorable node representations for better class separation. To this end, we propose a novel Class-Attentive Diffusion (CAD) which strengthens attention to intra-class nodes and attenuates attention to inter-class nodes. In contrast to the existing diffusion methods with a transition matrix determined solely by the graph structure, CAD considers both the node features and the graph structure with the design of the class-attentive transition matrix which utilizes the classifier. In addition, we further propose an adaptive scheme for AggCAD that leverages different reflection ratios of the diffusion result for each node depending on the local class-context. As the main advantage, AggCAD alleviates the problem of undesired mixing of inter-class features caused by discrepancies between node labels and the graph structure. Built on AggCAD, we construct Class-Attentive Diffusion Network for semi-supervised classification. Comprehensive experiments demonstrate the validity of AggCAD and the results show that the proposed method significantly outperforms the state-of-the-art methods on three benchmark datasets.
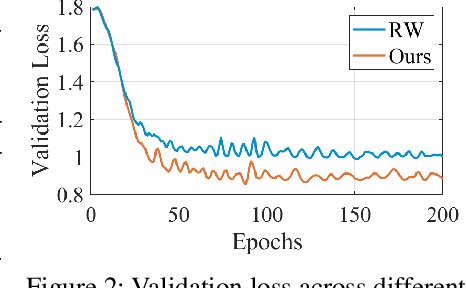
Cross-modal Variational Auto-encoder with Distributed Latent Spaces and Associators
May 30, 2019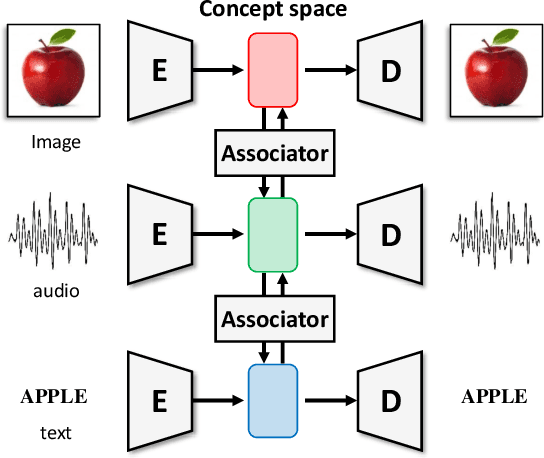
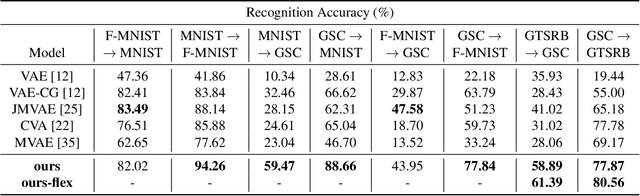
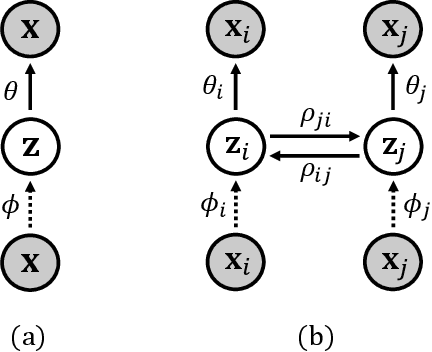
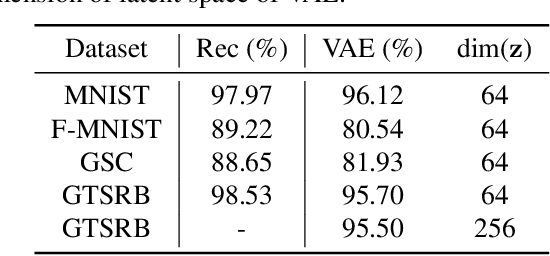
In this paper, we propose a novel structure for a cross-modal data association, which is inspired by the recent research on the associative learning structure of the brain. We formulate the cross-modal association in Bayesian inference framework realized by a deep neural network with multiple variational auto-encoders and variational associators. The variational associators transfer the latent spaces between auto-encoders that represent different modalities. The proposed structure successfully associates even heterogeneous modal data and easily incorporates the additional modality to the entire network via the proposed cross-modal associator. Furthermore, the proposed structure can be trained with only a small amount of paired data since auto-encoders can be trained by unsupervised manner. Through experiments, the effectiveness of the proposed structure is validated on various datasets including visual and auditory data.
Backbone Can Not be Trained at Once: Rolling Back to Pre-trained Network for Person Re-Identification
Jan 18, 2019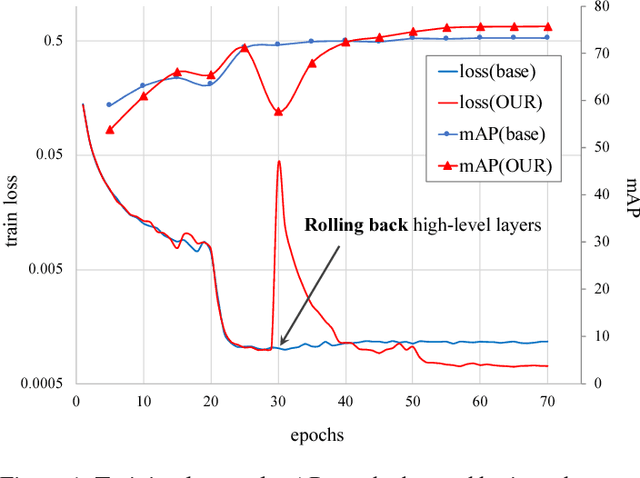
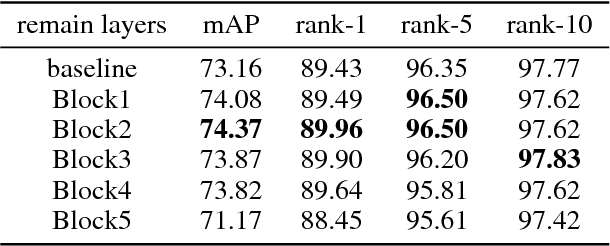
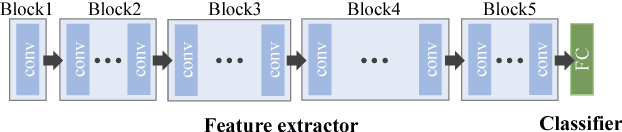
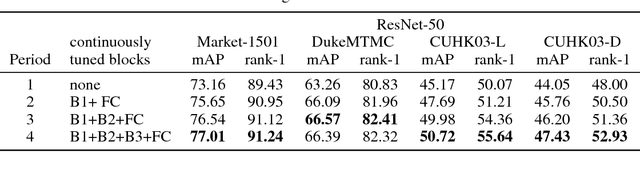
In person re-identification (ReID) task, because of its shortage of trainable dataset, it is common to utilize fine-tuning method using a classification network pre-trained on a large dataset. However, it is relatively difficult to sufficiently fine-tune the low-level layers of the network due to the gradient vanishing problem. In this work, we propose a novel fine-tuning strategy that allows low-level layers to be sufficiently trained by rolling back the weights of high-level layers to their initial pre-trained weights. Our strategy alleviates the problem of gradient vanishing in low-level layers and robustly trains the low-level layers to fit the ReID dataset, thereby increasing the performance of ReID tasks. The improved performance of the proposed strategy is validated via several experiments. Furthermore, without any add-ons such as pose estimation or segmentation, our strategy exhibits state-of-the-art performance using only vanilla deep convolutional neural network architecture.