 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence-Balanced Loss for Imbalanced Visual Classification
Oct 06, 2021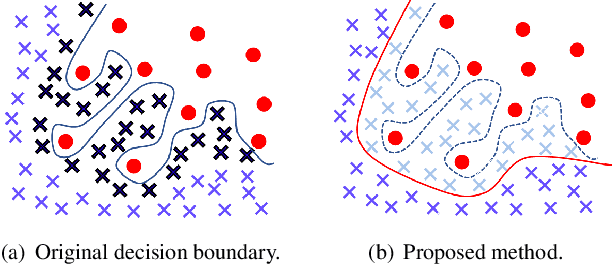
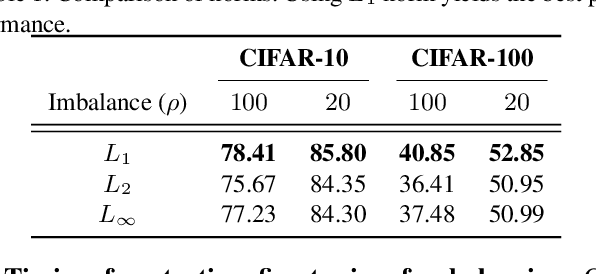
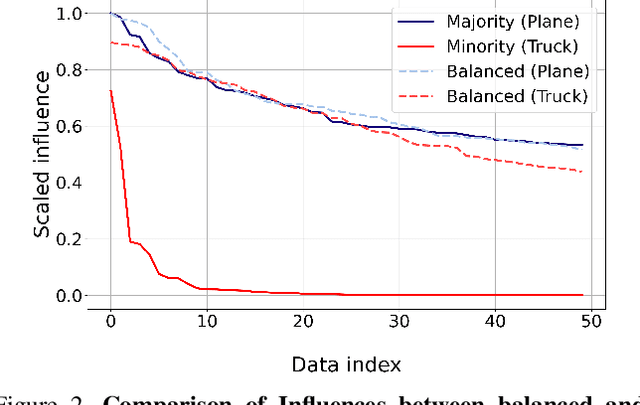
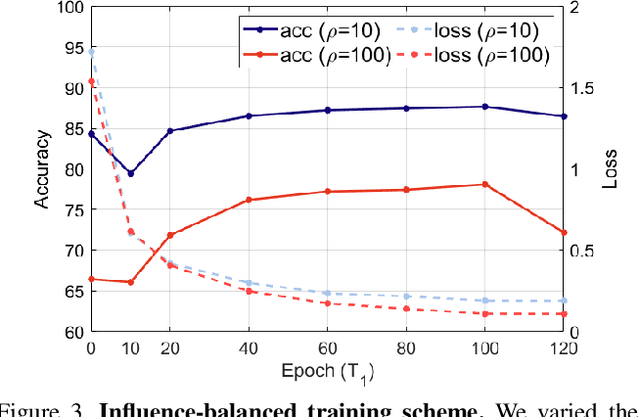
In this paper, we propose a balancing training method to address problems in imbalanced data learning. To this end, we derive a new loss used in the balancing training phase that alleviates the influence of samples that cause an overfitted decision boundary. The proposed loss efficiently improves the performance of any type of imbalance learning methods. In experiments on multiple benchmark data sets, we demonstrate the validity of our method and reveal that the proposed loss outperforms the state-of-the-art cost-sensitive loss methods. Furthermore, since our loss is not restricted to a specific task, model, or training method, it can be easily used in combination with other recent re-sampling, meta-learning, and cost-sensitive learning methods for class-imbalance problems.
* Published in ICCV 2021
Class-Attentive Diffusion Network for Semi-Supervised Classification
Jun 18, 2020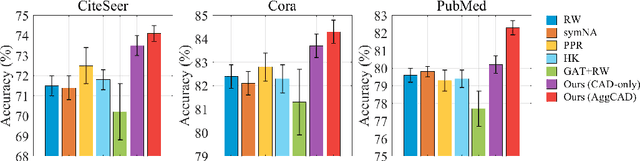

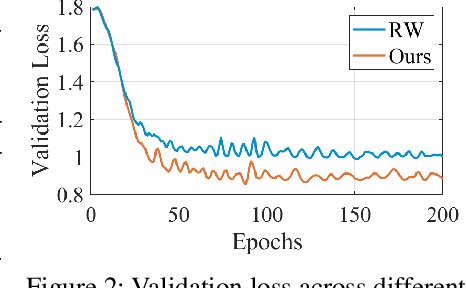

We propose Aggregation with Class-Attentive Diffusion (AggCAD), a novel aggregation scheme for semi-supervised classification on graphs, which enables the model to embed more favorable node representations for better class separation. To this end, we propose a novel Class-Attentive Diffusion (CAD) which strengthens attention to intra-class nodes and attenuates attention to inter-class nodes. In contrast to the existing diffusion methods with a transition matrix determined solely by the graph structure, CAD considers both the node features and the graph structure with the design of the class-attentive transition matrix which utilizes the classifier. In addition, we further propose an adaptive scheme for AggCAD that leverages different reflection ratios of the diffusion result for each node depending on the local class-context. As the main advantage, AggCAD alleviates the problem of undesired mixing of inter-class features caused by discrepancies between node labels and the graph structure. Built on AggCAD, we construct Class-Attentive Diffusion Network for semi-supervised classification. Comprehensive experiments demonstrate the validity of AggCAD and the results show that the proposed method significantly outperforms the state-of-the-art methods on three benchmark datasets.
Backbone Can Not be Trained at Once: Rolling Back to Pre-trained Network for Person Re-Identification
Jan 18, 2019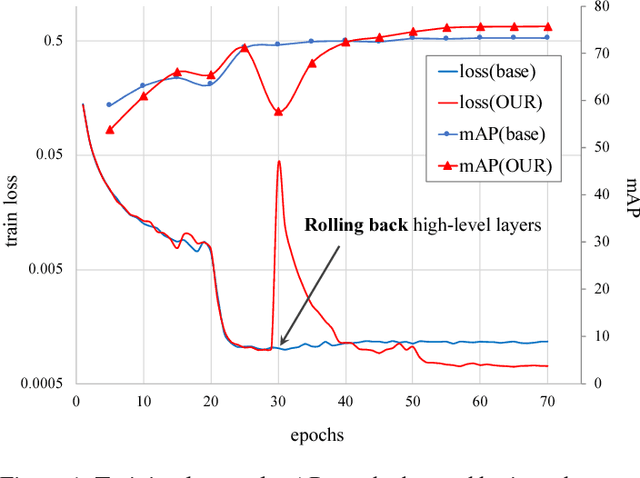
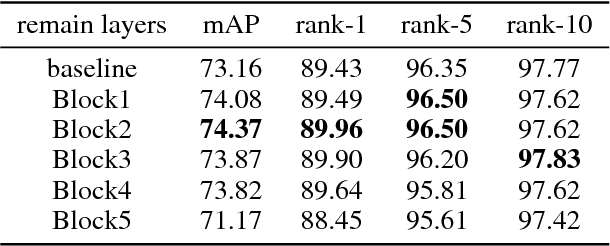
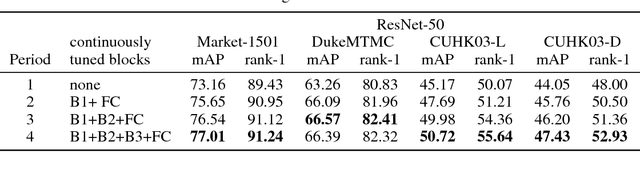
In person re-identification (ReID) task, because of its shortage of trainable dataset, it is common to utilize fine-tuning method using a classification network pre-trained on a large dataset. However, it is relatively difficult to sufficiently fine-tune the low-level layers of the network due to the gradient vanishing problem. In this work, we propose a novel fine-tuning strategy that allows low-level layers to be sufficiently trained by rolling back the weights of high-level layers to their initial pre-trained weights. Our strategy alleviates the problem of gradient vanishing in low-level layers and robustly trains the low-level layers to fit the ReID dataset, thereby increasing the performance of ReID tasks. The improved performance of the proposed strategy is validated via several experiments. Furthermore, without any add-ons such as pose estimation or segmentation, our strategy exhibits state-of-the-art performance using only vanilla deep convolutional neural network architecture.