 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchical Semantic Classification by Grounding on Consistent Image Segmentations
Jun 17, 2024



Hierarchical semantic classification requires the prediction of a taxonomy tree instead of a single flat level of the tree, where both accuracies at individual levels and consistency across levels matter. We can train classifiers for individual levels, which has accuracy but not consistency, or we can train only the finest level classification and infer higher levels, which has consistency but not accuracy. Our key insight is that hierarchical recognition should not be treated as multi-task classification, as each level is essentially a different task and they would have to compromise with each other, but be grounded on image segmentations that are consistent across semantic granularities. Consistency can in fact improve accuracy. We build upon recent work on learning hierarchical segmentation for flat-level recognition, and extend it to hierarchical recognition. It naturally captures the intuition that fine-grained recognition requires fine image segmentation whereas coarse-grained recognition requires coarse segmentation; they can all be integrated into one recognition model that drives fine-to-coarse internal visual parsing.Additionally, we introduce a Tree-path KL Divergence loss to enforce consistent accurate predictions across levels. Our extensive experimentation and analysis demonstrate our significant gains on predicting an accurate and consistent taxonomy tree.
Confidence-Based Feature Imputation for Graphs with Partially Known Features
May 29, 2023



This paper investigates a missing feature imputation problem for graph learning tasks. Several methods have previously addressed learning tasks on graphs with missing features. However, in cases of high rates of missing features, they were unable to avoid significant performance degradation. To overcome this limitation, we introduce a novel concept of channel-wise confidence in a node feature, which is assigned to each imputed channel feature of a node for reflecting certainty of the imputation. We then design pseudo-confidence using the channel-wise shortest path distance between a missing-feature node and its nearest known-feature node to replace unavailable true confidence in an actual learning process. Based on the pseudo-confidence, we propose a novel feature imputation scheme that performs channel-wise inter-node diffusion and node-wise inter-channel propagation. The scheme can endure even at an exceedingly high missing rate (e.g., 99.5\%) and it achieves state-of-the-art accuracy for both semi-supervised node classification and link prediction on various datasets containing a high rate of missing features. Codes are available at https://github.com/daehoum1/pcfi.
RoCOCO: Robust Benchmark MS-COCO to Stress-test Robustness of Image-Text Matching Models
Apr 21, 2023Recently, large-scale vision-language pre-training models and visual semantic embedding methods have significantly improved image-text matching (ITM) accuracy on MS COCO 5K test set. However, it is unclear how robust these state-of-the-art (SOTA) models are when using them in the wild. In this paper, we propose a novel evaluation benchmark to stress-test the robustness of ITM models. To this end, we add various fooling images and captions to a retrieval pool. Specifically, we change images by inserting unrelated images, and change captions by substituting a noun, which can change the meaning of a sentence. We discover that just adding these newly created images and captions to the test set can degrade performances (i.e., Recall@1) of a wide range of SOTA models (e.g., 81.9% $\rightarrow$ 64.5% in BLIP, 66.1% $\rightarrow$ 37.5% in VSE$\infty$). We expect that our findings can provide insights for improving the robustness of the vision-language models and devising more diverse stress-test methods in cross-modal retrieval task. Source code and dataset will be available at https://github.com/pseulki/rococo.
Online Continual Learning on a Contaminated Data Stream with Blurry Task Boundaries
Mar 30, 2022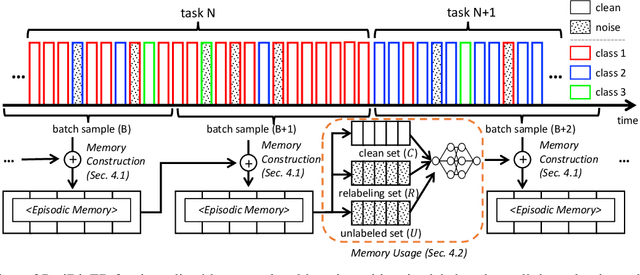
Learning under a continuously changing data distribution with incorrect labels is a desirable real-world problem yet challenging. A large body of continual learning (CL) methods, however, assumes data streams with clean labels, and online learning scenarios under noisy data streams are yet underexplored. We consider a more practical CL task setup of an online learning from blurry data stream with corrupted labels, where existing CL methods struggle. To address the task, we first argue the importance of both diversity and purity of examples in the episodic memory of continual learning models. To balance diversity and purity in the episodic memory, we propose a novel strategy to manage and use the memory by a unified approach of label noise aware diverse sampling and robust learning with semi-supervised learning. Our empirical validations on four real-world or synthetic noise datasets (CIFAR10 and 100, mini-WebVision, and Food-101N) exhibit that our method significantly outperforms prior arts in this realistic and challenging continual learning scenario. Code and data splits are available in https://github.com/clovaai/puridiver.
The Majority Can Help The Minority: Context-rich Minority Oversampling for Long-tailed Classification
Dec 03, 2021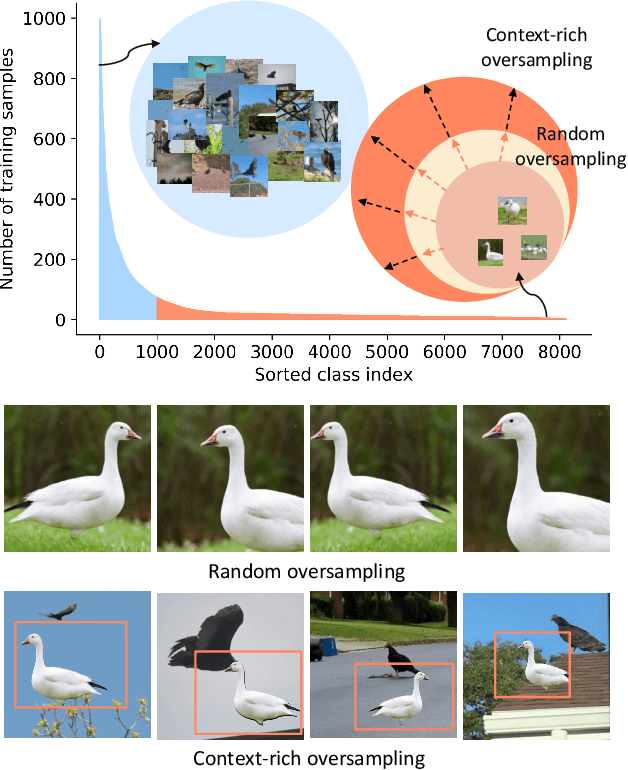
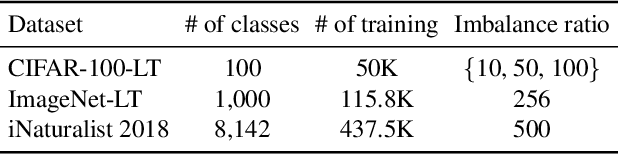
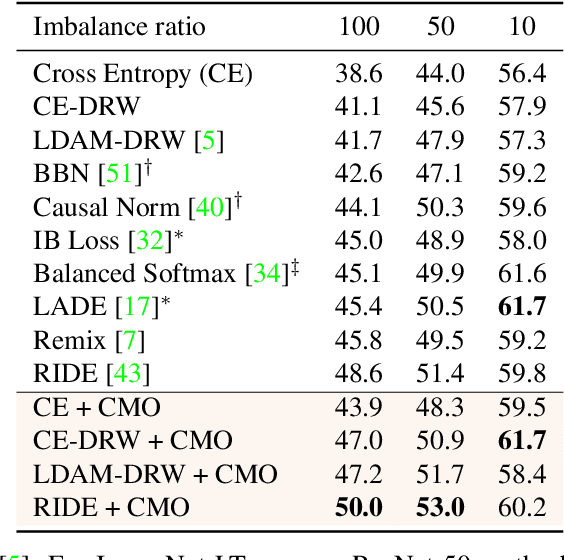

The problem of class imbalanced data lies in that the generalization performance of the classifier is deteriorated due to the lack of data of the minority classes. In this paper, we propose a novel minority over-sampling method to augment diversified minority samples by leveraging the rich context of the majority classes as background images. To diversify the minority samples, our key idea is to paste a foreground patch from a minority class to a background image from a majority class having affluent contexts. Our method is simple and can be easily combined with the existing long-tailed recognition methods. We empirically prove the effectiveness of the proposed oversampling method through extensive experiments and ablation studies. Without any architectural changes or complex algorithms, our method achieves state-of-the-art performance on various long-tailed classification benchmarks. Our code will be publicly available at link.
Influence-Balanced Loss for Imbalanced Visual Classification
Oct 06, 2021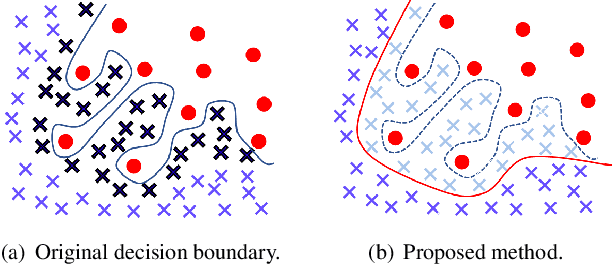
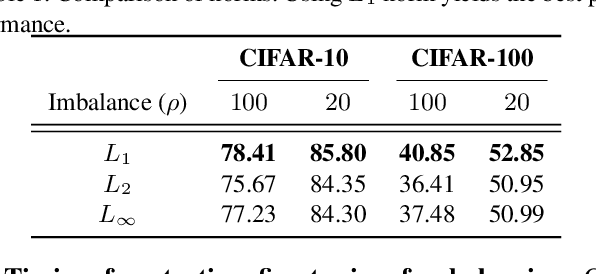
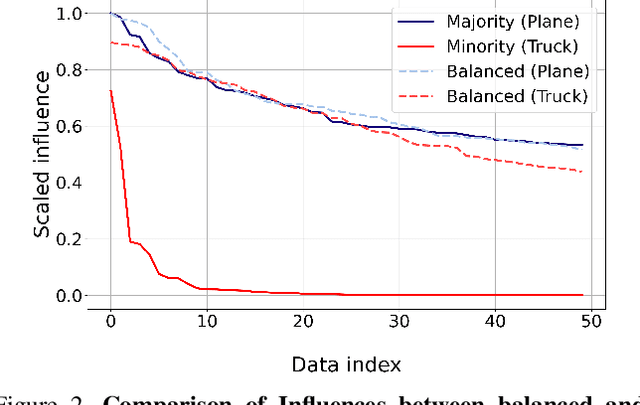
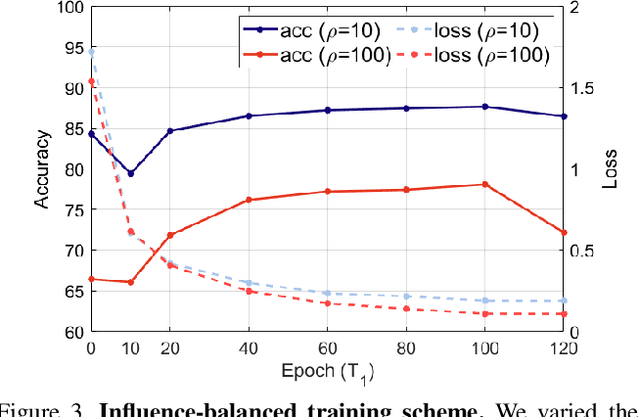
In this paper, we propose a balancing training method to address problems in imbalanced data learning. To this end, we derive a new loss used in the balancing training phase that alleviates the influence of samples that cause an overfitted decision boundary. The proposed loss efficiently improves the performance of any type of imbalance learning methods. In experiments on multiple benchmark data sets, we demonstrate the validity of our method and reveal that the proposed loss outperforms the state-of-the-art cost-sensitive loss methods. Furthermore, since our loss is not restricted to a specific task, model, or training method, it can be easily used in combination with other recent re-sampling, meta-learning, and cost-sensitive learning methods for class-imbalance problems.
* Published in ICCV 2021
Over-Fit: Noisy-Label Detection based on the Overfitted Model Property
Jun 14, 2021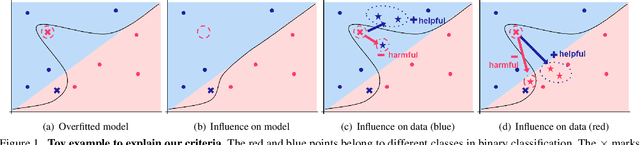
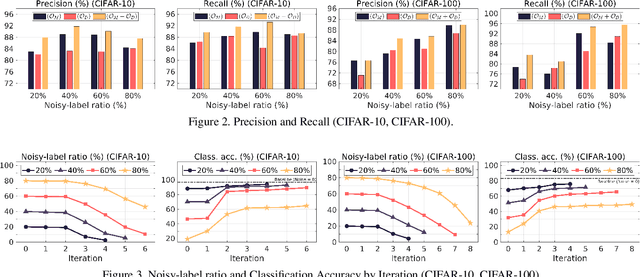
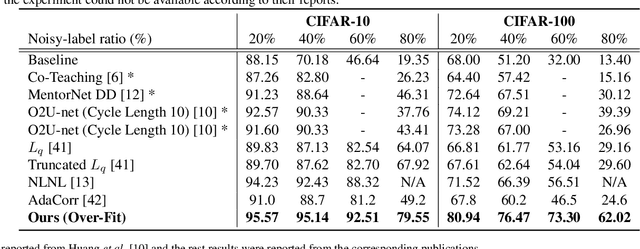
Due to the increasing need to handle the noisy label problem in a massive dataset, learning with noisy labels has received much attention in recent years. As a promising approach, there have been recent studies to select clean training data by finding small-loss instances before a deep neural network overfits the noisy-label data. However, it is challenging to prevent overfitting. In this paper, we propose a novel noisy-label detection algorithm by employing the property of overfitting on individual data points. To this end, we present two novel criteria that statistically measure how much each training sample abnormally affects the model and clean validation data. Using the criteria, our iterative algorithm removes noisy-label samples and retrains the model alternately until no further performance improvement is made. In experiments on multiple benchmark datasets, we demonstrate the validity of our algorithm and show that our algorithm outperforms the state-of-the-art methods when the exact noise rates are not given. Furthermore, we show that our method can not only be expanded to a real-world video dataset but also can be viewed as a regularization method to solve problems caused by overfitting.