 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Majority Can Help The Minority: Context-rich Minority Oversampling for Long-tailed Classification
Dec 03, 2021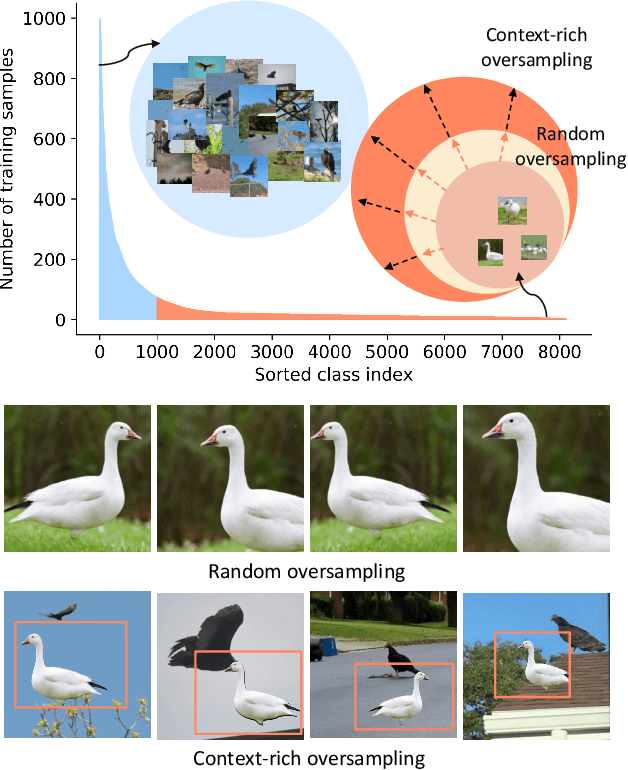
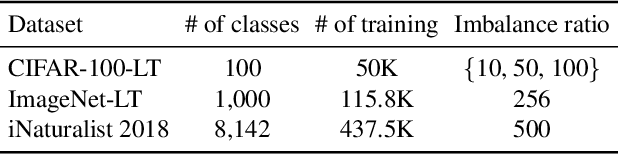
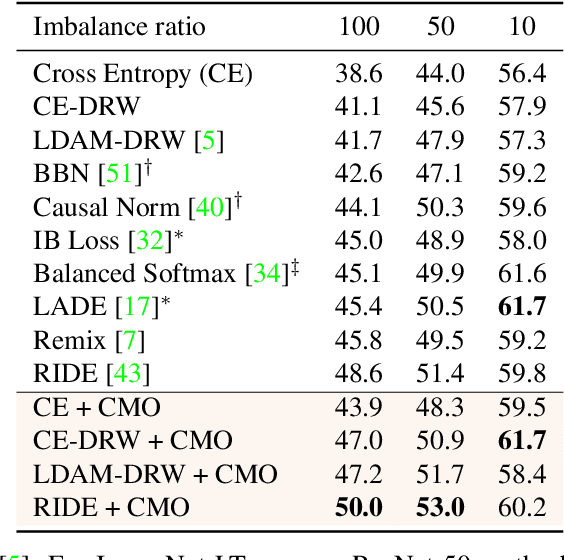

The problem of class imbalanced data lies in that the generalization performance of the classifier is deteriorated due to the lack of data of the minority classes. In this paper, we propose a novel minority over-sampling method to augment diversified minority samples by leveraging the rich context of the majority classes as background images. To diversify the minority samples, our key idea is to paste a foreground patch from a minority class to a background image from a majority class having affluent contexts. Our method is simple and can be easily combined with the existing long-tailed recognition methods. We empirically prove the effectiveness of the proposed oversampling method through extensive experiments and ablation studies. Without any architectural changes or complex algorithms, our method achieves state-of-the-art performance on various long-tailed classification benchmarks. Our code will be publicly available at link.
Self-Diagnosing GAN: Diagnosing Underrepresented Samples in Generative Adversarial Networks
Feb 24, 2021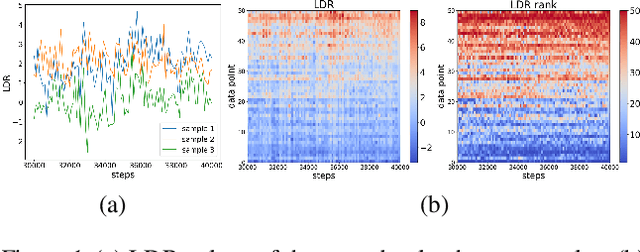
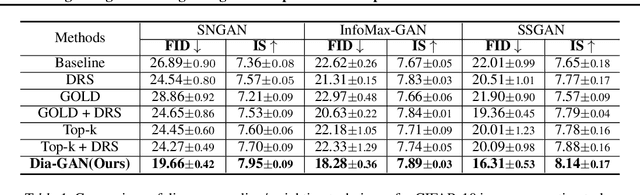
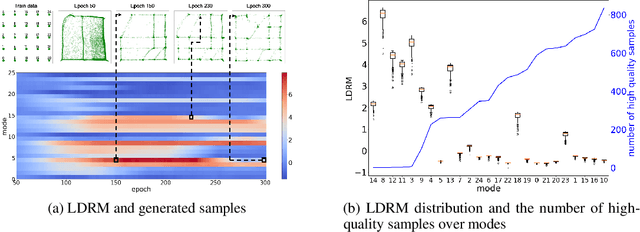

Despite remarkable performance in producing realistic samples, Generative Adversarial Networks (GANs) often produce low-quality samples near low-density regions of the data manifold. Recently, many techniques have been developed to improve the quality of generated samples, either by rejecting low-quality samples after training or by pre-processing the empirical data distribution before training, but at the cost of reduced diversity. To guarantee both the quality and the diversity, we propose a simple yet effective method to diagnose and emphasize underrepresented samples during training of a GAN. The main idea is to use the statistics of the discrepancy between the data distribution and the model distribution at each data instance. Based on the observation that the underrepresented samples have a high average discrepancy or high variability in discrepancy, we propose a method to emphasize those samples during training of a GAN. Our experimental results demonstrate that the proposed method improves GAN performance on various datasets, and it is especially effective in improving the quality of generated samples with minor features.
Disentangling Label Distribution for Long-tailed Visual Recognition
Dec 01, 2020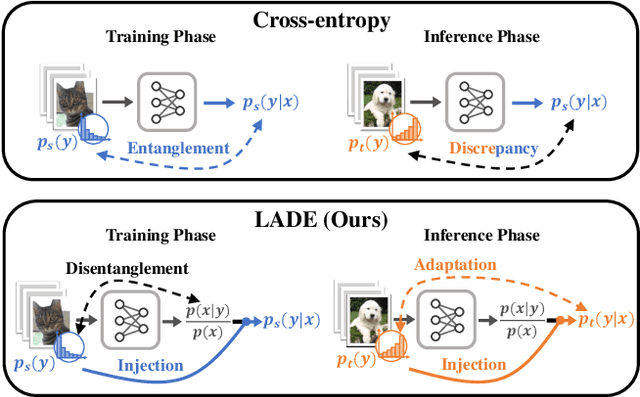


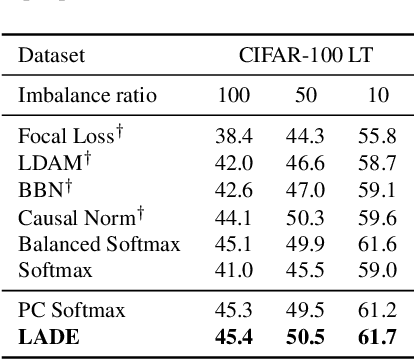
The current evaluation protocol of long-tailed visual recognition trains the classification model on the long-tailed source label distribution and evaluates its performance on the uniform target label distribution. Such protocol has questionable practicality since the target may also be long-tailed. Therefore, we formulate long-tailed visual recognition as a label shift problem where the target and source label distributions are different. One of the significant hurdles in dealing with the label shift problem is the entanglement between the source label distribution and the model prediction. In this paper, we focus on disentangling the source label distribution from the model prediction. We first introduce a simple baseline method that matches the target label distribution by post-processing the model prediction trained by the cross-entropy loss and the Softmax function. Although this method surpasses state-of-the-art methods on benchmark datasets, it can be further improved by directly disentangling the source label distribution from the model prediction in the training phase. Thus, we propose a novel method, LAbel distribution DisEntangling (LADE) loss based on the optimal bound of Donsker-Varadhan representation. LADE achieves state-of-the-art performance on benchmark datasets such as CIFAR-100-LT, Places-LT, ImageNet-LT, and iNaturalist 2018. Moreover, LADE outperforms existing methods on various shifted target label distributions, showing the general adaptability of our proposed method.