 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Understanding Adversarial Distillation: Why Robust Teachers Fail
May 21, 2026Adversarial Distillation aims to enhance student robustness by guiding the student with a robust teacher's soft labels within the min-max adversarial training framework, yet its success is notoriously inconsistent: a more robust teacher often fails to improve, or even harms, the student's robust generalization. In this paper, we identify a key mechanism of this teacher dependency: the misalignment between the teacher's supervisory confidence and the student's representational limitations on a consistent subset of training data -- the Robustly Unlearnable Set. We present a theoretical framework analyzing the feature learning dynamics of a two-layer neural network, demonstrating that this mismatch creates a dichotomy in distillation outcomes. We prove that when a teacher provides confident supervision on unlearnable samples, it compels the student to memorize spurious noise patterns that eventually overpower the learned robust signal, thereby driving robust overfitting. Conversely, a teacher that exhibits high uncertainty on these samples effectively suppresses noise memorization, allowing the student to rely solely on the learnable signal for robust generalization. We empirically validate our theory across both synthetic simulations and real-image classification datasets, confirming that robust overfitting is driven by the teacher's interaction with unlearnable samples. Finally, we demonstrate that a teacher's predictive entropy on unlearnable samples serves as a strong indicator of student robustness, validating our theoretical framework and offering a principled guideline for robust teacher selection.
Sample-wise Adaptive Weighting for Transfer Consistency in Adversarial Distillation
Dec 11, 2025Adversarial distillation in the standard min-max adversarial training framework aims to transfer adversarial robustness from a large, robust teacher network to a compact student. However, existing work often neglects to incorporate state-of-the-art robust teachers. Through extensive analysis, we find that stronger teachers do not necessarily yield more robust students-a phenomenon known as robust saturation. While typically attributed to capacity gaps, we show that such explanations are incomplete. Instead, we identify adversarial transferability-the fraction of student-crafted adversarial examples that remain effective against the teacher-as a key factor in successful robustness transfer. Based on this insight, we propose Sample-wise Adaptive Adversarial Distillation (SAAD), which reweights training examples by their measured transferability without incurring additional computational cost. Experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet show that SAAD consistently improves AutoAttack robustness over prior methods. Our code is available at https://github.com/HongsinLee/saad.
SNAP: Low-Latency Test-Time Adaptation with Sparse Updates
Nov 19, 2025Test-Time Adaptation (TTA) adjusts models using unlabeled test data to handle dynamic distribution shifts. However, existing methods rely on frequent adaptation and high computational cost, making them unsuitable for resource-constrained edge environments. To address this, we propose SNAP, a sparse TTA framework that reduces adaptation frequency and data usage while preserving accuracy. SNAP maintains competitive accuracy even when adapting based on only 1% of the incoming data stream, demonstrating its robustness under infrequent updates. Our method introduces two key components: (i) Class and Domain Representative Memory (CnDRM), which identifies and stores a small set of samples that are representative of both class and domain characteristics to support efficient adaptation with limited data; and (ii) Inference-only Batch-aware Memory Normalization (IoBMN), which dynamically adjusts normalization statistics at inference time by leveraging these representative samples, enabling efficient alignment to shifting target domains. Integrated with five state-of-the-art TTA algorithms, SNAP reduces latency by up to 93.12%, while keeping the accuracy drop below 3.3%, even across adaptation rates ranging from 1% to 50%. This demonstrates its strong potential for practical use on edge devices serving latency-sensitive applications. The source code is available at https://github.com/chahh9808/SNAP.
Exact Matching in Correlated Networks with Node Attributes for Improved Community Recovery
Jan 06, 2025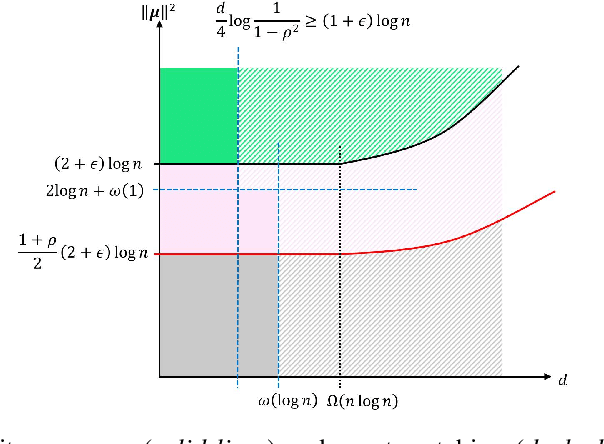
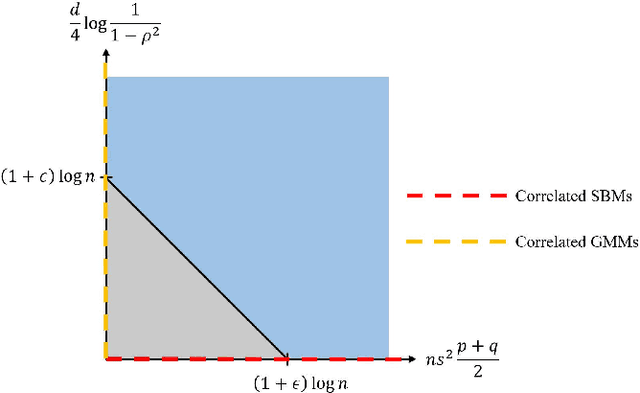
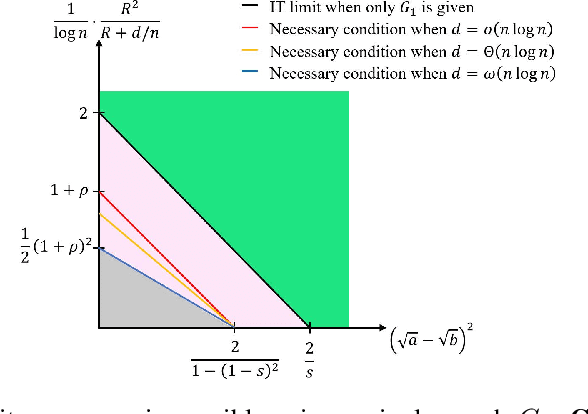
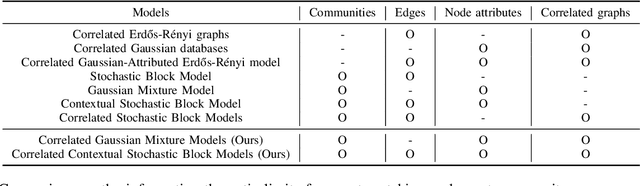
We study community detection in multiple networks whose nodes and edges are jointly correlated. This setting arises naturally in applications such as social platforms, where a shared set of users may exhibit both correlated friendship patterns and correlated attributes across different platforms. Extending the classical Stochastic Block Model (SBM) and its contextual counterpart (CSBM), we introduce the correlated CSBM, which incorporates structural and attribute correlations across graphs. To build intuition, we first analyze correlated Gaussian Mixture Models, wherein only correlated node attributes are available without edges, and identify the conditions under which an estimator minimizing the distance between attributes achieves exact matching of nodes across the two databases. For correlated CSBMs, we develop a two-step procedure that first applies $k$-core matching to most nodes using edge information, then refines the matching for the remaining unmatched nodes by leveraging their attributes with a distance-based estimator. We identify the conditions under which the algorithm recovers the exact node correspondence, enabling us to merge the correlated edges and average the correlated attributes for enhanced community detection. Crucially, by aligning and combining graphs, we identify regimes in which community detection is impossible in a single graph but becomes feasible when side information from correlated graphs is incorporated. Our results illustrate how the interplay between graph matching and community recovery can boost performance, broadening the scope of multi-graph, attribute-based community detection.
Label Distribution Shift-Aware Prediction Refinement for Test-Time Adaptation
Nov 20, 2024
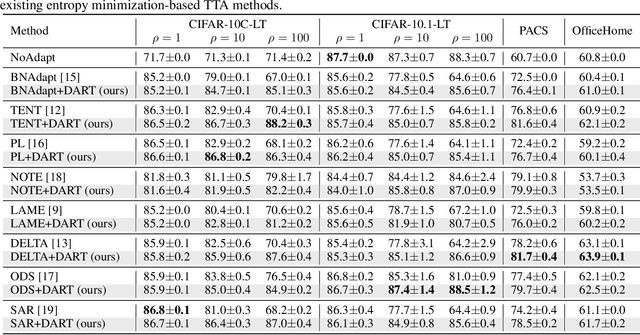


Test-time adaptation (TTA) is an effective approach to mitigate performance degradation of trained models when encountering input distribution shifts at test time. However, existing TTA methods often suffer significant performance drops when facing additional class distribution shifts. We first analyze TTA methods under label distribution shifts and identify the presence of class-wise confusion patterns commonly observed across different covariate shifts. Based on this observation, we introduce label Distribution shift-Aware prediction Refinement for Test-time adaptation (DART), a novel TTA method that refines the predictions by focusing on class-wise confusion patterns. DART trains a prediction refinement module during an intermediate time by exposing it to several batches with diverse class distributions using the training dataset. This module is then used during test time to detect and correct class distribution shifts, significantly improving pseudo-label accuracy for test data. Our method exhibits 5-18% gains in accuracy under label distribution shifts on CIFAR-10C, without any performance degradation when there is no label distribution shift. Extensive experiments on CIFAR, PACS, OfficeHome, and ImageNet benchmarks demonstrate DART's ability to correct inaccurate predictions caused by test-time distribution shifts. This improvement leads to enhanced performance in existing TTA methods, making DART a valuable plug-in tool.
Representation Norm Amplification for Out-of-Distribution Detection in Long-Tail Learning
Aug 20, 2024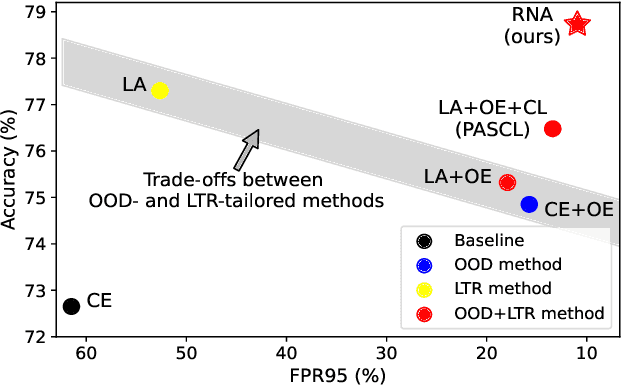
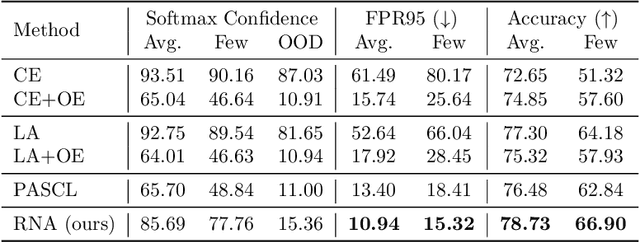
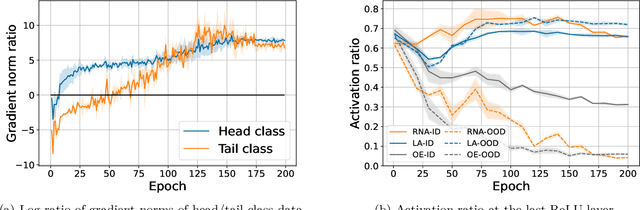
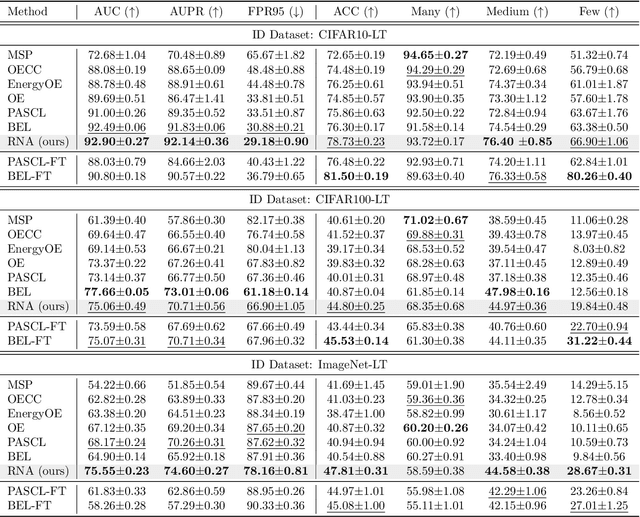
Detecting out-of-distribution (OOD) samples is a critical task for reliable machine learning. However, it becomes particularly challenging when the models are trained on long-tailed datasets, as the models often struggle to distinguish tail-class in-distribution samples from OOD samples. We examine the main challenges in this problem by identifying the trade-offs between OOD detection and in-distribution (ID) classification, faced by existing methods. We then introduce our method, called \textit{Representation Norm Amplification} (RNA), which solves this challenge by decoupling the two problems. The main idea is to use the norm of the representation as a new dimension for OOD detection, and to develop a training method that generates a noticeable discrepancy in the representation norm between ID and OOD data, while not perturbing the feature learning for ID classification. Our experiments show that RNA achieves superior performance in both OOD detection and classification compared to the state-of-the-art methods, by 1.70\% and 9.46\% in FPR95 and 2.43\% and 6.87\% in classification accuracy on CIFAR10-LT and ImageNet-LT, respectively. The code for this work is available at https://github.com/dgshin21/RNA.
BWS: Best Window Selection Based on Sample Scores for Data Pruning across Broad Ranges
Jun 05, 2024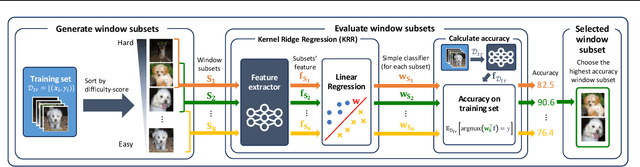
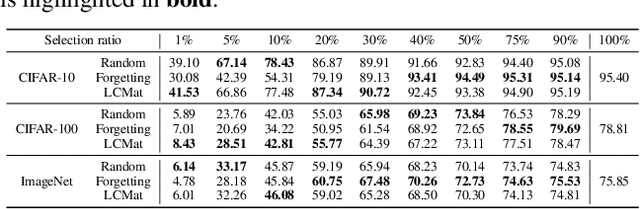
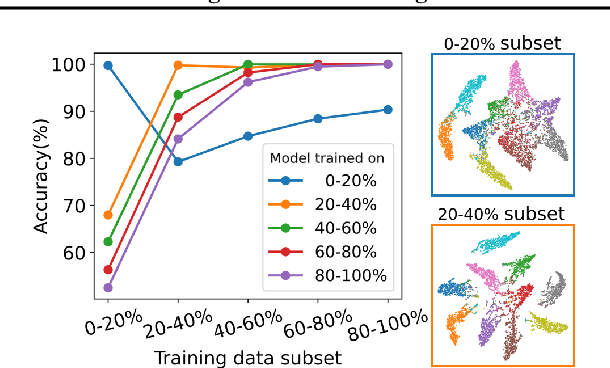
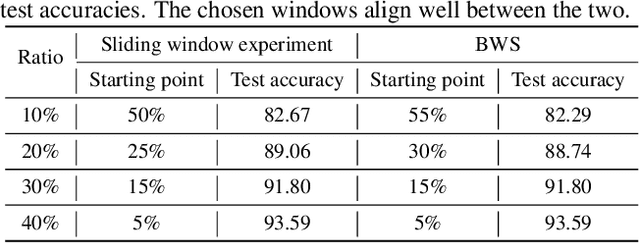
Data subset selection aims to find a smaller yet informative subset of a large dataset that can approximate the full-dataset training, addressing challenges associated with training neural networks on large-scale datasets. However, existing methods tend to specialize in either high or low selection ratio regimes, lacking a universal approach that consistently achieves competitive performance across a broad range of selection ratios. We introduce a universal and efficient data subset selection method, Best Window Selection (BWS), by proposing a method to choose the best window subset from samples ordered based on their difficulty scores. This approach offers flexibility by allowing the choice of window intervals that span from easy to difficult samples. Furthermore, we provide an efficient mechanism for selecting the best window subset by evaluating its quality using kernel ridge regression. Our experimental results demonstrate the superior performance of BWS compared to other baselines across a broad range of selection ratios over datasets, including CIFAR-10/100 and ImageNet, and the scenarios involving training from random initialization or fine-tuning of pre-trained models.
Understanding Self-Distillation and Partial Label Learning in Multi-Class Classification with Label Noise
Feb 16, 2024Self-distillation (SD) is the process of training a student model using the outputs of a teacher model, with both models sharing the same architecture. Our study theoretically examines SD in multi-class classification with cross-entropy loss, exploring both multi-round SD and SD with refined teacher outputs, inspired by partial label learning (PLL). By deriving a closed-form solution for the student model's outputs, we discover that SD essentially functions as label averaging among instances with high feature correlations. Initially beneficial, this averaging helps the model focus on feature clusters correlated with a given instance for predicting the label. However, it leads to diminishing performance with increasing distillation rounds. Additionally, we demonstrate SD's effectiveness in label noise scenarios and identify the label corruption condition and minimum number of distillation rounds needed to achieve 100% classification accuracy. Our study also reveals that one-step distillation with refined teacher outputs surpasses the efficacy of multi-step SD using the teacher's direct output in high noise rate regimes.
Efficient Algorithms for Exact Graph Matching on Correlated Stochastic Block Models with Constant Correlation
Jun 02, 2023
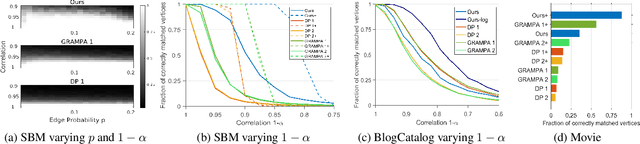
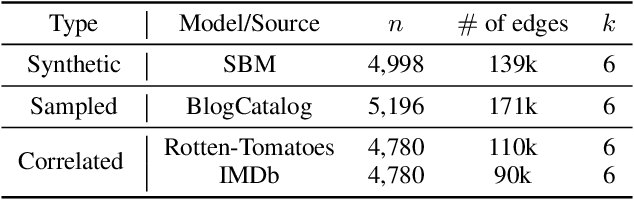
We consider the problem of graph matching, or learning vertex correspondence, between two correlated stochastic block models (SBMs). The graph matching problem arises in various fields, including computer vision, natural language processing and bioinformatics, and in particular, matching graphs with inherent community structure has significance related to de-anonymization of correlated social networks. Compared to the correlated Erdos-Renyi (ER) model, where various efficient algorithms have been developed, among which a few algorithms have been proven to achieve the exact matching with constant edge correlation, no low-order polynomial algorithm has been known to achieve exact matching for the correlated SBMs with constant correlation. In this work, we propose an efficient algorithm for matching graphs with community structure, based on the comparison between partition trees rooted from each vertex, by extending the idea of Mao et al. (2021) to graphs with communities. The partition tree divides the large neighborhoods of each vertex into disjoint subsets using their edge statistics to different communities. Our algorithm is the first low-order polynomial-time algorithm achieving exact matching between two correlated SBMs with high probability in dense graphs.
Detection problems in the spiked matrix models
Jan 16, 2023We study the statistical decision process of detecting the low-rank signal from various signal-plus-noise type data matrices, known as the spiked random matrix models. We first show that the principal component analysis can be improved by entrywise pre-transforming the data matrix if the noise is non-Gaussian, generalizing the known results for the spiked random matrix models with rank-1 signals. As an intermediate step, we find out sharp phase transition thresholds for the extreme eigenvalues of spiked random matrices, which generalize the Baik-Ben Arous-P\'{e}ch\'{e} (BBP) transition. We also prove the central limit theorem for the linear spectral statistics for the spiked random matrices and propose a hypothesis test based on it, which does not depend on the distribution of the signal or the noise. When the noise is non-Gaussian noise, the test can be improved with an entrywise transformation to the data matrix with additive noise. We also introduce an algorithm that estimates the rank of the signal when it is not known a priori.