 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Distribution Shift-Aware Prediction Refinement for Test-Time Adaptation
Nov 20, 2024
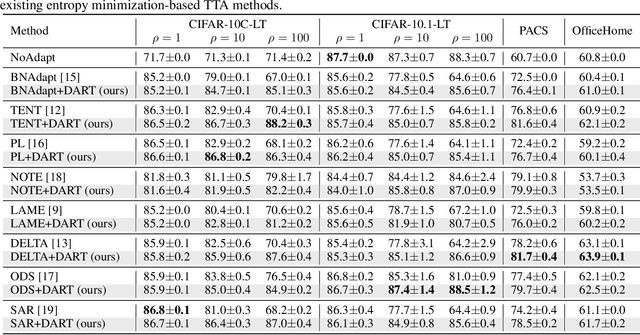


Test-time adaptation (TTA) is an effective approach to mitigate performance degradation of trained models when encountering input distribution shifts at test time. However, existing TTA methods often suffer significant performance drops when facing additional class distribution shifts. We first analyze TTA methods under label distribution shifts and identify the presence of class-wise confusion patterns commonly observed across different covariate shifts. Based on this observation, we introduce label Distribution shift-Aware prediction Refinement for Test-time adaptation (DART), a novel TTA method that refines the predictions by focusing on class-wise confusion patterns. DART trains a prediction refinement module during an intermediate time by exposing it to several batches with diverse class distributions using the training dataset. This module is then used during test time to detect and correct class distribution shifts, significantly improving pseudo-label accuracy for test data. Our method exhibits 5-18% gains in accuracy under label distribution shifts on CIFAR-10C, without any performance degradation when there is no label distribution shift. Extensive experiments on CIFAR, PACS, OfficeHome, and ImageNet benchmarks demonstrate DART's ability to correct inaccurate predictions caused by test-time distribution shifts. This improvement leads to enhanced performance in existing TTA methods, making DART a valuable plug-in tool.
Few-Example Clustering via Contrastive Learning
Jul 08, 2022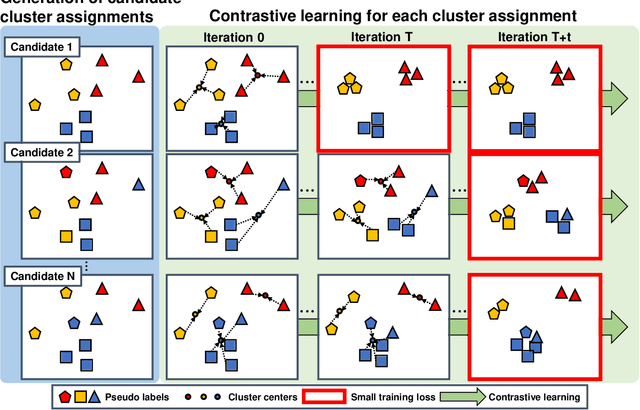
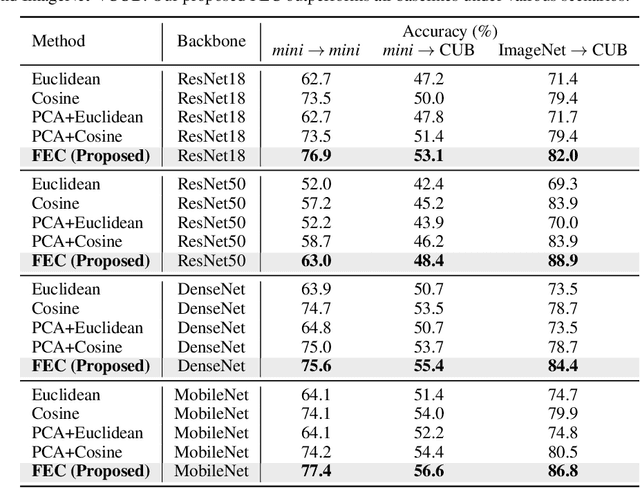
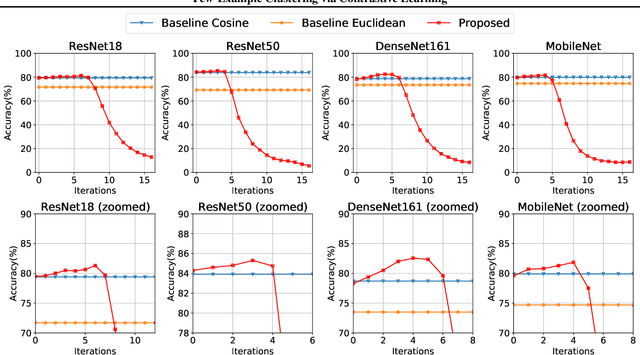
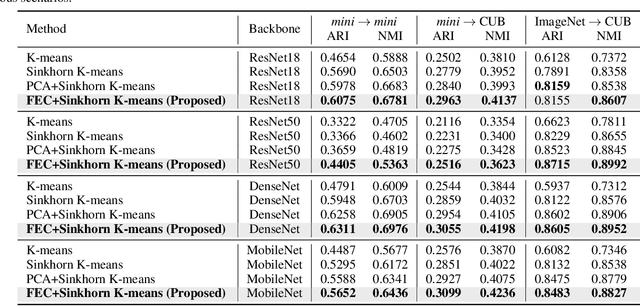
We propose Few-Example Clustering (FEC), a novel algorithm that performs contrastive learning to cluster few examples. Our method is composed of the following three steps: (1) generation of candidate cluster assignments, (2) contrastive learning for each cluster assignment, and (3) selection of the best candidate. Based on the hypothesis that the contrastive learner with the ground-truth cluster assignment is trained faster than the others, we choose the candidate with the smallest training loss in the early stage of learning in step (3). Extensive experiments on the \textit{mini}-ImageNet and CUB-200-2011 datasets show that FEC outperforms other baselines by about 3.2% on average under various scenarios. FEC also exhibits an interesting learning curve where clustering performance gradually increases and then sharply drops.