 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Example Clustering via Contrastive Learning
Paper and Code
Jul 08, 2022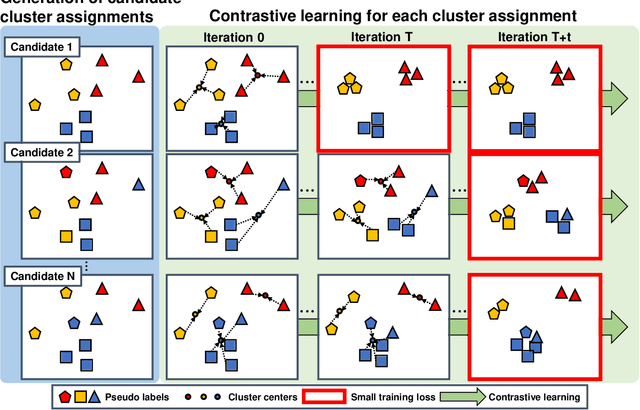
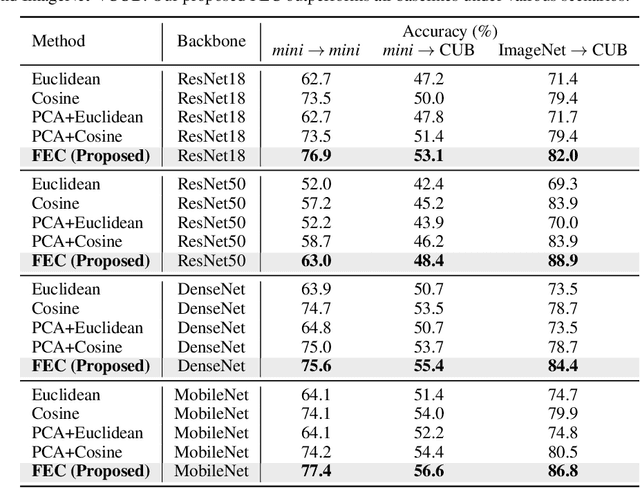
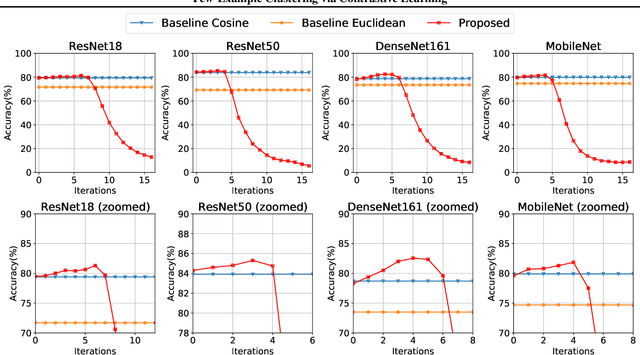
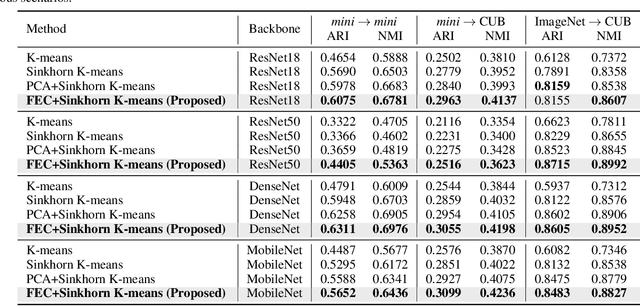
We propose Few-Example Clustering (FEC), a novel algorithm that performs contrastive learning to cluster few examples. Our method is composed of the following three steps: (1) generation of candidate cluster assignments, (2) contrastive learning for each cluster assignment, and (3) selection of the best candidate. Based on the hypothesis that the contrastive learner with the ground-truth cluster assignment is trained faster than the others, we choose the candidate with the smallest training loss in the early stage of learning in step (3). Extensive experiments on the \textit{mini}-ImageNet and CUB-200-2011 datasets show that FEC outperforms other baselines by about 3.2% on average under various scenarios. FEC also exhibits an interesting learning curve where clustering performance gradually increases and then sharply drops.