 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Visual Representation Learning via Mutual Information Regularized Assignment
Nov 04, 2022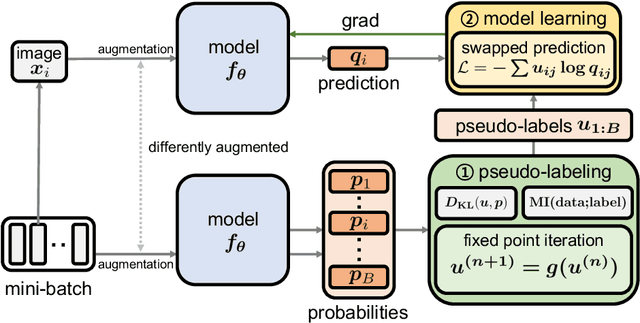
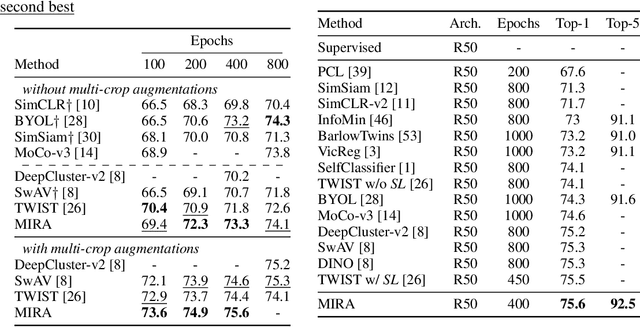
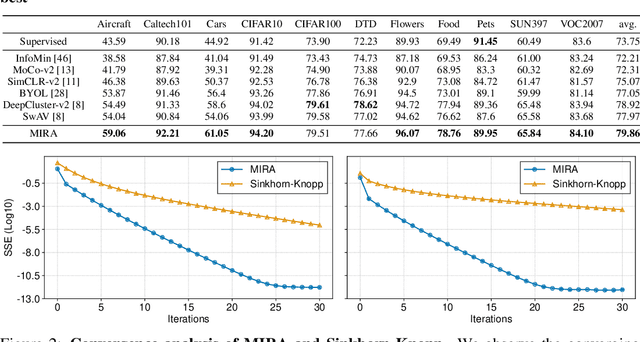

This paper proposes Mutual Information Regularized Assignment (MIRA), a pseudo-labeling algorithm for unsupervised representation learning inspired by information maximization. We formulate online pseudo-labeling as an optimization problem to find pseudo-labels that maximize the mutual information between the label and data while being close to a given model probability. We derive a fixed-point iteration method and prove its convergence to the optimal solution. In contrast to baselines, MIRA combined with pseudo-label prediction enables a simple yet effective clustering-based representation learning without incorporating extra training techniques or artificial constraints such as sampling strategy, equipartition constraints, etc. With relatively small training epochs, representation learned by MIRA achieves state-of-the-art performance on various downstream tasks, including the linear/k-NN evaluation and transfer learning. Especially, with only 400 epochs, our method applied to ImageNet dataset with ResNet-50 architecture achieves 75.6% linear evaluation accuracy.
Few-Example Clustering via Contrastive Learning
Jul 08, 2022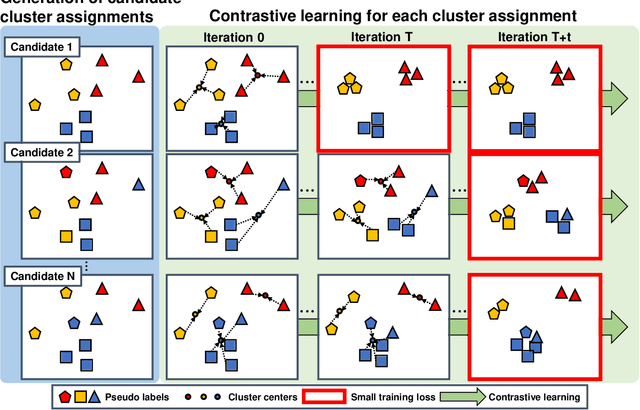
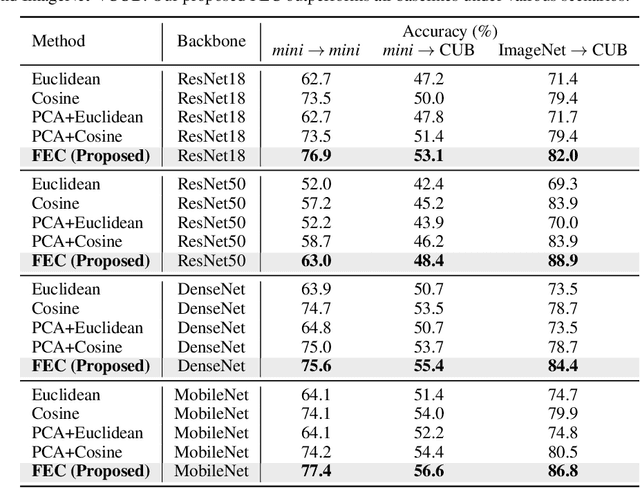
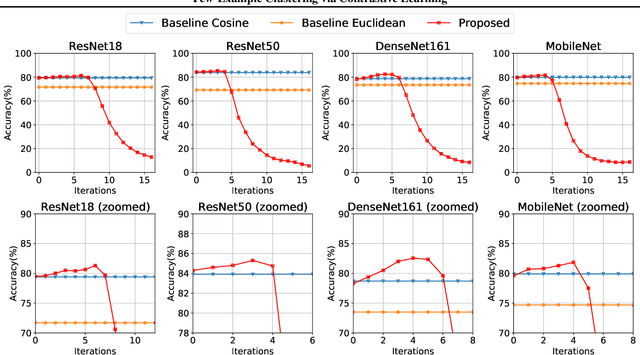
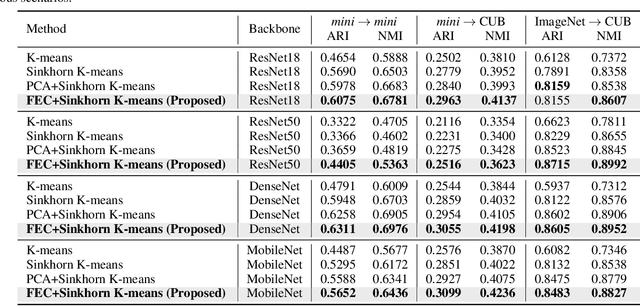
We propose Few-Example Clustering (FEC), a novel algorithm that performs contrastive learning to cluster few examples. Our method is composed of the following three steps: (1) generation of candidate cluster assignments, (2) contrastive learning for each cluster assignment, and (3) selection of the best candidate. Based on the hypothesis that the contrastive learner with the ground-truth cluster assignment is trained faster than the others, we choose the candidate with the smallest training loss in the early stage of learning in step (3). Extensive experiments on the \textit{mini}-ImageNet and CUB-200-2011 datasets show that FEC outperforms other baselines by about 3.2% on average under various scenarios. FEC also exhibits an interesting learning curve where clustering performance gradually increases and then sharply drops.
Unsupervised Embedding Adaptation via Early-Stage Feature Reconstruction for Few-Shot Classification
Jun 22, 2021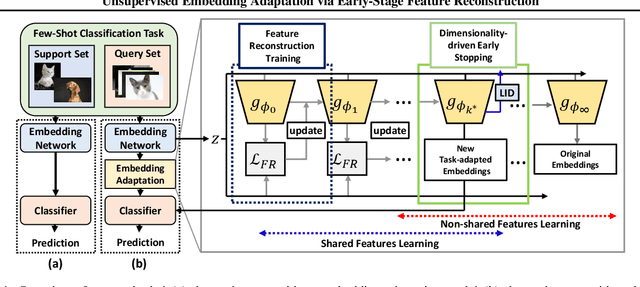
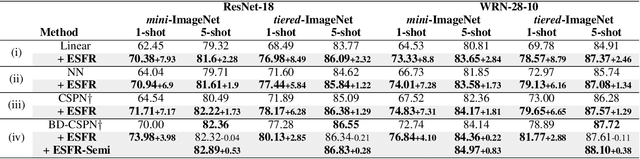
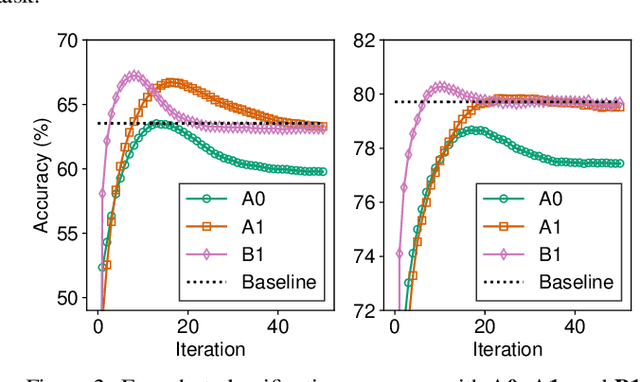
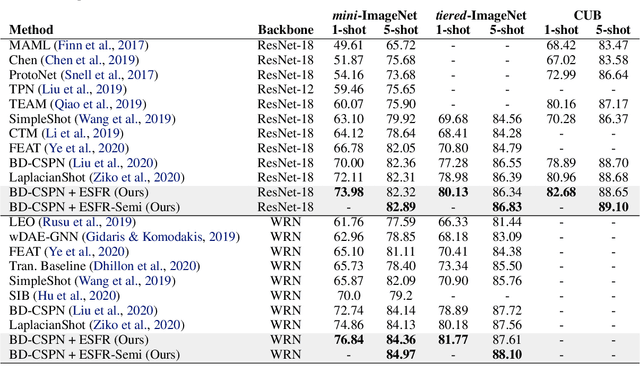
We propose unsupervised embedding adaptation for the downstream few-shot classification task. Based on findings that deep neural networks learn to generalize before memorizing, we develop Early-Stage Feature Reconstruction (ESFR) -- a novel adaptation scheme with feature reconstruction and dimensionality-driven early stopping that finds generalizable features. Incorporating ESFR consistently improves the performance of baseline methods on all standard settings, including the recently proposed transductive method. ESFR used in conjunction with the transductive method further achieves state-of-the-art performance on mini-ImageNet, tiered-ImageNet, and CUB; especially with 1.2%~2.0% improvements in accuracy over the previous best performing method on 1-shot setting.
Improving Generalization in Meta-RL with Imaginary Tasks from Latent Dynamics Mixture
May 28, 2021

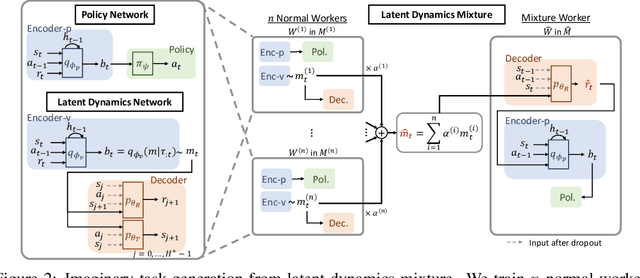

The generalization ability of most meta-reinforcement learning (meta-RL) methods is largely limited to test tasks that are sampled from the same distribution used to sample training tasks. To overcome the limitation, we propose Latent Dynamics Mixture (LDM) that trains a reinforcement learning agent with imaginary tasks generated from mixtures of learned latent dynamics. By training a policy on mixture tasks along with original training tasks, LDM allows the agent to prepare for unseen test tasks during training and prevents the agent from overfitting the training tasks. LDM significantly outperforms standard meta-RL methods in test returns on the gridworld navigation and MuJoCo tasks where we strictly separate the training task distribution and the test task distribution.
Novelty Detection Via Blurring
Jan 07, 2020
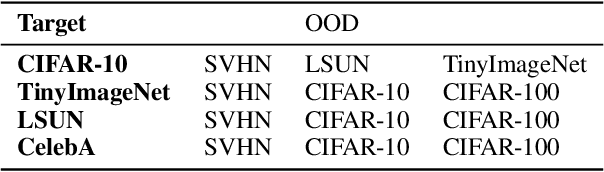
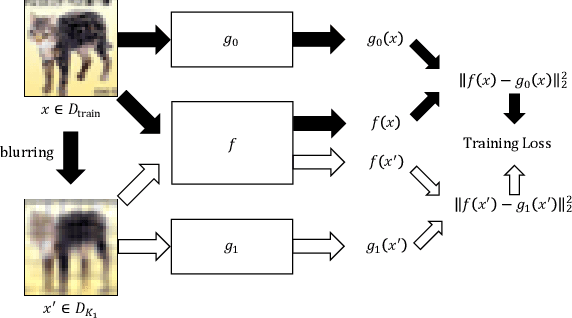
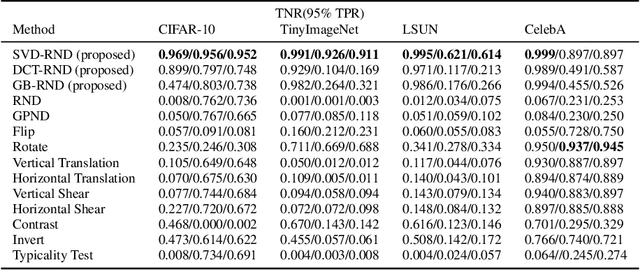
Conventional out-of-distribution (OOD) detection schemes based on variational autoencoder or Random Network Distillation (RND) have been observed to assign lower uncertainty to the OOD than the target distribution. In this work, we discover that such conventional novelty detection schemes are also vulnerable to the blurred images. Based on the observation, we construct a novel RND-based OOD detector, SVD-RND, that utilizes blurred images during training. Our detector is simple, efficient at test time, and outperforms baseline OOD detectors in various domains. Further results show that SVD-RND learns better target distribution representation than the baseline RND algorithm. Finally, SVD-RND combined with geometric transform achieves near-perfect detection accuracy on the CelebA dataset.
Robust Training with Ensemble Consensus
Oct 22, 2019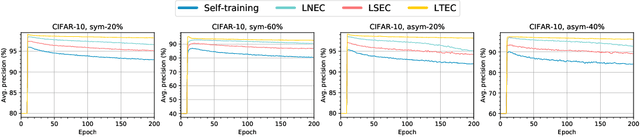
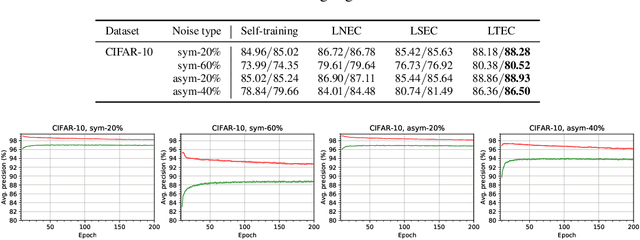
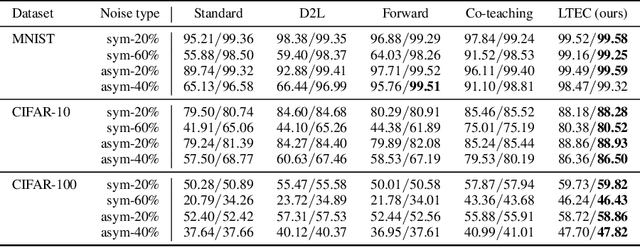
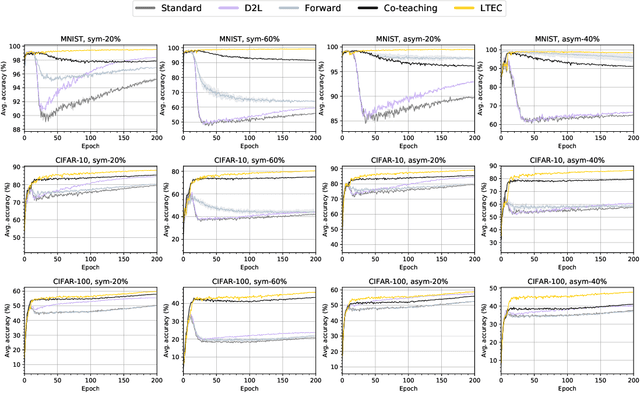
Since deep neural networks are over-parametrized, they may memorize noisy examples. We address such memorizing issue under the existence of annotation noise. From the fact that deep neural networks cannot generalize neighborhoods of the features acquired via memorization, we find that noisy examples do not consistently incur small losses on the network in the presence of perturbation. Based on this, we propose a novel training method called Learning with Ensemble Consensus (LEC) whose goal is to prevent overfitting noisy examples by eliminating them identified via consensus of an ensemble of perturbed networks. One of the proposed LECs, LTEC outperforms the current state-of-the-art methods on MNIST, CIFAR-10, and CIFAR-100 despite its efficient memory.
Fourier Phase Retrieval with Extended Support Estimation via Deep Neural Network
Apr 03, 2019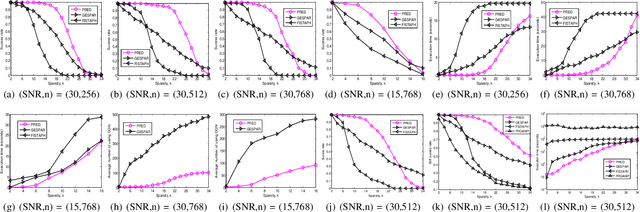
We consider the problem of sparse phase retrieval from Fourier transform magnitudes to recover $k$-sparse signal vector $x^{\circ}$ and its support $\mathcal{T}$. To improve the reconstruction performance of $x^{\circ}$, we exploit extended support estimate $\mathcal{E}$ of size larger than $k$ satisfying $\mathcal{E} \supseteq \mathcal{T}$. We propose a learning method for the deep neural network to provide $\mathcal{E}$ as an union of equivalent solutions of $\mathcal{T}$ by utilizing modulo Fourier invariances and suggest a searching technique for $\mathcal{T}$ by iteratively sampling $\mathcal{E}$ from the trained network output and applying the hard thresholding to $\mathcal{E}$. Numerical results show that our proposed scheme has a superior performance with a lower complexity compared to the local search-based greedy sparse phase retrieval method and a state-of-the-art variant of the Fienup method.
Tree Search Network for Sparse Regression
Apr 01, 2019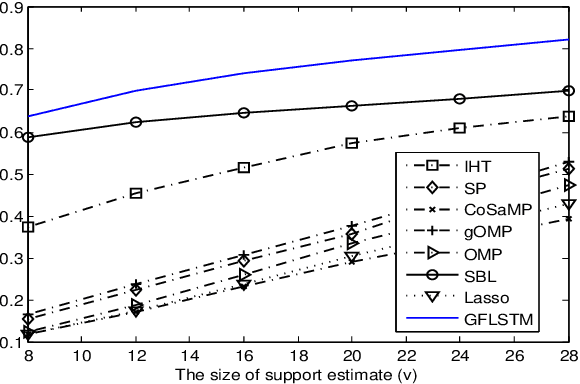
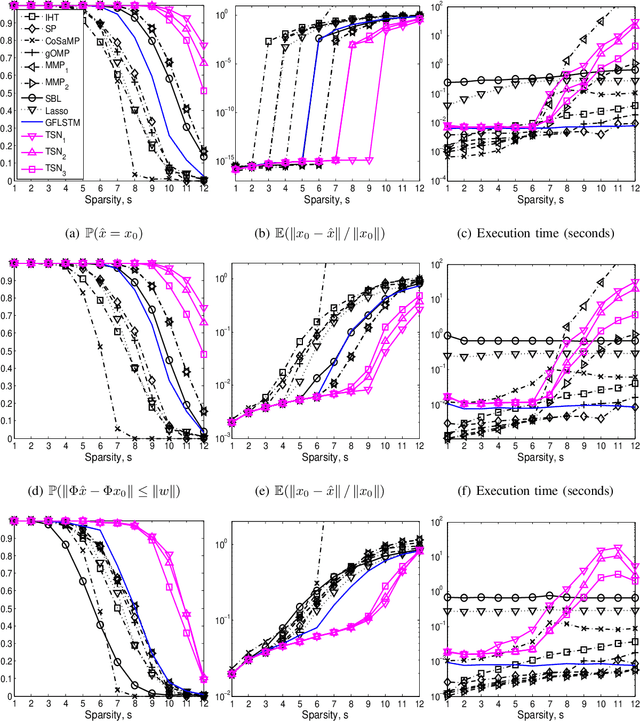
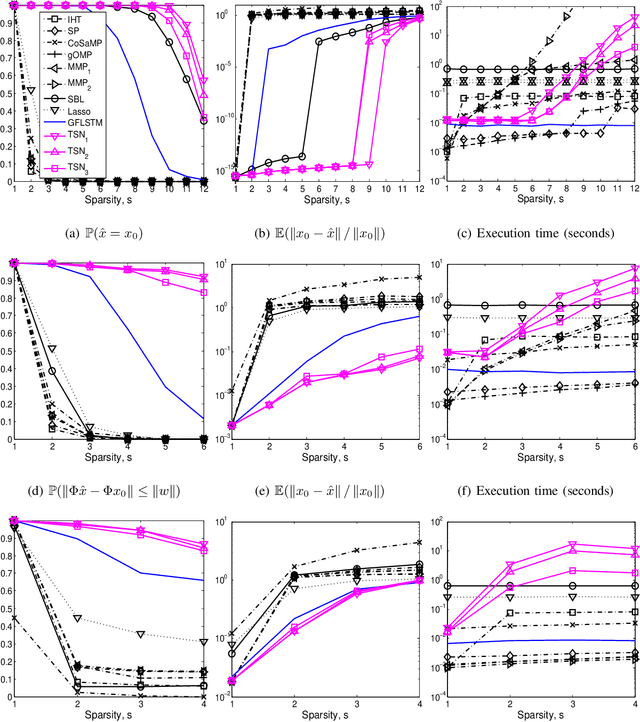
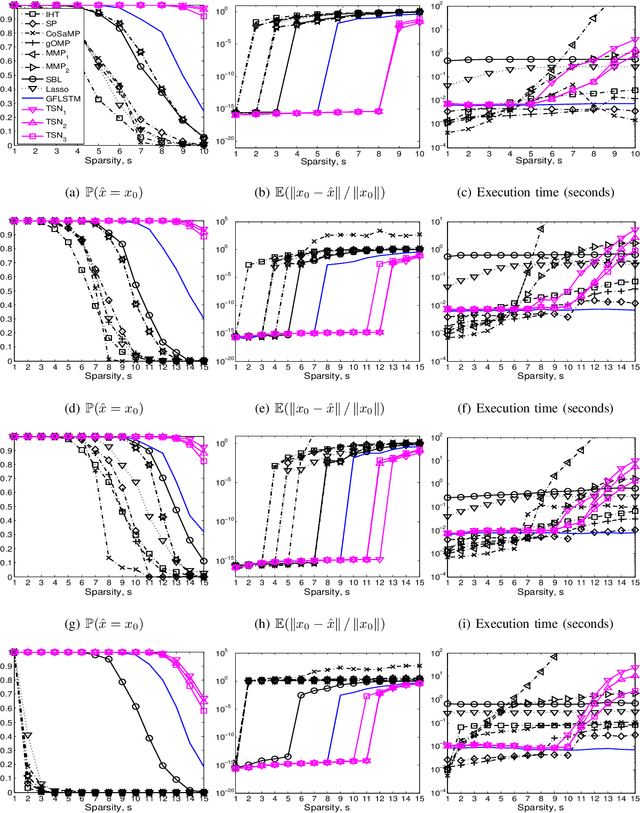
We consider the classical sparse regression problem of recovering a sparse signal $x_0$ given a measurement vector $y = \Phi x_0+w$. We propose a tree search algorithm driven by the deep neural network for sparse regression (TSN). TSN improves the signal reconstruction performance of the deep neural network designed for sparse regression by performing a tree search with pruning. It is observed in both noiseless and noisy cases, TSN recovers synthetic and real signals with lower complexity than a conventional tree search and is superior to existing algorithms by a large margin for various types of the sensing matrix $\Phi$, widely used in sparse regression.
Sample-Efficient Deep Reinforcement Learning via Episodic Backward Update
May 31, 2018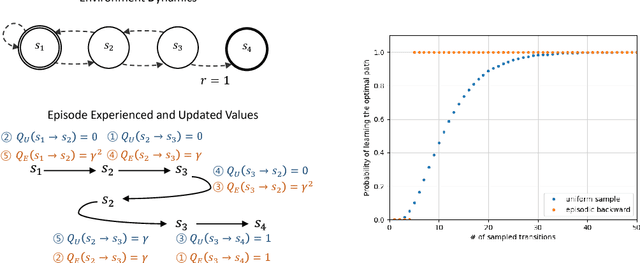
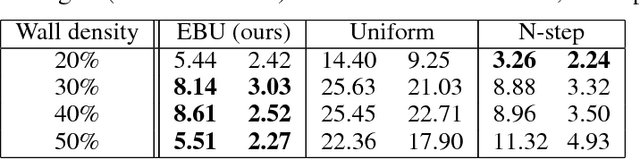

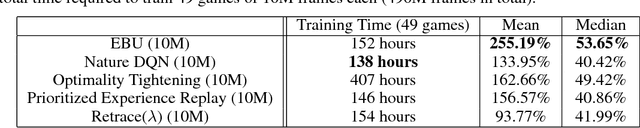
We propose Episodic Backward Update - a new algorithm to boost the performance of a deep reinforcement learning agent by a fast reward propagation. In contrast to the conventional use of the experience replay with uniform random sampling, our agent samples a whole episode and successively propagates the value of a state to its previous states. Our computationally efficient recursive algorithm allows sparse and delayed rewards to propagate efficiently through all transitions of a sampled episode. We evaluate our algorithm on 2D MNIST Maze environment and 49 games of the Atari 2600 environment and show that our method improves sample efficiency with a competitive amount of computational cost.