Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Deep Reinforcement Learning via Episodic Backward Update
Paper and Code
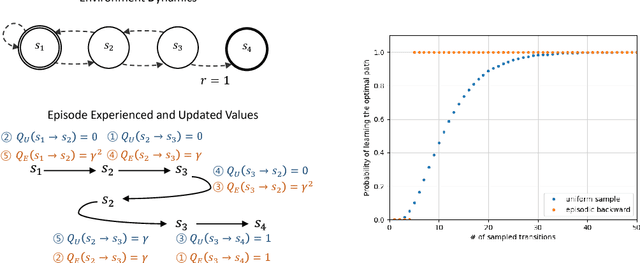
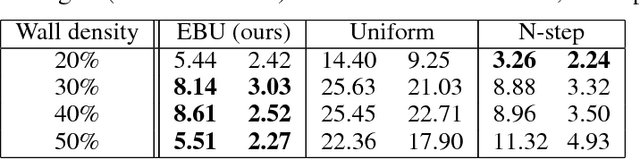

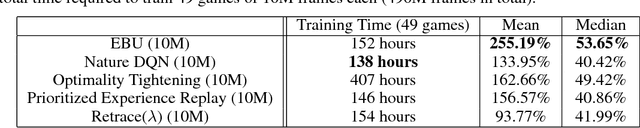
We propose Episodic Backward Update - a new algorithm to boost the performance of a deep reinforcement learning agent by a fast reward propagation. In contrast to the conventional use of the experience replay with uniform random sampling, our agent samples a whole episode and successively propagates the value of a state to its previous states. Our computationally efficient recursive algorithm allows sparse and delayed rewards to propagate efficiently through all transitions of a sampled episode. We evaluate our algorithm on 2D MNIST Maze environment and 49 games of the Atari 2600 environment and show that our method improves sample efficiency with a competitive amount of computational cost.
View paper on
 OpenReview
OpenReview