 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Few-Shot Spatial Control for Diffusion Models
Sep 09, 2025



Spatial conditioning in pretrained text-to-image diffusion models has significantly improved fine-grained control over the structure of generated images. However, existing control adapters exhibit limited adaptability and incur high training costs when encountering novel spatial control conditions that differ substantially from the training tasks. To address this limitation, we propose Universal Few-Shot Control (UFC), a versatile few-shot control adapter capable of generalizing to novel spatial conditions. Given a few image-condition pairs of an unseen task and a query condition, UFC leverages the analogy between query and support conditions to construct task-specific control features, instantiated by a matching mechanism and an update on a small set of task-specific parameters. Experiments on six novel spatial control tasks show that UFC, fine-tuned with only 30 annotated examples of novel tasks, achieves fine-grained control consistent with the spatial conditions. Notably, when fine-tuned with 0.1% of the full training data, UFC achieves competitive performance with the fully supervised baselines in various control tasks. We also show that UFC is applicable agnostically to various diffusion backbones and demonstrate its effectiveness on both UNet and DiT architectures. Code is available at https://github.com/kietngt00/UFC.
Learning to Merge Tokens via Decoupled Embedding for Efficient Vision Transformers
Dec 13, 2024



Recent token reduction methods for Vision Transformers (ViTs) incorporate token merging, which measures the similarities between token embeddings and combines the most similar pairs. However, their merging policies are directly dependent on intermediate features in ViTs, which prevents exploiting features tailored for merging and requires end-to-end training to improve token merging. In this paper, we propose Decoupled Token Embedding for Merging (DTEM) that enhances token merging through a decoupled embedding learned via a continuously relaxed token merging process. Our method introduces a lightweight embedding module decoupled from the ViT forward pass to extract dedicated features for token merging, thereby addressing the restriction from using intermediate features. The continuously relaxed token merging, applied during training, enables us to learn the decoupled embeddings in a differentiable manner. Thanks to the decoupled structure, our method can be seamlessly integrated into existing ViT backbones and trained either modularly by learning only the decoupled embeddings or end-to-end by fine-tuning. We demonstrate the applicability of DTEM on various tasks, including classification, captioning, and segmentation, with consistent improvement in token merging. Especially in the ImageNet-1k classification, DTEM achieves a 37.2% reduction in FLOPs while maintaining a top-1 accuracy of 79.85% with DeiT-small. Code is available at \href{https://github.com/movinghoon/dtem}{link}.
Unsupervised Visual Representation Learning via Mutual Information Regularized Assignment
Nov 04, 2022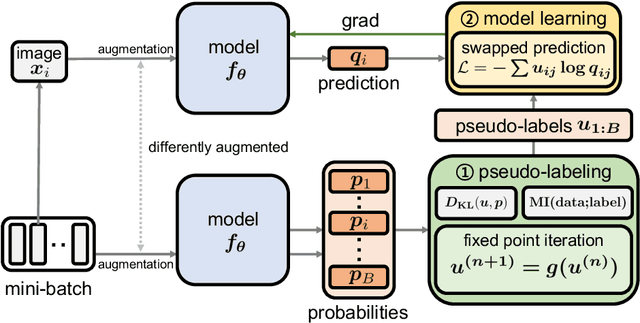
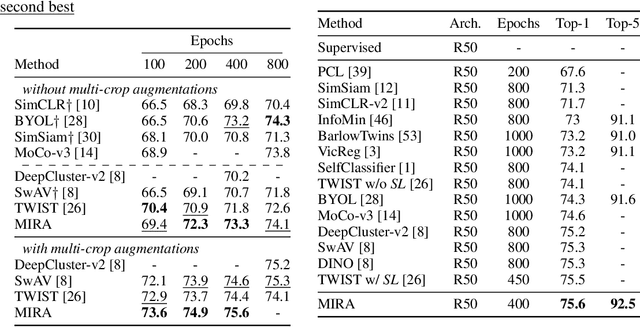
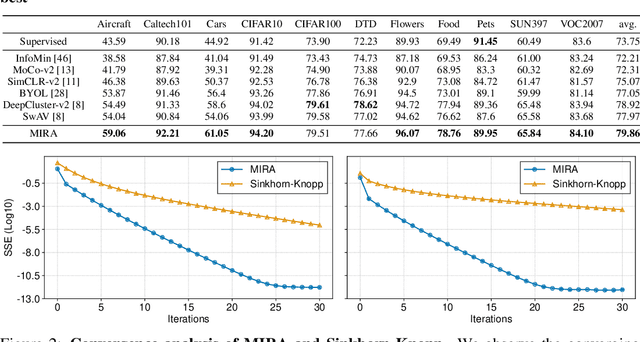

This paper proposes Mutual Information Regularized Assignment (MIRA), a pseudo-labeling algorithm for unsupervised representation learning inspired by information maximization. We formulate online pseudo-labeling as an optimization problem to find pseudo-labels that maximize the mutual information between the label and data while being close to a given model probability. We derive a fixed-point iteration method and prove its convergence to the optimal solution. In contrast to baselines, MIRA combined with pseudo-label prediction enables a simple yet effective clustering-based representation learning without incorporating extra training techniques or artificial constraints such as sampling strategy, equipartition constraints, etc. With relatively small training epochs, representation learned by MIRA achieves state-of-the-art performance on various downstream tasks, including the linear/k-NN evaluation and transfer learning. Especially, with only 400 epochs, our method applied to ImageNet dataset with ResNet-50 architecture achieves 75.6% linear evaluation accuracy.
Unsupervised Embedding Adaptation via Early-Stage Feature Reconstruction for Few-Shot Classification
Jun 22, 2021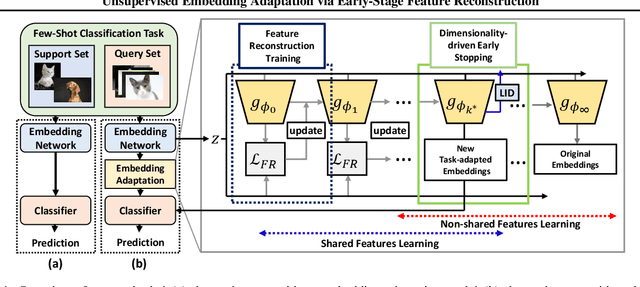
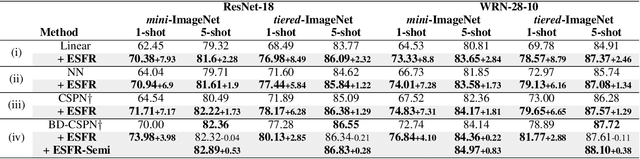
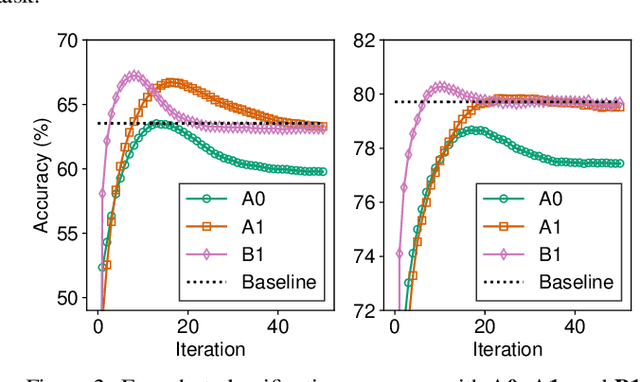
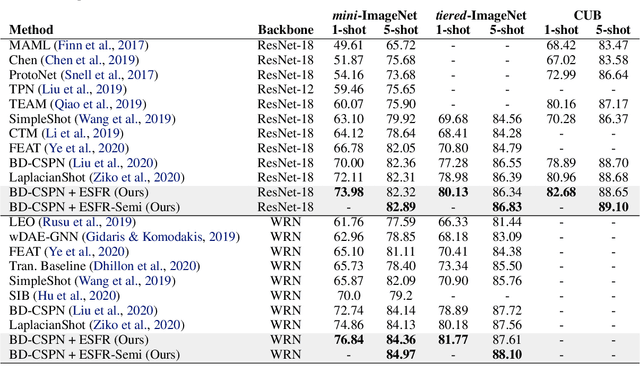
We propose unsupervised embedding adaptation for the downstream few-shot classification task. Based on findings that deep neural networks learn to generalize before memorizing, we develop Early-Stage Feature Reconstruction (ESFR) -- a novel adaptation scheme with feature reconstruction and dimensionality-driven early stopping that finds generalizable features. Incorporating ESFR consistently improves the performance of baseline methods on all standard settings, including the recently proposed transductive method. ESFR used in conjunction with the transductive method further achieves state-of-the-art performance on mini-ImageNet, tiered-ImageNet, and CUB; especially with 1.2%~2.0% improvements in accuracy over the previous best performing method on 1-shot setting.