 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeet Your Favorite Character: Open-domain Chatbot Mimicking Fictional Characters with only a Few Utterances
Apr 22, 2022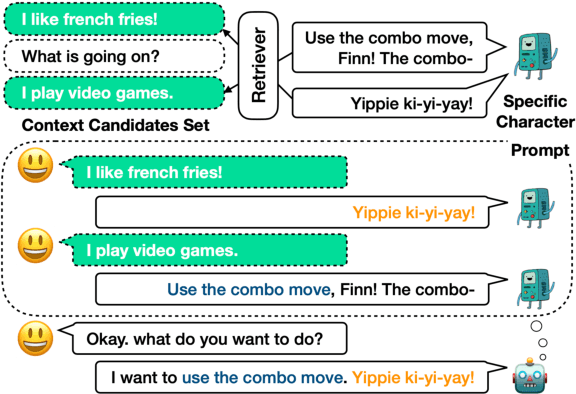
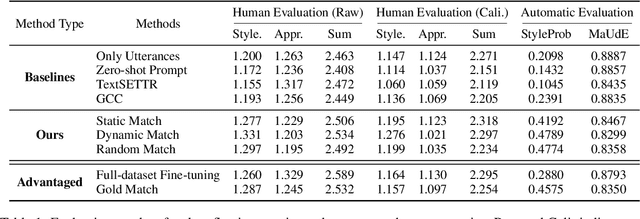

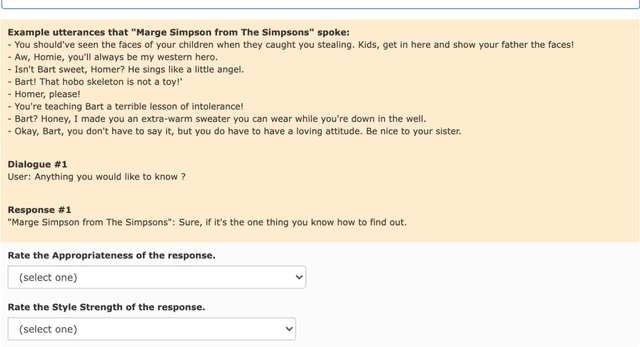
In this paper, we consider mimicking fictional characters as a promising direction for building engaging conversation models. To this end, we present a new practical task where only a few utterances of each fictional character are available to generate responses mimicking them. Furthermore, we propose a new method named Pseudo Dialog Prompting (PDP) that generates responses by leveraging the power of large-scale language models with prompts containing the target character's utterances. To better reflect the style of the character, PDP builds the prompts in the form of dialog that includes the character's utterances as dialog history. Since only utterances of the characters are available in the proposed task, PDP matches each utterance with an appropriate pseudo-context from a predefined set of context candidates using a retrieval model. Through human and automatic evaluation, we show that PDP generates responses that better reflect the style of fictional characters than baseline methods.
Understanding and Improving the Exemplar-based Generation for Open-domain Conversation
Dec 13, 2021


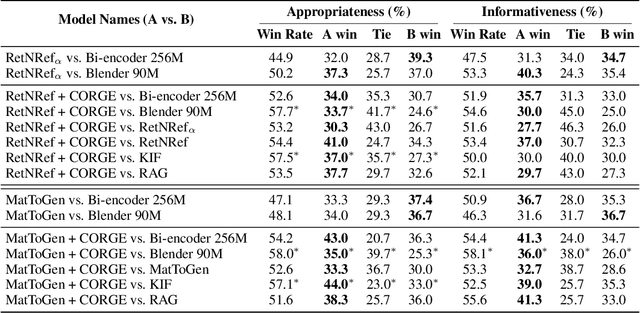
Exemplar-based generative models for open-domain conversation produce responses based on the exemplars provided by the retriever, taking advantage of generative models and retrieval models. However, they often ignore the retrieved exemplars while generating responses or produce responses over-fitted to the retrieved exemplars. In this paper, we argue that these drawbacks are derived from the one-to-many problem of the open-domain conversation. When the retrieved exemplar is relevant to the given context yet significantly different from the gold response, the exemplar-based generative models are trained to ignore the exemplar since the exemplar is not helpful for generating the gold response. On the other hand, when the retrieved exemplar is lexically similar to the gold response, the generative models are trained to rely on the exemplar highly. Therefore, we propose a training method selecting exemplars that are semantically relevant to the gold response but lexically distanced from the gold response to mitigate the above disadvantages. In the training phase, our proposed training method first uses the gold response instead of dialogue context as a query to select exemplars that are semantically relevant to the gold response. And then, it eliminates the exemplars that lexically resemble the gold responses to alleviate the dependency of the generative models on that exemplars. The remaining exemplars could be irrelevant to the given context since they are searched depending on the gold response. Thus, our proposed training method further utilizes the relevance scores between the given context and the exemplars to penalize the irrelevant exemplars. Extensive experiments demonstrate that our proposed training method alleviates the drawbacks of the existing exemplar-based generative models and significantly improves the performance in terms of appropriateness and informativeness.
Distilling the Knowledge of Large-scale Generative Models into Retrieval Models for Efficient Open-domain Conversation
Aug 31, 2021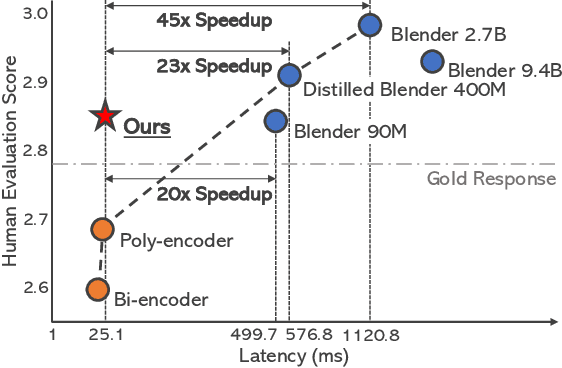

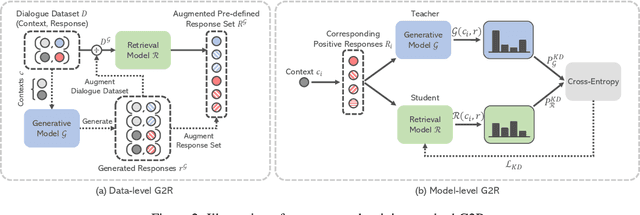

Despite the remarkable performance of large-scale generative models in open-domain conversation, they are known to be less practical for building real-time conversation systems due to high latency. On the other hand, retrieval models could return responses with much lower latency but show inferior performance to the large-scale generative models since the conversation quality is bounded by the pre-defined response set. To take advantage of both approaches, we propose a new training method called G2R (Generative-to-Retrieval distillation) that preserves the efficiency of a retrieval model while leveraging the conversational ability of a large-scale generative model by infusing the knowledge of the generative model into the retrieval model. G2R consists of two distinct techniques of distillation: the data-level G2R augments the dialogue dataset with additional responses generated by the large-scale generative model, and the model-level G2R transfers the response quality score assessed by the generative model to the score of the retrieval model by the knowledge distillation loss. Through extensive experiments including human evaluation, we demonstrate that our retrieval-based conversation system trained with G2R shows a substantially improved performance compared to the baseline retrieval model while showing significantly lower inference latency than the large-scale generative models.
Disentangling Label Distribution for Long-tailed Visual Recognition
Dec 01, 2020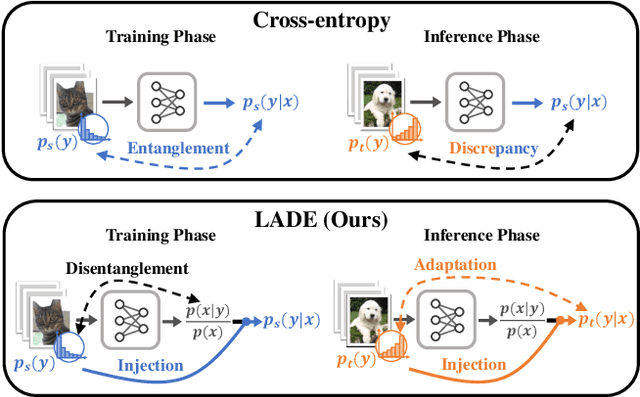


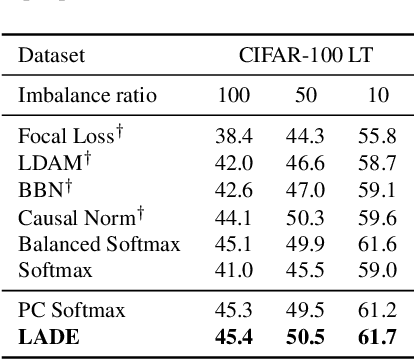
The current evaluation protocol of long-tailed visual recognition trains the classification model on the long-tailed source label distribution and evaluates its performance on the uniform target label distribution. Such protocol has questionable practicality since the target may also be long-tailed. Therefore, we formulate long-tailed visual recognition as a label shift problem where the target and source label distributions are different. One of the significant hurdles in dealing with the label shift problem is the entanglement between the source label distribution and the model prediction. In this paper, we focus on disentangling the source label distribution from the model prediction. We first introduce a simple baseline method that matches the target label distribution by post-processing the model prediction trained by the cross-entropy loss and the Softmax function. Although this method surpasses state-of-the-art methods on benchmark datasets, it can be further improved by directly disentangling the source label distribution from the model prediction in the training phase. Thus, we propose a novel method, LAbel distribution DisEntangling (LADE) loss based on the optimal bound of Donsker-Varadhan representation. LADE achieves state-of-the-art performance on benchmark datasets such as CIFAR-100-LT, Places-LT, ImageNet-LT, and iNaturalist 2018. Moreover, LADE outperforms existing methods on various shifted target label distributions, showing the general adaptability of our proposed method.
MarioNETte: Few-shot Face Reenactment Preserving Identity of Unseen Targets
Nov 19, 2019
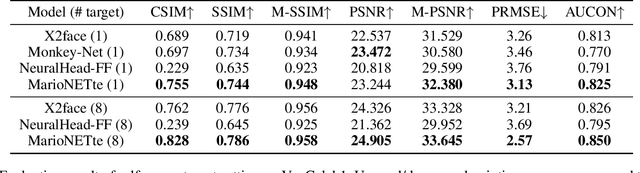
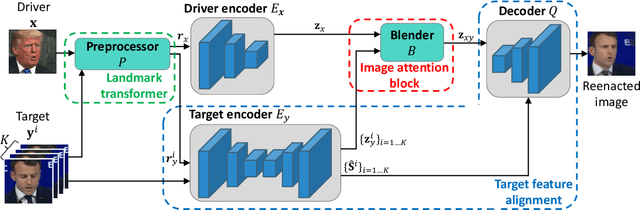

When there is a mismatch between the target identity and the driver identity, face reenactment suffers severe degradation in the quality of the result, especially in a few-shot setting. The identity preservation problem, where the model loses the detailed information of the target leading to a defective output, is the most common failure mode. The problem has several potential sources such as the identity of the driver leaking due to the identity mismatch, or dealing with unseen large poses. To overcome such problems, we introduce components that address the mentioned problem: image attention block, target feature alignment, and landmark transformer. Through attending and warping the relevant features, the proposed architecture, called MarioNETte, produces high-quality reenactments of unseen identities in a few-shot setting. In addition, the landmark transformer dramatically alleviates the identity preservation problem by isolating the expression geometry through landmark disentanglement. Comprehensive experiments are performed to verify that the proposed framework can generate highly realistic faces, outperforming all other baselines, even under a significant mismatch of facial characteristics between the target and the driver.
Towards Real-Time Automatic Portrait Matting on Mobile Devices
Apr 08, 2019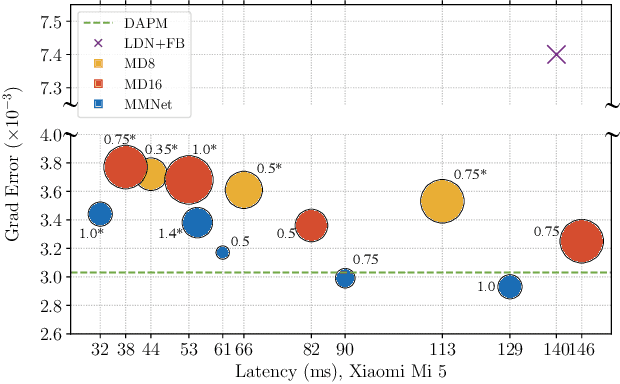
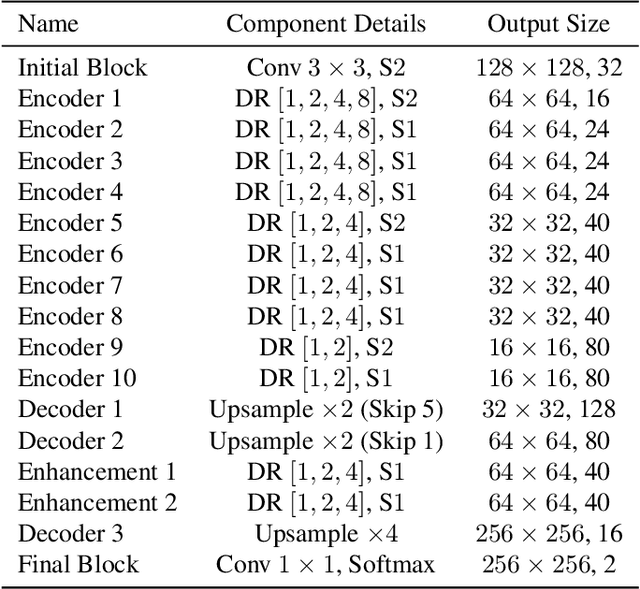

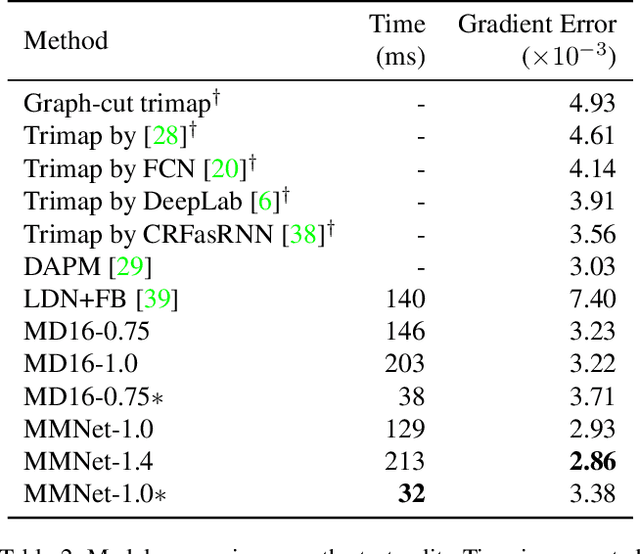
We tackle the problem of automatic portrait matting on mobile devices. The proposed model is aimed at attaining real-time inference on mobile devices with minimal degradation of model performance. Our model MMNet, based on multi-branch dilated convolution with linear bottleneck blocks, outperforms the state-of-the-art model and is orders of magnitude faster. The model can be accelerated four times to attain 30 FPS on Xiaomi Mi 5 device with moderate increase in the gradient error. Under the same conditions, our model has an order of magnitude less number of parameters and is faster than Mobile DeepLabv3 while maintaining comparable performance. The accompanied implementation can be found at \url{https://github.com/hyperconnect/MMNet}.
Temporal Convolution for Real-time Keyword Spotting on Mobile Devices
Apr 08, 2019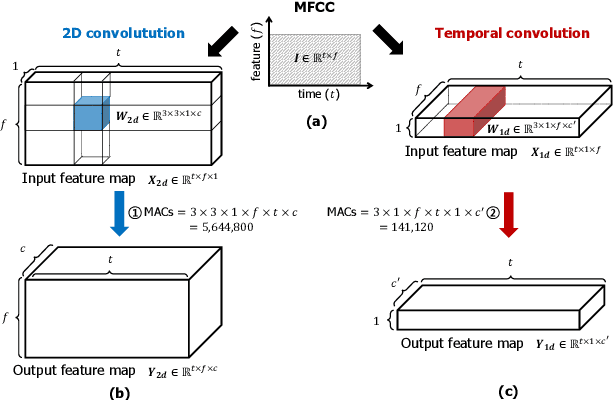
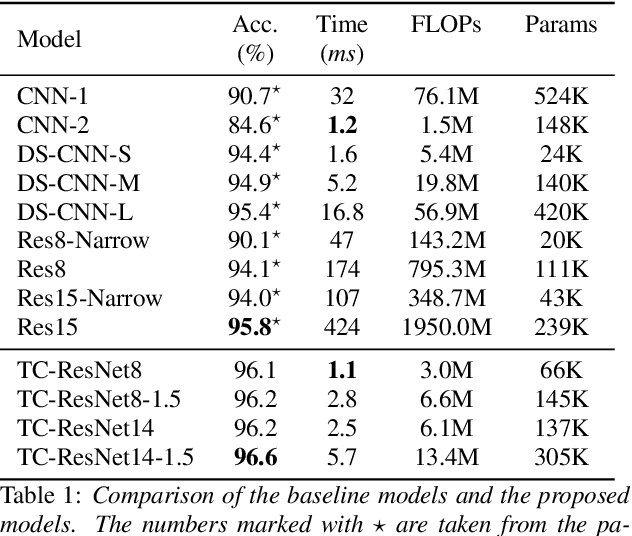
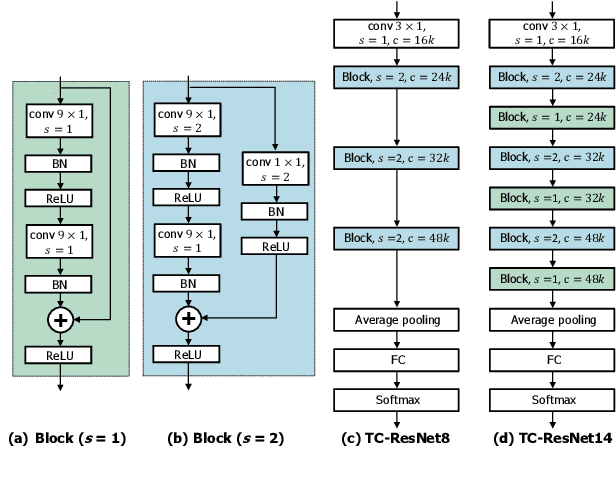
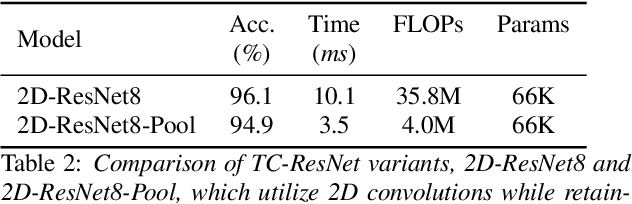
Keyword spotting (KWS) plays a critical role in enabling speech-based user interactions on smart devices. Recent developments in the field of deep learning have led to wide adoption of convolutional neural networks (CNNs) in KWS systems due to their exceptional accuracy and robustness. The main challenge faced by KWS systems is the trade-off between high accuracy and low latency. Unfortunately, there has been little quantitative analysis of the actual latency of KWS models on mobile devices. This is especially concerning since conventional convolution-based KWS approaches are known to require a large number of operations to attain an adequate level of performance. In this paper, we propose a temporal convolution for real-time KWS on mobile devices. Unlike most of the 2D convolution-based KWS approaches that require a deep architecture to fully capture both low- and high-frequency domains, we exploit temporal convolutions with a compact ResNet architecture. In Google Speech Command Dataset, we achieve more than \textbf{385x} speedup on Google Pixel 1 and surpass the accuracy compared to the state-of-the-art model. In addition, we release the implementation of the proposed and the baseline models including an end-to-end pipeline for training models and evaluating them on mobile devices.
Hybrid Approach of Relation Network and Localized Graph Convolutional Filtering for Breast Cancer Subtype Classification
Jun 15, 2018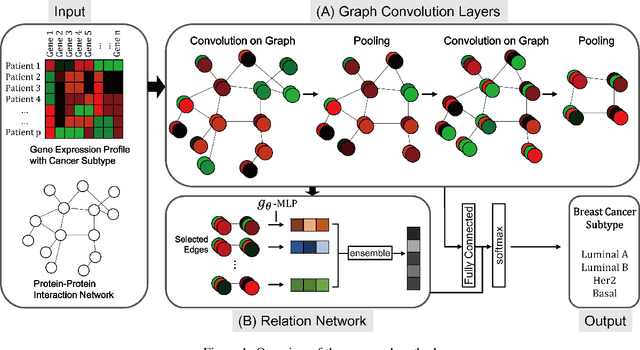
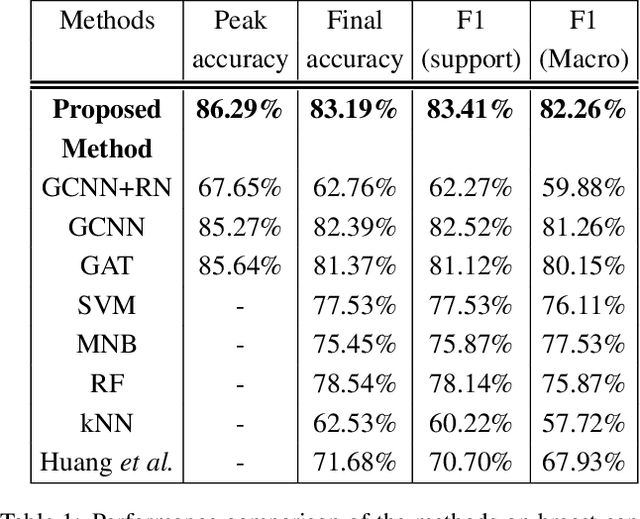
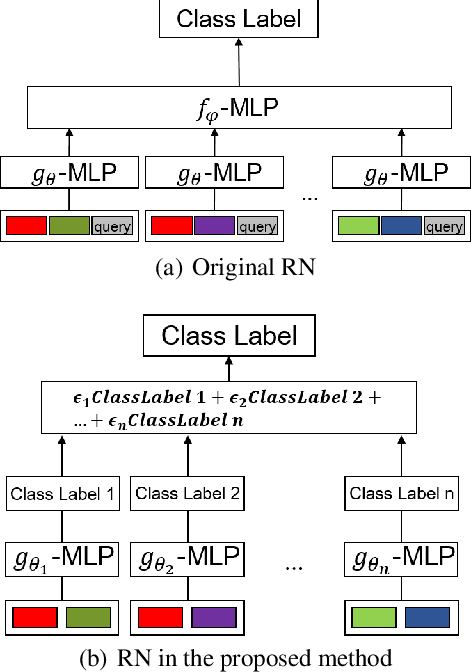
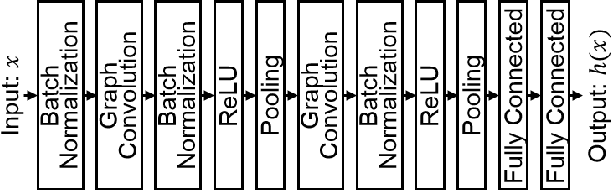
Network biology has been successfully used to help reveal complex mechanisms of disease, especially cancer. On the other hand, network biology requires in-depth knowledge to construct disease-specific networks, but our current knowledge is very limited even with the recent advances in human cancer biology. Deep learning has shown a great potential to address the difficult situation like this. However, deep learning technologies conventionally use grid-like structured data, thus application of deep learning technologies to the classification of human disease subtypes is yet to be explored. Recently, graph based deep learning techniques have emerged, which becomes an opportunity to leverage analyses in network biology. In this paper, we proposed a hybrid model, which integrates two key components 1) graph convolution neural network (graph CNN) and 2) relation network (RN). We utilize graph CNN as a component to learn expression patterns of cooperative gene community, and RN as a component to learn associations between learned patterns. The proposed model is applied to the PAM50 breast cancer subtype classification task, the standard breast cancer subtype classification of clinical utility. In experiments of both subtype classification and patient survival analysis, our proposed method achieved significantly better performances than existing methods. We believe that this work is an important starting point to realize the upcoming personalized medicine.