 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving the Exemplar-based Generation for Open-domain Conversation
Paper and Code



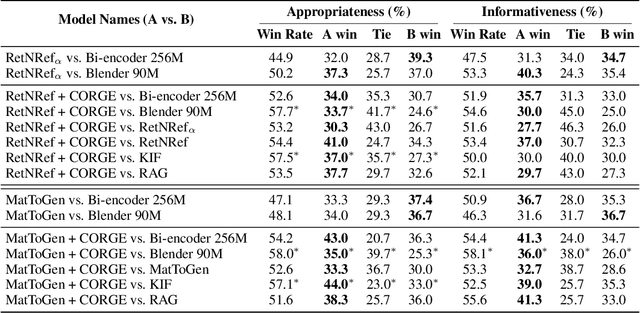
Exemplar-based generative models for open-domain conversation produce responses based on the exemplars provided by the retriever, taking advantage of generative models and retrieval models. However, they often ignore the retrieved exemplars while generating responses or produce responses over-fitted to the retrieved exemplars. In this paper, we argue that these drawbacks are derived from the one-to-many problem of the open-domain conversation. When the retrieved exemplar is relevant to the given context yet significantly different from the gold response, the exemplar-based generative models are trained to ignore the exemplar since the exemplar is not helpful for generating the gold response. On the other hand, when the retrieved exemplar is lexically similar to the gold response, the generative models are trained to rely on the exemplar highly. Therefore, we propose a training method selecting exemplars that are semantically relevant to the gold response but lexically distanced from the gold response to mitigate the above disadvantages. In the training phase, our proposed training method first uses the gold response instead of dialogue context as a query to select exemplars that are semantically relevant to the gold response. And then, it eliminates the exemplars that lexically resemble the gold responses to alleviate the dependency of the generative models on that exemplars. The remaining exemplars could be irrelevant to the given context since they are searched depending on the gold response. Thus, our proposed training method further utilizes the relevance scores between the given context and the exemplars to penalize the irrelevant exemplars. Extensive experiments demonstrate that our proposed training method alleviates the drawbacks of the existing exemplar-based generative models and significantly improves the performance in terms of appropriateness and informativeness.