 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Decision from Multiple Subtasks through Threshold Optimization: Content Moderation in the Wild
Aug 17, 2022
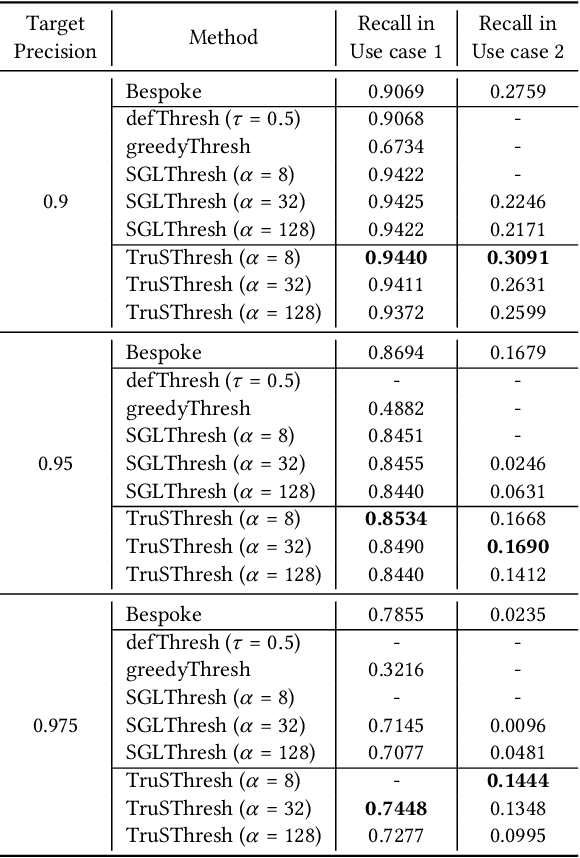
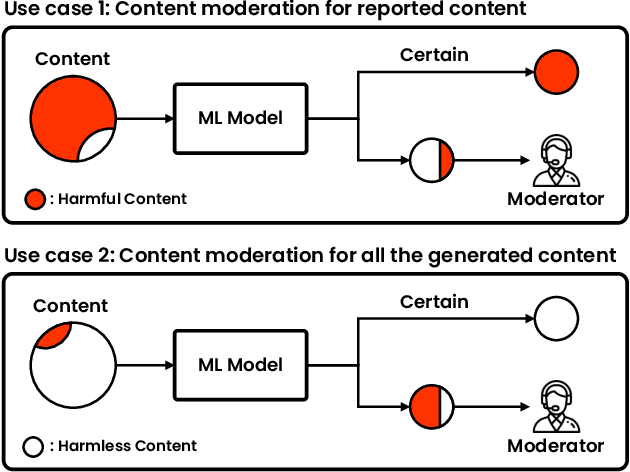
Social media platforms struggle to protect users from harmful content through content moderation. These platforms have recently leveraged machine learning models to cope with the vast amount of user-generated content daily. Since moderation policies vary depending on countries and types of products, it is common to train and deploy the models per policy. However, this approach is highly inefficient, especially when the policies change, requiring dataset re-labeling and model re-training on the shifted data distribution. To alleviate this cost inefficiency, social media platforms often employ third-party content moderation services that provide prediction scores of multiple subtasks, such as predicting the existence of underage personnel, rude gestures, or weapons, instead of directly providing final moderation decisions. However, making a reliable automated moderation decision from the prediction scores of the multiple subtasks for a specific target policy has not been widely explored yet. In this study, we formulate real-world scenarios of content moderation and introduce a simple yet effective threshold optimization method that searches the optimal thresholds of the multiple subtasks to make a reliable moderation decision in a cost-effective way. Extensive experiments demonstrate that our approach shows better performance in content moderation compared to existing threshold optimization methods and heuristics.
Towards Real-Time Automatic Portrait Matting on Mobile Devices
Apr 08, 2019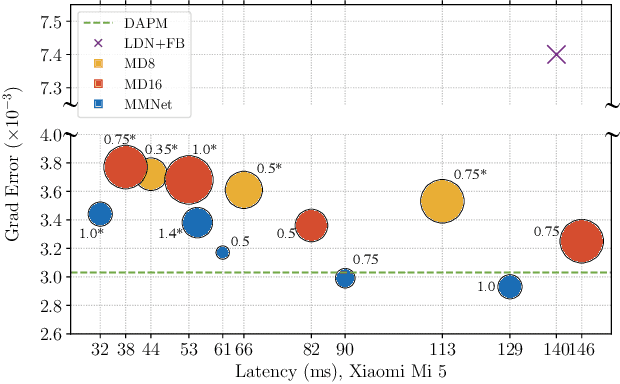
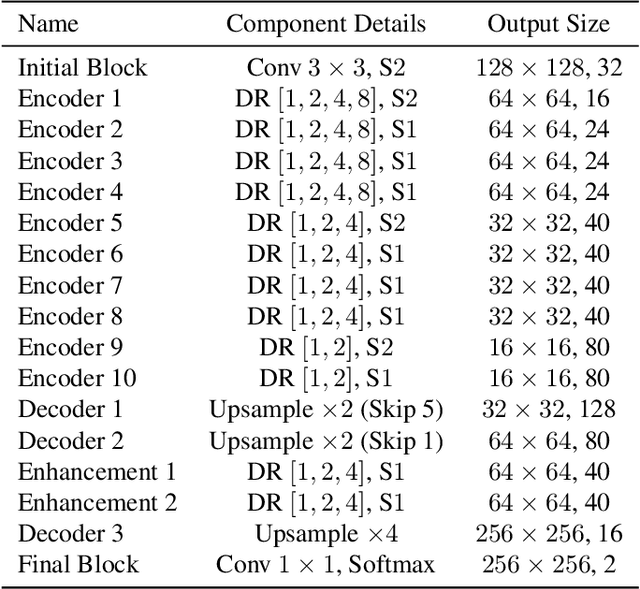

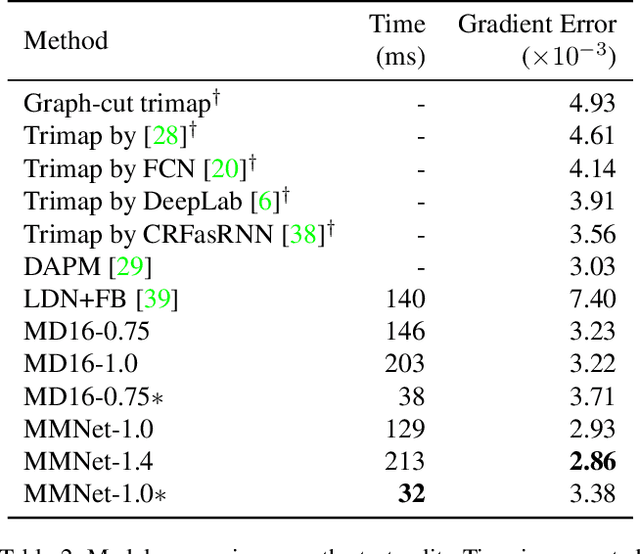
We tackle the problem of automatic portrait matting on mobile devices. The proposed model is aimed at attaining real-time inference on mobile devices with minimal degradation of model performance. Our model MMNet, based on multi-branch dilated convolution with linear bottleneck blocks, outperforms the state-of-the-art model and is orders of magnitude faster. The model can be accelerated four times to attain 30 FPS on Xiaomi Mi 5 device with moderate increase in the gradient error. Under the same conditions, our model has an order of magnitude less number of parameters and is faster than Mobile DeepLabv3 while maintaining comparable performance. The accompanied implementation can be found at \url{https://github.com/hyperconnect/MMNet}.
Temporal Convolution for Real-time Keyword Spotting on Mobile Devices
Apr 08, 2019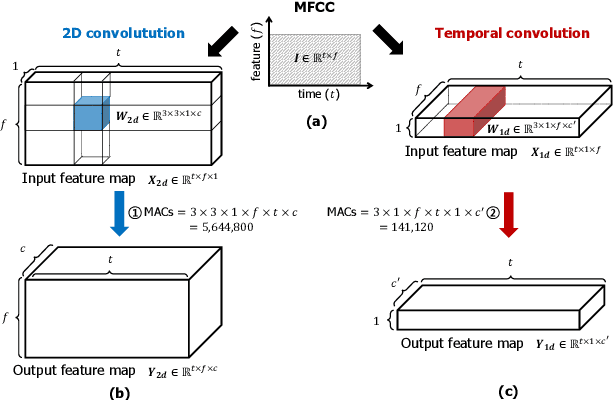
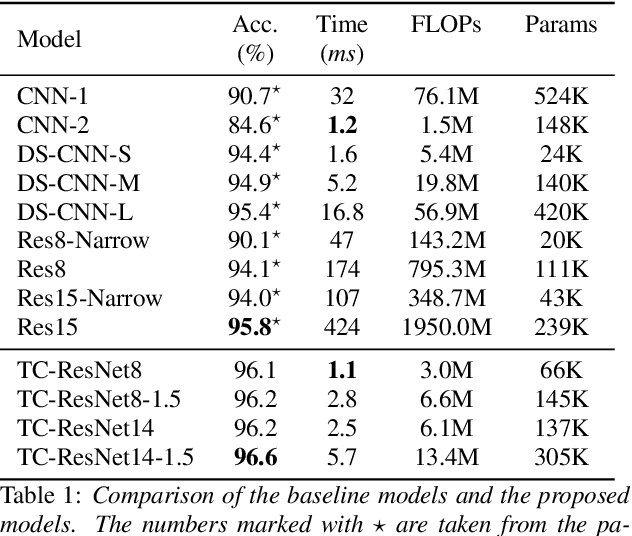
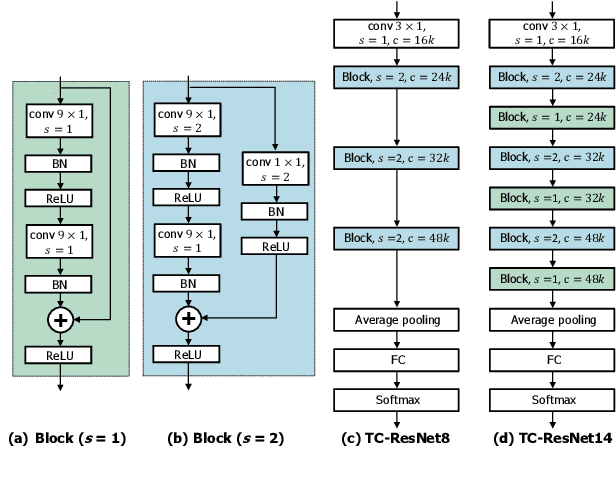
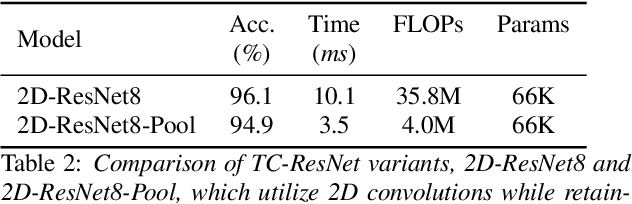
Keyword spotting (KWS) plays a critical role in enabling speech-based user interactions on smart devices. Recent developments in the field of deep learning have led to wide adoption of convolutional neural networks (CNNs) in KWS systems due to their exceptional accuracy and robustness. The main challenge faced by KWS systems is the trade-off between high accuracy and low latency. Unfortunately, there has been little quantitative analysis of the actual latency of KWS models on mobile devices. This is especially concerning since conventional convolution-based KWS approaches are known to require a large number of operations to attain an adequate level of performance. In this paper, we propose a temporal convolution for real-time KWS on mobile devices. Unlike most of the 2D convolution-based KWS approaches that require a deep architecture to fully capture both low- and high-frequency domains, we exploit temporal convolutions with a compact ResNet architecture. In Google Speech Command Dataset, we achieve more than \textbf{385x} speedup on Google Pixel 1 and surpass the accuracy compared to the state-of-the-art model. In addition, we release the implementation of the proposed and the baseline models including an end-to-end pipeline for training models and evaluating them on mobile devices.