 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Decision from Multiple Subtasks through Threshold Optimization: Content Moderation in the Wild
Aug 17, 2022
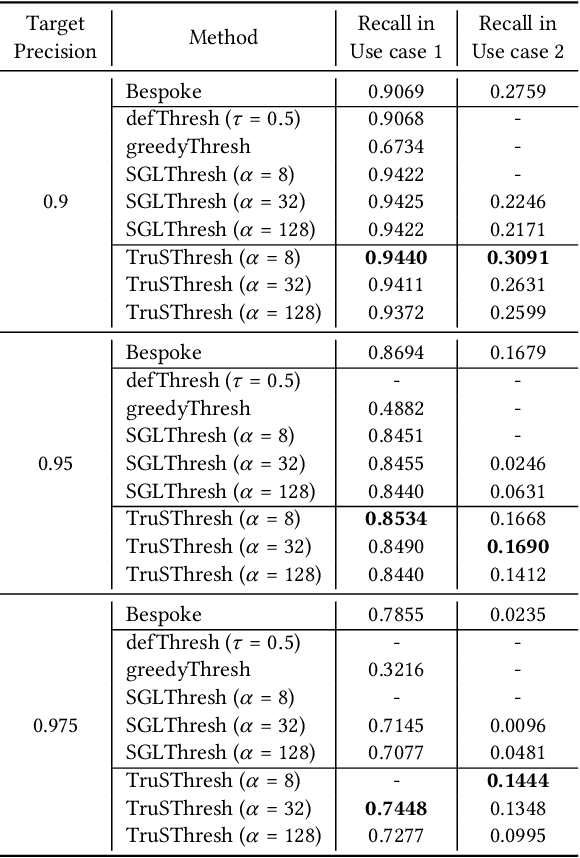
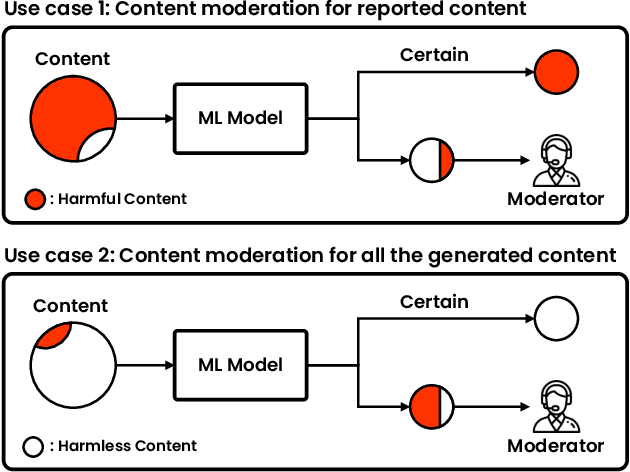
Social media platforms struggle to protect users from harmful content through content moderation. These platforms have recently leveraged machine learning models to cope with the vast amount of user-generated content daily. Since moderation policies vary depending on countries and types of products, it is common to train and deploy the models per policy. However, this approach is highly inefficient, especially when the policies change, requiring dataset re-labeling and model re-training on the shifted data distribution. To alleviate this cost inefficiency, social media platforms often employ third-party content moderation services that provide prediction scores of multiple subtasks, such as predicting the existence of underage personnel, rude gestures, or weapons, instead of directly providing final moderation decisions. However, making a reliable automated moderation decision from the prediction scores of the multiple subtasks for a specific target policy has not been widely explored yet. In this study, we formulate real-world scenarios of content moderation and introduce a simple yet effective threshold optimization method that searches the optimal thresholds of the multiple subtasks to make a reliable moderation decision in a cost-effective way. Extensive experiments demonstrate that our approach shows better performance in content moderation compared to existing threshold optimization methods and heuristics.
Reliable Estimation of Individual Treatment Effect with Causal Information Bottleneck
Jun 07, 2019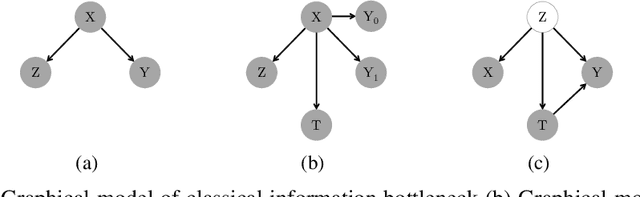



Estimating individual level treatment effects (ITE) from observational data is a challenging and important area in causal machine learning and is commonly considered in diverse mission-critical applications. In this paper, we propose an information theoretic approach in order to find more reliable representations for estimating ITE. We leverage the Information Bottleneck (IB) principle, which addresses the trade-off between conciseness and predictive power of representation. With the introduction of an extended graphical model for causal information bottleneck, we encourage the independence between the learned representation and the treatment type. We also introduce an additional form of a regularizer from the perspective of understanding ITE in the semi-supervised learning framework to ensure more reliable representations. Experimental results show that our model achieves the state-of-the-art results and exhibits more reliable prediction performances with uncertainty information on real-world datasets.