 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Estimation for Unseen Domain Risk Minimization with Pre-Trained Models
Feb 08, 2023



Domain generalization aims to build generalized models that perform well on unseen domains when only source domains are available for model optimization. Recent studies have demonstrated that large-scale pre-trained models could play an important role in domain generalization by providing their generalization power. However, large-scale pre-trained models are not fully equipped with target task-specific knowledge due to a discrepancy between the pre-training objective and the target task. Although the task-specific knowledge could be learned from source domains by fine-tuning, this hurts the generalization power of the pre-trained models because of gradient bias toward the source domains. To address this issue, we propose a new domain generalization method that estimates unobservable gradients that reduce potential risks in unseen domains, using a large-scale pre-trained model. Our proposed method allows the pre-trained model to learn task-specific knowledge further while preserving its generalization ability with the estimated gradients. Experimental results show that our proposed method outperforms baseline methods on DomainBed, a standard benchmark in domain generalization. We also provide extensive analyses to demonstrate that the estimated unobserved gradients relieve the gradient bias, and the pre-trained model learns the task-specific knowledge without sacrificing its generalization power.
Reliable Decision from Multiple Subtasks through Threshold Optimization: Content Moderation in the Wild
Aug 17, 2022
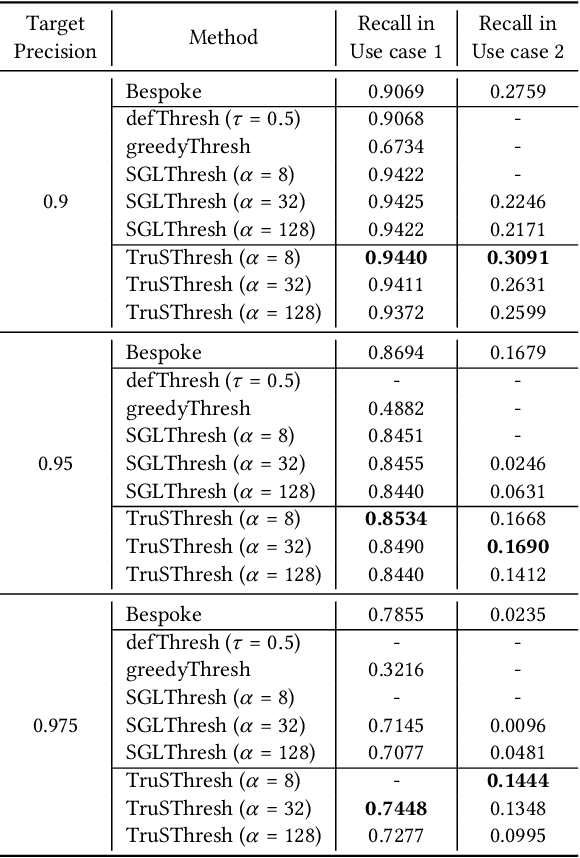
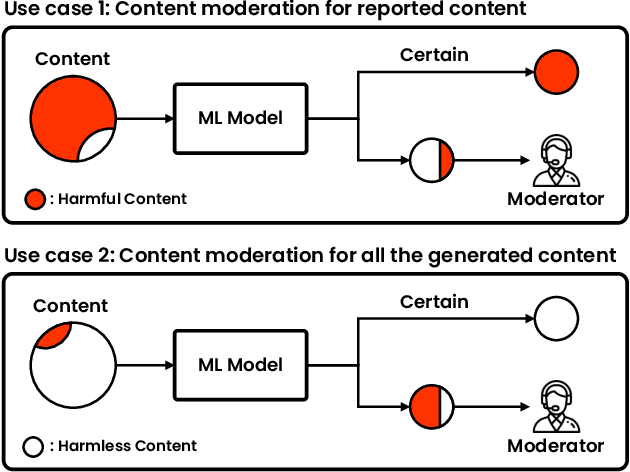
Social media platforms struggle to protect users from harmful content through content moderation. These platforms have recently leveraged machine learning models to cope with the vast amount of user-generated content daily. Since moderation policies vary depending on countries and types of products, it is common to train and deploy the models per policy. However, this approach is highly inefficient, especially when the policies change, requiring dataset re-labeling and model re-training on the shifted data distribution. To alleviate this cost inefficiency, social media platforms often employ third-party content moderation services that provide prediction scores of multiple subtasks, such as predicting the existence of underage personnel, rude gestures, or weapons, instead of directly providing final moderation decisions. However, making a reliable automated moderation decision from the prediction scores of the multiple subtasks for a specific target policy has not been widely explored yet. In this study, we formulate real-world scenarios of content moderation and introduce a simple yet effective threshold optimization method that searches the optimal thresholds of the multiple subtasks to make a reliable moderation decision in a cost-effective way. Extensive experiments demonstrate that our approach shows better performance in content moderation compared to existing threshold optimization methods and heuristics.