 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBBPE16: UTF-16-based byte-level byte-pair encoding for improved multilingual speech recognition
Feb 02, 2026Multilingual automatic speech recognition (ASR) requires tokenization that efficiently covers many writing systems. Byte-level BPE (BBPE) using UTF-8 is widely adopted for its language-agnostic design and full Unicode coverage, but its variable-length encoding inflates token sequences for non-Latin scripts, such as Chinese, Japanese, and Korean (CJK). Longer sequences increase computational load and memory use. We propose BBPE16, a UTF-16-based BBPE tokenizer that represents most modern scripts with a uniform 2-byte code unit. BBPE16 preserves BBPE's language-agnostic properties while substantially improving cross-lingual token sharing. Across monolingual, bilingual, and trilingual ASR, and in a multilingual continual-learning setup, BBPE16 attains comparable or better accuracy; for Chinese, it reduces token counts by up to 10.4% and lowers decoding iterations by up to 10.3%. These reductions speed up fine-tuning and inference and decrease memory usage, making BBPE16 a practical tokenization choice for multilingual ASR.
Self-Diagnosing GAN: Diagnosing Underrepresented Samples in Generative Adversarial Networks
Feb 24, 2021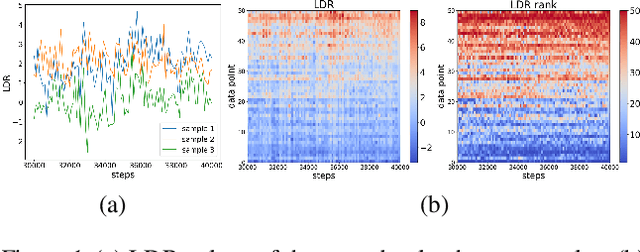
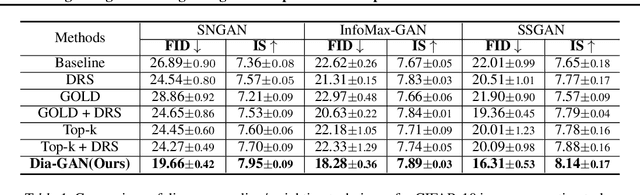
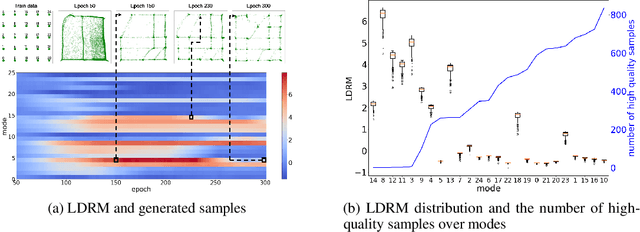

Despite remarkable performance in producing realistic samples, Generative Adversarial Networks (GANs) often produce low-quality samples near low-density regions of the data manifold. Recently, many techniques have been developed to improve the quality of generated samples, either by rejecting low-quality samples after training or by pre-processing the empirical data distribution before training, but at the cost of reduced diversity. To guarantee both the quality and the diversity, we propose a simple yet effective method to diagnose and emphasize underrepresented samples during training of a GAN. The main idea is to use the statistics of the discrepancy between the data distribution and the model distribution at each data instance. Based on the observation that the underrepresented samples have a high average discrepancy or high variability in discrepancy, we propose a method to emphasize those samples during training of a GAN. Our experimental results demonstrate that the proposed method improves GAN performance on various datasets, and it is especially effective in improving the quality of generated samples with minor features.