 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-Fit: Noisy-Label Detection based on the Overfitted Model Property
Paper and Code
Jun 14, 2021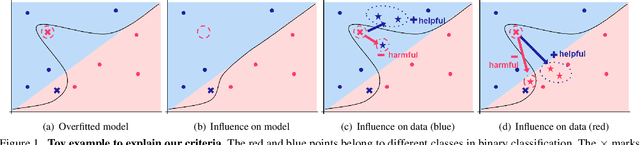
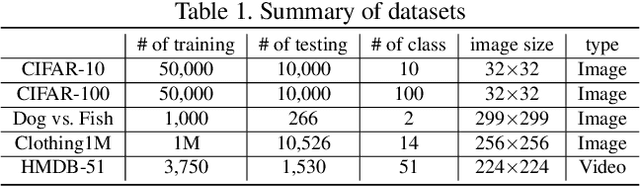
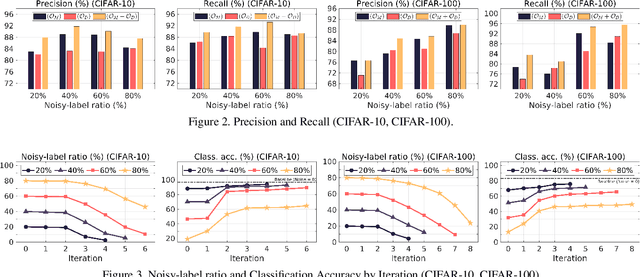
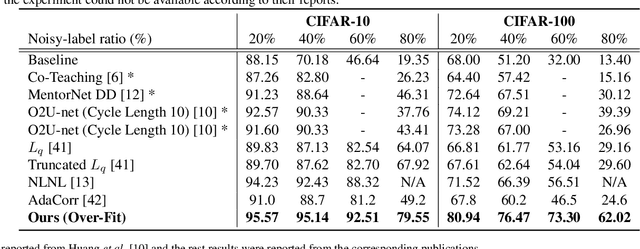
Due to the increasing need to handle the noisy label problem in a massive dataset, learning with noisy labels has received much attention in recent years. As a promising approach, there have been recent studies to select clean training data by finding small-loss instances before a deep neural network overfits the noisy-label data. However, it is challenging to prevent overfitting. In this paper, we propose a novel noisy-label detection algorithm by employing the property of overfitting on individual data points. To this end, we present two novel criteria that statistically measure how much each training sample abnormally affects the model and clean validation data. Using the criteria, our iterative algorithm removes noisy-label samples and retrains the model alternately until no further performance improvement is made. In experiments on multiple benchmark datasets, we demonstrate the validity of our algorithm and show that our algorithm outperforms the state-of-the-art methods when the exact noise rates are not given. Furthermore, we show that our method can not only be expanded to a real-world video dataset but also can be viewed as a regularization method to solve problems caused by overfitting.