 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrans-EnV: A Framework for Evaluating the Linguistic Robustness of LLMs Against English Varieties
May 27, 2025Large Language Models (LLMs) are predominantly evaluated on Standard American English (SAE), often overlooking the diversity of global English varieties. This narrow focus may raise fairness concerns as degraded performance on non-standard varieties can lead to unequal benefits for users worldwide. Therefore, it is critical to extensively evaluate the linguistic robustness of LLMs on multiple non-standard English varieties. We introduce Trans-EnV, a framework that automatically transforms SAE datasets into multiple English varieties to evaluate the linguistic robustness. Our framework combines (1) linguistics expert knowledge to curate variety-specific features and transformation guidelines from linguistic literature and corpora, and (2) LLM-based transformations to ensure both linguistic validity and scalability. Using Trans-EnV, we transform six benchmark datasets into 38 English varieties and evaluate seven state-of-the-art LLMs. Our results reveal significant performance disparities, with accuracy decreasing by up to 46.3% on non-standard varieties. These findings highlight the importance of comprehensive linguistic robustness evaluation across diverse English varieties. Each construction of Trans-EnV was validated through rigorous statistical testing and consultation with a researcher in the field of second language acquisition, ensuring its linguistic validity. Our \href{https://github.com/jiyounglee-0523/TransEnV}{code} and \href{https://huggingface.co/collections/jiyounglee0523/transenv-681eadb3c0c8cf363b363fb1}{datasets} are publicly available.
Expectations Versus Reality: Evaluating Intrusion Detection Systems in Practice
Mar 28, 2024



Our paper provides empirical comparisons between recent IDSs to provide an objective comparison between them to help users choose the most appropriate solution based on their requirements. Our results show that no one solution is the best, but is dependent on external variables such as the types of attacks, complexity, and network environment in the dataset. For example, BoT_IoT and Stratosphere IoT datasets both capture IoT-related attacks, but the deep neural network performed the best when tested using the BoT_IoT dataset while HELAD performed the best when tested using the Stratosphere IoT dataset. So although we found that a deep neural network solution had the highest average F1 scores on tested datasets, it is not always the best-performing one. We further discuss difficulties in using IDS from literature and project repositories, which complicated drawing definitive conclusions regarding IDS selection.
KorNAT: LLM Alignment Benchmark for Korean Social Values and Common Knowledge
Feb 22, 2024For Large Language Models (LLMs) to be effectively deployed in a specific country, they must possess an understanding of the nation's culture and basic knowledge. To this end, we introduce National Alignment, which measures an alignment between an LLM and a targeted country from two aspects: social value alignment and common knowledge alignment. Social value alignment evaluates how well the model understands nation-specific social values, while common knowledge alignment examines how well the model captures basic knowledge related to the nation. We constructed KorNAT, the first benchmark that measures national alignment with South Korea. For the social value dataset, we obtained ground truth labels from a large-scale survey involving 6,174 unique Korean participants. For the common knowledge dataset, we constructed samples based on Korean textbooks and GED reference materials. KorNAT contains 4K and 6K multiple-choice questions for social value and common knowledge, respectively. Our dataset creation process is meticulously designed and based on statistical sampling theory and was refined through multiple rounds of human review. The experiment results of seven LLMs reveal that only a few models met our reference score, indicating a potential for further enhancement. KorNAT has received government approval after passing an assessment conducted by a government-affiliated organization dedicated to evaluating dataset quality. Samples and detailed evaluation protocols of our dataset can be found in https://selectstar.ai/ko/papers-national-alignment
VisAlign: Dataset for Measuring the Degree of Alignment between AI and Humans in Visual Perception
Aug 03, 2023



AI alignment refers to models acting towards human-intended goals, preferences, or ethical principles. Given that most large-scale deep learning models act as black boxes and cannot be manually controlled, analyzing the similarity between models and humans can be a proxy measure for ensuring AI safety. In this paper, we focus on the models' visual perception alignment with humans, further referred to as AI-human visual alignment. Specifically, we propose a new dataset for measuring AI-human visual alignment in terms of image classification, a fundamental task in machine perception. In order to evaluate AI-human visual alignment, a dataset should encompass samples with various scenarios that may arise in the real world and have gold human perception labels. Our dataset consists of three groups of samples, namely Must-Act (i.e., Must-Classify), Must-Abstain, and Uncertain, based on the quantity and clarity of visual information in an image and further divided into eight categories. All samples have a gold human perception label; even Uncertain (severely blurry) sample labels were obtained via crowd-sourcing. The validity of our dataset is verified by sampling theory, statistical theories related to survey design, and experts in the related fields. Using our dataset, we analyze the visual alignment and reliability of five popular visual perception models and seven abstention methods. Our code and data is available at \url{https://github.com/jiyounglee-0523/VisAlign}.
Uncertainty-Aware Text-to-Program for Question Answering on Structured Electronic Health Records
Mar 14, 2022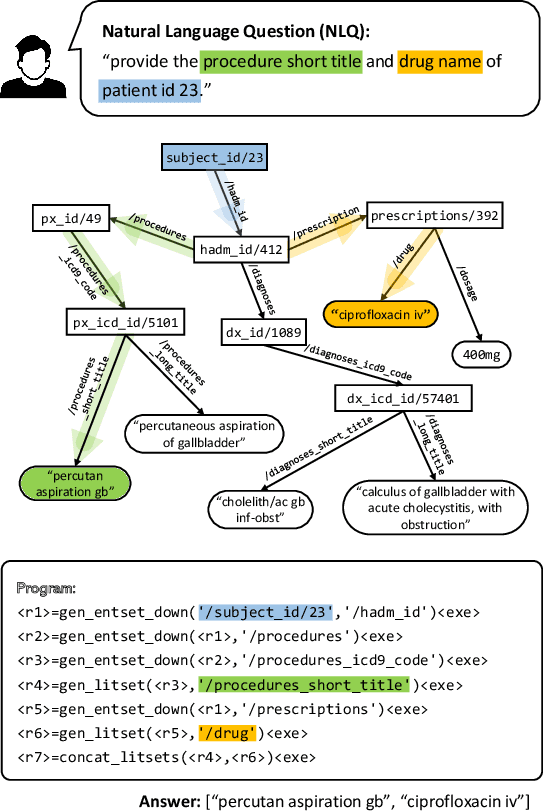



Question Answering on Electronic Health Records (EHR-QA) has a significant impact on the healthcare domain, and it is being actively studied. Previous research on structured EHR-QA focuses on converting natural language queries into query language such as SQL or SPARQL (NLQ2Query), so the problem scope is limited to pre-defined data types by the specific query language. In order to expand the EHR-QA task beyond this limitation to handle multi-modal medical data and solve complex inference in the future, more primitive systemic language is needed. In this paper, we design the program-based model (NLQ2Program) for EHR-QA as the first step towards the future direction. We tackle MIMICSPARQL*, the graph-based EHR-QA dataset, via a program-based approach in a semi-supervised manner in order to overcome the absence of gold programs. Without the gold program, our proposed model shows comparable performance to the previous state-of-the-art model, which is an NLQ2Query model (0.9\% gain). In addition, for a reliable EHR-QA model, we apply the uncertainty decomposition method to measure the ambiguity in the input question. We empirically confirmed data uncertainty is most indicative of the ambiguity in the input question.