 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Text-to-Program for Question Answering on Structured Electronic Health Records
Paper and Code
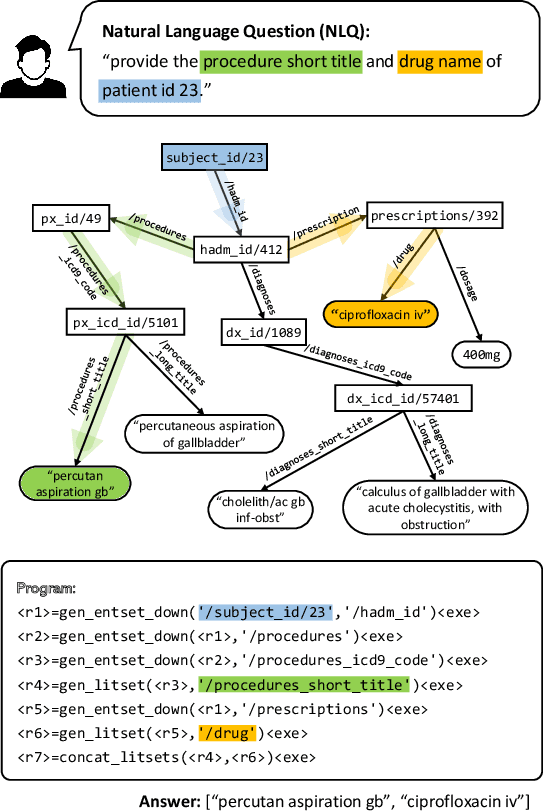



Question Answering on Electronic Health Records (EHR-QA) has a significant impact on the healthcare domain, and it is being actively studied. Previous research on structured EHR-QA focuses on converting natural language queries into query language such as SQL or SPARQL (NLQ2Query), so the problem scope is limited to pre-defined data types by the specific query language. In order to expand the EHR-QA task beyond this limitation to handle multi-modal medical data and solve complex inference in the future, more primitive systemic language is needed. In this paper, we design the program-based model (NLQ2Program) for EHR-QA as the first step towards the future direction. We tackle MIMICSPARQL*, the graph-based EHR-QA dataset, via a program-based approach in a semi-supervised manner in order to overcome the absence of gold programs. Without the gold program, our proposed model shows comparable performance to the previous state-of-the-art model, which is an NLQ2Query model (0.9\% gain). In addition, for a reliable EHR-QA model, we apply the uncertainty decomposition method to measure the ambiguity in the input question. We empirically confirmed data uncertainty is most indicative of the ambiguity in the input question.