 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite-Story: A Training-Free Consistent Text-to-Image Generation
Nov 17, 2025We present Infinite-Story, a training-free framework for consistent text-to-image (T2I) generation tailored for multi-prompt storytelling scenarios. Built upon a scale-wise autoregressive model, our method addresses two key challenges in consistent T2I generation: identity inconsistency and style inconsistency. To overcome these issues, we introduce three complementary techniques: Identity Prompt Replacement, which mitigates context bias in text encoders to align identity attributes across prompts; and a unified attention guidance mechanism comprising Adaptive Style Injection and Synchronized Guidance Adaptation, which jointly enforce global style and identity appearance consistency while preserving prompt fidelity. Unlike prior diffusion-based approaches that require fine-tuning or suffer from slow inference, Infinite-Story operates entirely at test time, delivering high identity and style consistency across diverse prompts. Extensive experiments demonstrate that our method achieves state-of-the-art generation performance, while offering over 6X faster inference (1.72 seconds per image) than the existing fastest consistent T2I models, highlighting its effectiveness and practicality for real-world visual storytelling.
A Training-Free Style-aligned Image Generation with Scale-wise Autoregressive Model
Apr 08, 2025

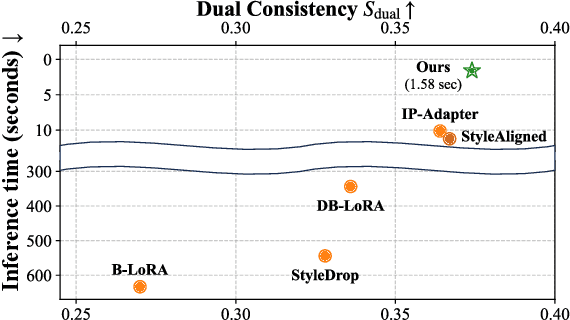
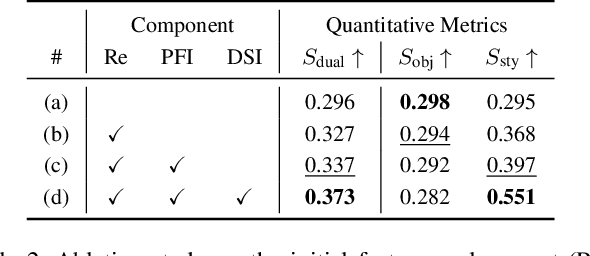
We present a training-free style-aligned image generation method that leverages a scale-wise autoregressive model. While large-scale text-to-image (T2I) models, particularly diffusion-based methods, have demonstrated impressive generation quality, they often suffer from style misalignment across generated image sets and slow inference speeds, limiting their practical usability. To address these issues, we propose three key components: initial feature replacement to ensure consistent background appearance, pivotal feature interpolation to align object placement, and dynamic style injection, which reinforces style consistency using a schedule function. Unlike previous methods requiring fine-tuning or additional training, our approach maintains fast inference while preserving individual content details. Extensive experiments show that our method achieves generation quality comparable to competing approaches, significantly improves style alignment, and delivers inference speeds over six times faster than the fastest model.
TEXTOC: Text-driven Object-Centric Style Transfer
Aug 16, 2024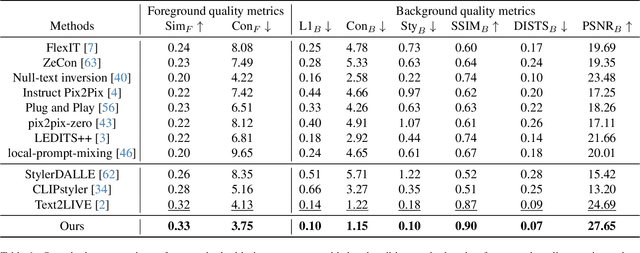

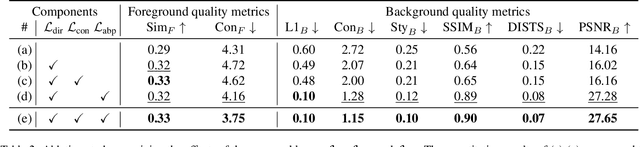
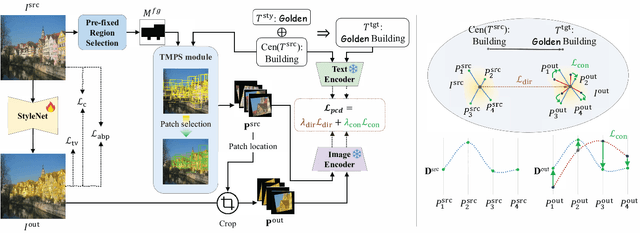
We present Text-driven Object-Centric Style Transfer (TEXTOC), a novel method that guides style transfer at an object-centric level using textual inputs. The core of TEXTOC is our Patch-wise Co-Directional (PCD) loss, meticulously designed for precise object-centric transformations that are closely aligned with the input text. This loss combines a patch directional loss for text-guided style direction and a patch distribution consistency loss for even CLIP embedding distribution across object regions. It ensures a seamless and harmonious style transfer across object regions. Key to our method are the Text-Matched Patch Selection (TMPS) and Pre-fixed Region Selection (PRS) modules for identifying object locations via text, eliminating the need for segmentation masks. Lastly, we introduce an Adaptive Background Preservation (ABP) loss to maintain the original style and structural essence of the image's background. This loss is applied to dynamically identified background areas. Extensive experiments underline the effectiveness of our approach in creating visually coherent and textually aligned style transfers.
Residual Features and Unified Prediction Network for Single Stage Detection
Jan 05, 2018

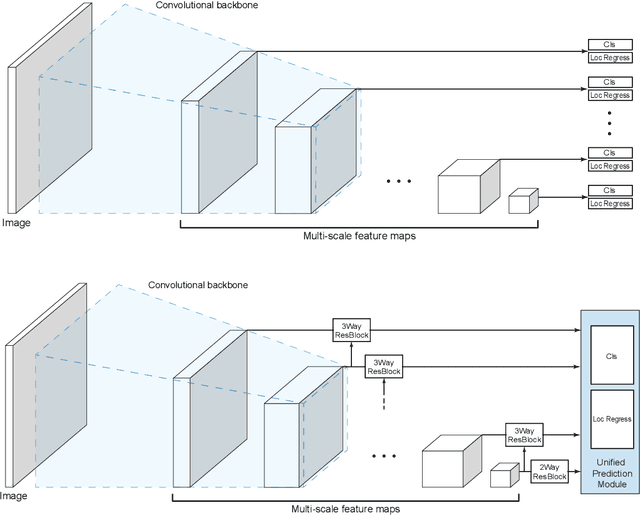
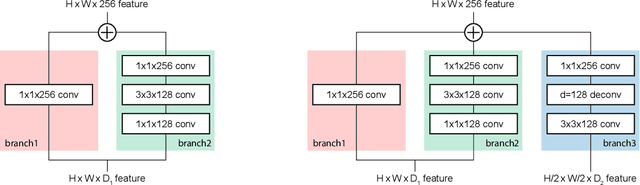
Recently, a lot of single stage detectors using multi-scale features have been actively proposed. They are much faster than two stage detectors that use region proposal networks (RPN) without much degradation in the detection performances. However, the feature maps in the lower layers close to the input which are responsible for detecting small objects in a single stage detector have a problem of insufficient representation power because they are too shallow. There is also a structural contradiction that the feature maps have to deliver low-level information to next layers as well as contain high-level abstraction for prediction. In this paper, we propose a method to enrich the representation power of feature maps using Resblock and deconvolution layers. In addition, a unified prediction module is applied to generalize output results and boost earlier layers' representation power for prediction. The proposed method enables more precise prediction, which achieved higher score than SSD on PASCAL VOC and MS COCO. In addition, it maintains the advantage of fast computation of a single stage detector, which requires much less computation than other detectors with similar performance. Code is available at https://github.com/kmlee-snu/run