 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite-Story: A Training-Free Consistent Text-to-Image Generation
Nov 17, 2025We present Infinite-Story, a training-free framework for consistent text-to-image (T2I) generation tailored for multi-prompt storytelling scenarios. Built upon a scale-wise autoregressive model, our method addresses two key challenges in consistent T2I generation: identity inconsistency and style inconsistency. To overcome these issues, we introduce three complementary techniques: Identity Prompt Replacement, which mitigates context bias in text encoders to align identity attributes across prompts; and a unified attention guidance mechanism comprising Adaptive Style Injection and Synchronized Guidance Adaptation, which jointly enforce global style and identity appearance consistency while preserving prompt fidelity. Unlike prior diffusion-based approaches that require fine-tuning or suffer from slow inference, Infinite-Story operates entirely at test time, delivering high identity and style consistency across diverse prompts. Extensive experiments demonstrate that our method achieves state-of-the-art generation performance, while offering over 6X faster inference (1.72 seconds per image) than the existing fastest consistent T2I models, highlighting its effectiveness and practicality for real-world visual storytelling.
Bridging Geometric and Semantic Foundation Models for Generalized Monocular Depth Estimation
May 29, 2025



We present Bridging Geometric and Semantic (BriGeS), an effective method that fuses geometric and semantic information within foundation models to enhance Monocular Depth Estimation (MDE). Central to BriGeS is the Bridging Gate, which integrates the complementary strengths of depth and segmentation foundation models. This integration is further refined by our Attention Temperature Scaling technique. It finely adjusts the focus of the attention mechanisms to prevent over-concentration on specific features, thus ensuring balanced performance across diverse inputs. BriGeS capitalizes on pre-trained foundation models and adopts a strategy that focuses on training only the Bridging Gate. This method significantly reduces resource demands and training time while maintaining the model's ability to generalize effectively. Extensive experiments across multiple challenging datasets demonstrate that BriGeS outperforms state-of-the-art methods in MDE for complex scenes, effectively handling intricate structures and overlapping objects.
A Training-Free Style-aligned Image Generation with Scale-wise Autoregressive Model
Apr 08, 2025

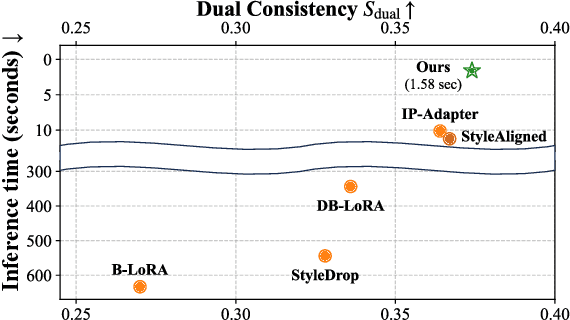
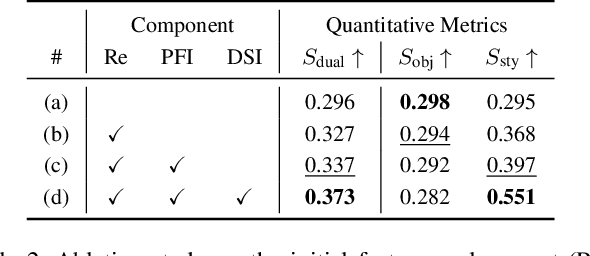
We present a training-free style-aligned image generation method that leverages a scale-wise autoregressive model. While large-scale text-to-image (T2I) models, particularly diffusion-based methods, have demonstrated impressive generation quality, they often suffer from style misalignment across generated image sets and slow inference speeds, limiting their practical usability. To address these issues, we propose three key components: initial feature replacement to ensure consistent background appearance, pivotal feature interpolation to align object placement, and dynamic style injection, which reinforces style consistency using a schedule function. Unlike previous methods requiring fine-tuning or additional training, our approach maintains fast inference while preserving individual content details. Extensive experiments show that our method achieves generation quality comparable to competing approaches, significantly improves style alignment, and delivers inference speeds over six times faster than the fastest model.
Flow4D: Leveraging 4D Voxel Network for LiDAR Scene Flow Estimation
Jul 10, 2024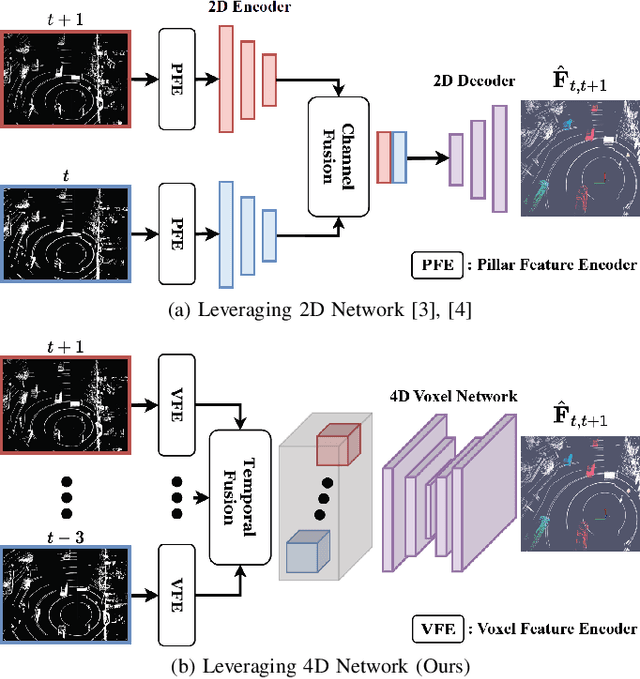
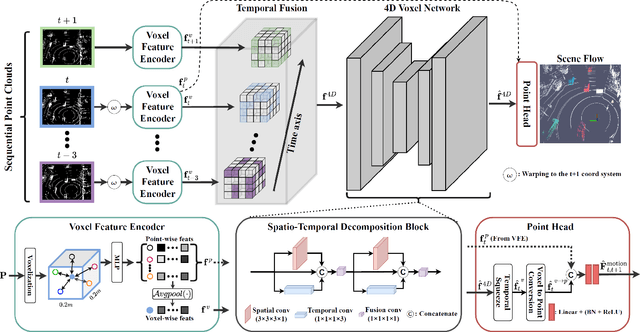
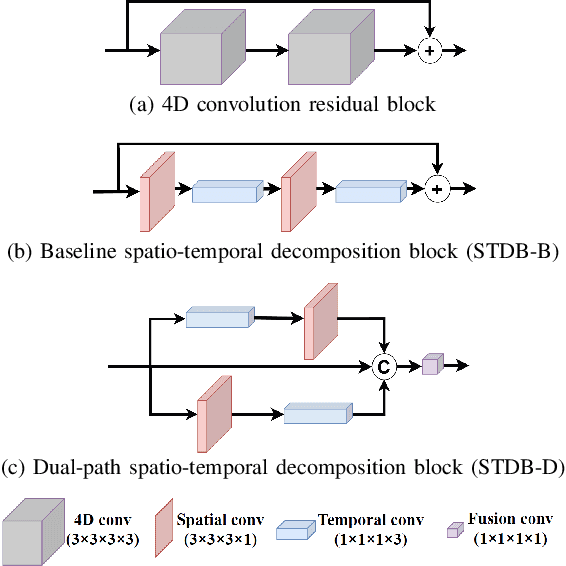
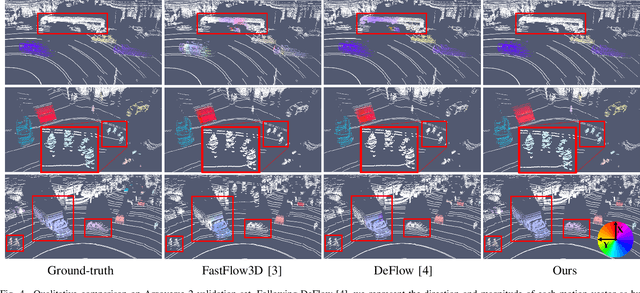
Understanding the motion states of the surrounding environment is critical for safe autonomous driving. These motion states can be accurately derived from scene flow, which captures the three-dimensional motion field of points. Existing LiDAR scene flow methods extract spatial features from each point cloud and then fuse them channel-wise, resulting in the implicit extraction of spatio-temporal features. Furthermore, they utilize 2D Bird's Eye View and process only two frames, missing crucial spatial information along the Z-axis and the broader temporal context, leading to suboptimal performance. To address these limitations, we propose Flow4D, which temporally fuses multiple point clouds after the 3D intra-voxel feature encoder, enabling more explicit extraction of spatio-temporal features through a 4D voxel network. However, while using 4D convolution improves performance, it significantly increases the computational load. For further efficiency, we introduce the Spatio-Temporal Decomposition Block (STDB), which combines 3D and 1D convolutions instead of using heavy 4D convolution. In addition, Flow4D further improves performance by using five frames to take advantage of richer temporal information. As a result, the proposed method achieves a 45.9% higher performance compared to the state-of-the-art while running in real-time, and won 1st place in the 2024 Argoverse 2 Scene Flow Challenge. The code is available at https://github.com/dgist-cvlab/Flow4D.
Domain Generalization in LiDAR Semantic Segmentation Leveraged by Density Discriminative Feature Embedding
Dec 19, 2023



While significant progress has been achieved in LiDAR-based perception, domain generalization continues to present challenges, often resulting in reduced performance when encountering unfamiliar datasets due to domain discrepancies. One of the primary hurdles stems from the variability of LiDAR sensors, leading to inconsistencies in point cloud density distribution. Such inconsistencies can undermine the effectiveness of perception models. We address this challenge by introducing a new approach that acknowledges a fundamental characteristic of LiDAR: the variation in point density due to the distance from the LiDAR to the scene, and the number of beams relative to the field of view. Understanding this, we view each LiDAR's point cloud at various distances as having distinct density distributions, which can be consistent across different LiDAR models. With this insight, we propose the Density Discriminative Feature Embedding (DDFE) module, crafted to specifically extract features related to density while ensuring domain invariance across different LiDAR sensors. In addition, we introduce a straightforward but effective density augmentation technique, designed to broaden the density spectrum and enhance the capabilities of the DDFE. The proposed DDFE stands out as a versatile and lightweight domain generalization module. It can be seamlessly integrated into various 3D backbone networks, consistently outperforming existing state-of-the-art domain generalization approaches. We commit to releasing the source code publicly to foster community collaboration and advancement.