 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVA: Context-aware Video-text Alignment for Video Temporal Grounding
Mar 26, 2026We propose Context-aware Video-text Alignment (CVA), a novel framework to address a significant challenge in video temporal grounding: achieving temporally sensitive video-text alignment that remains robust to irrelevant background context. Our framework is built on three key components. First, we propose Query-aware Context Diversification (QCD), a new data augmentation strategy that ensures only semantically unrelated content is mixed in. It builds a video-text similarity-based pool of replacement clips to simulate diverse contexts while preventing the ``false negative" caused by query-agnostic mixing. Second, we introduce the Context-invariant Boundary Discrimination (CBD) loss, a contrastive loss that enforces semantic consistency at challenging temporal boundaries, making their representations robust to contextual shifts and hard negatives. Third, we introduce the Context-enhanced Transformer Encoder (CTE), a hierarchical architecture that combines windowed self-attention and bidirectional cross-attention with learnable queries to capture multi-scale temporal context. Through the synergy of these data-centric and architectural enhancements, CVA achieves state-of-the-art performance on major VTG benchmarks, including QVHighlights and Charades-STA. Notably, our method achieves a significant improvement of approximately 5 points in Recall@1 (R1) scores over state-of-the-art methods, highlighting its effectiveness in mitigating false negatives.
VLF-MSC: Vision-Language Feature-Based Multimodal Semantic Communication System
Nov 13, 2025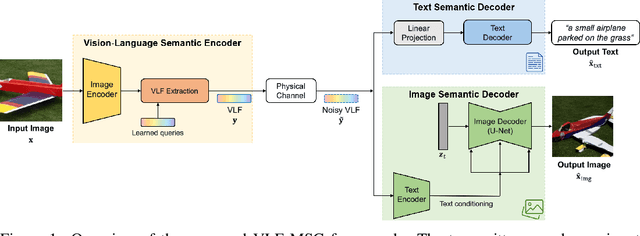
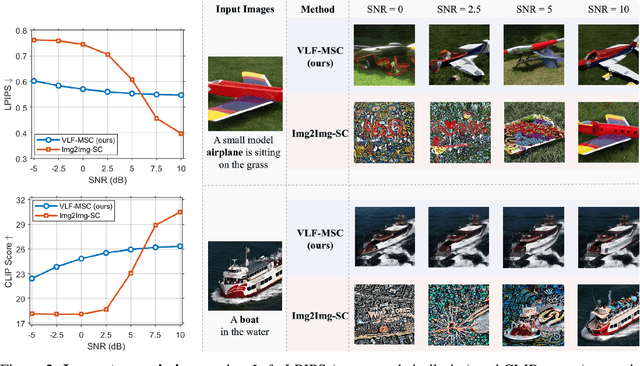
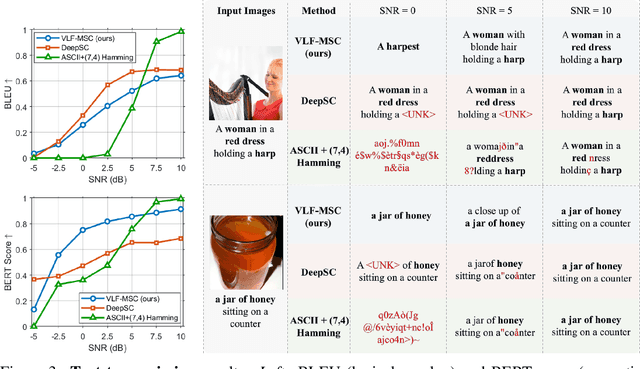

We propose Vision-Language Feature-based Multimodal Semantic Communication (VLF-MSC), a unified system that transmits a single compact vision-language representation to support both image and text generation at the receiver. Unlike existing semantic communication techniques that process each modality separately, VLF-MSC employs a pre-trained vision-language model (VLM) to encode the source image into a vision-language semantic feature (VLF), which is transmitted over the wireless channel. At the receiver, a decoder-based language model and a diffusion-based image generator are both conditioned on the VLF to produce a descriptive text and a semantically aligned image. This unified representation eliminates the need for modality-specific streams or retransmissions, improving spectral efficiency and adaptability. By leveraging foundation models, the system achieves robustness to channel noise while preserving semantic fidelity. Experiments demonstrate that VLF-MSC outperforms text-only and image-only baselines, achieving higher semantic accuracy for both modalities under low SNR with significantly reduced bandwidth.
Bridging Geometric and Semantic Foundation Models for Generalized Monocular Depth Estimation
May 29, 2025



We present Bridging Geometric and Semantic (BriGeS), an effective method that fuses geometric and semantic information within foundation models to enhance Monocular Depth Estimation (MDE). Central to BriGeS is the Bridging Gate, which integrates the complementary strengths of depth and segmentation foundation models. This integration is further refined by our Attention Temperature Scaling technique. It finely adjusts the focus of the attention mechanisms to prevent over-concentration on specific features, thus ensuring balanced performance across diverse inputs. BriGeS capitalizes on pre-trained foundation models and adopts a strategy that focuses on training only the Bridging Gate. This method significantly reduces resource demands and training time while maintaining the model's ability to generalize effectively. Extensive experiments across multiple challenging datasets demonstrate that BriGeS outperforms state-of-the-art methods in MDE for complex scenes, effectively handling intricate structures and overlapping objects.
Context-Aware Video Instance Segmentation
Jul 03, 2024



In this paper, we introduce the Context-Aware Video Instance Segmentation (CAVIS), a novel framework designed to enhance instance association by integrating contextual information adjacent to each object. To efficiently extract and leverage this information, we propose the Context-Aware Instance Tracker (CAIT), which merges contextual data surrounding the instances with the core instance features to improve tracking accuracy. Additionally, we introduce the Prototypical Cross-frame Contrastive (PCC) loss, which ensures consistency in object-level features across frames, thereby significantly enhancing instance matching accuracy. CAVIS demonstrates superior performance over state-of-the-art methods on all benchmark datasets in video instance segmentation (VIS) and video panoptic segmentation (VPS). Notably, our method excels on the OVIS dataset, which is known for its particularly challenging videos.
RAQ-VAE: Rate-Adaptive Vector-Quantized Variational Autoencoder
May 23, 2024



Vector Quantized Variational AutoEncoder (VQ-VAE) is an established technique in machine learning for learning discrete representations across various modalities. However, its scalability and applicability are limited by the need to retrain the model to adjust the codebook for different data or model scales. We introduce the Rate-Adaptive VQ-VAE (RAQ-VAE) framework, which addresses this challenge with two novel codebook representation methods: a model-based approach using a clustering-based technique on an existing well-trained VQ-VAE model, and a data-driven approach utilizing a sequence-to-sequence (Seq2Seq) model for variable-rate codebook generation. Our experiments demonstrate that RAQ-VAE achieves effective reconstruction performance across multiple rates, often outperforming conventional fixed-rate VQ-VAE models. This work enhances the adaptability and performance of VQ-VAEs, with broad applications in data reconstruction, generation, and computer vision tasks.