 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Solve Generative ODEs Beyond the Linear Span
Jun 07, 2026Diffusion and flow generative models sample by integrating a learned ODE, but high quality still requires many sequential model evaluations. Solver learning reduces this cost by adapting scalar coefficients, timesteps, or both, while keeping the backbone model fixed. In this work, we identify a structural bottleneck in this update family: each step remains span-limited. Since the scalar-coefficient update lies in the span of buffered velocity evaluations, it can fit only the in-span component while leaving any out-of-span residual unreachable by scalar recombination alone. We propose SpanLift, a lightweight neural solver that augments scalar-coefficient updates with a spatial residual operator. SpanLift keeps a fixed base solver as an in-span prior and learns a spatial residual operator over the state and velocity buffer. The operator is trained by endpoint teacher matching, preserves the pretrained backbone, and adds no model NFEs. Empirically, the learned correction transfers across base solvers and is predominantly out-of-span. Across pixel-space diffusion, latent flow matching, and precipitation nowcasting, SpanLift achieves state-of-the-art few-step sampling. With only 3 NFE, it improves CIFAR-10 FID from 8.16 to 5.69 and ImageNet FID from 17.37 to 11.83.
Low-Latency Edge LLM Handover via Joint KV Cache Transfer and Token Prefill
Mar 30, 2026Edge deployment of large language models (LLMs) can reduce latency for interactive services, but mobility introduces service interruptions when an user equipment (UE) hands over between base stations (BSs). To promptly resume decoding, the target-side edge server must recover the UE context state, which can be provisioned either by token forwarding followed by prefill computation or by direct key-value (KV) cache transmission over backhaul. This paper proposes a unified handover (HO) design that jointly selects the prefill length and schedules backhaul KV cache delivery to minimize the worst-user LLM HO delay for multiple UEs. The resulting scheme admits a tractable step-wise solution with explicit feasibility conditions and a constructive rate-scheduling policy. Simulations show that the proposed method consistently outperforms baselines across a wide range of backhaul capacities, prefill speeds, and context sizes, providing practical guidelines for mobility-aware Edge LLM token streaming.
CVA: Context-aware Video-text Alignment for Video Temporal Grounding
Mar 26, 2026We propose Context-aware Video-text Alignment (CVA), a novel framework to address a significant challenge in video temporal grounding: achieving temporally sensitive video-text alignment that remains robust to irrelevant background context. Our framework is built on three key components. First, we propose Query-aware Context Diversification (QCD), a new data augmentation strategy that ensures only semantically unrelated content is mixed in. It builds a video-text similarity-based pool of replacement clips to simulate diverse contexts while preventing the ``false negative" caused by query-agnostic mixing. Second, we introduce the Context-invariant Boundary Discrimination (CBD) loss, a contrastive loss that enforces semantic consistency at challenging temporal boundaries, making their representations robust to contextual shifts and hard negatives. Third, we introduce the Context-enhanced Transformer Encoder (CTE), a hierarchical architecture that combines windowed self-attention and bidirectional cross-attention with learnable queries to capture multi-scale temporal context. Through the synergy of these data-centric and architectural enhancements, CVA achieves state-of-the-art performance on major VTG benchmarks, including QVHighlights and Charades-STA. Notably, our method achieves a significant improvement of approximately 5 points in Recall@1 (R1) scores over state-of-the-art methods, highlighting its effectiveness in mitigating false negatives.
Low-Complexity Semantic Packet Aggregation for Token Communication via Lookahead Search
Jun 24, 2025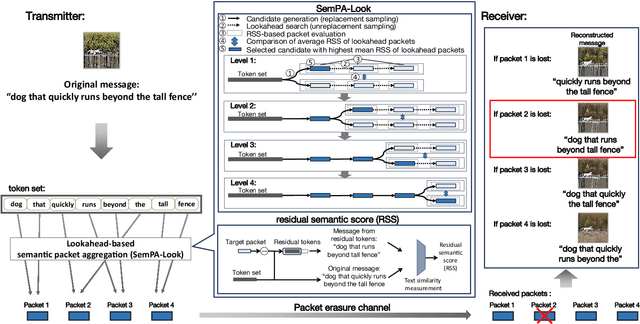
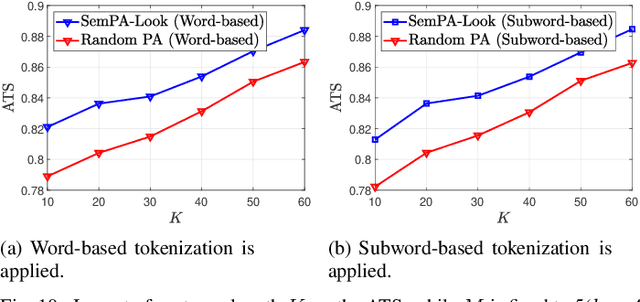
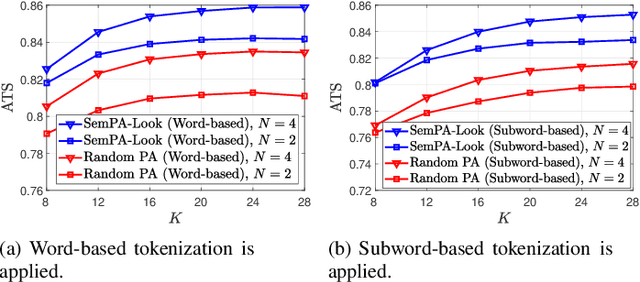
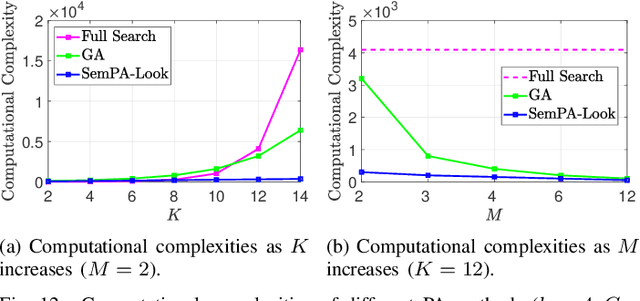
Tokens are fundamental processing units of generative AI (GenAI) and large language models (LLMs), and token communication (TC) is essential for enabling remote AI-generate content (AIGC) and wireless LLM applications. Unlike traditional bits, each of which is independently treated, the semantics of each token depends on its surrounding context tokens. This inter-token dependency makes TC vulnerable to outage channels, where the loss of a single token can significantly distort the original message semantics. Motivated by this, this paper focuses on optimizing token packetization to maximize the average token similarity (ATS) between the original and received token messages under outage channels. Due to inter-token dependency, this token grouping problem is combinatorial, with complexity growing exponentially with message length. To address this, we propose a novel framework of semantic packet aggregation with lookahead search (SemPA-Look), built on two core ideas. First, it introduces the residual semantic score (RSS) as a token-level surrogate for the message-level ATS, allowing robust semantic preservation even when a certain token packet is lost. Second, instead of full search, SemPA-Look applies a lookahead search-inspired algorithm that samples intra-packet token candidates without replacement (fixed depth), conditioned on inter-packet token candidates sampled with replacement (fixed width), thereby achieving linear complexity. Experiments on a remote AIGC task with the MS-COCO dataset (text captioned images) demonstrate that SemPA-Look achieves high ATS and LPIPS scores comparable to exhaustive search, while reducing computational complexity by up to 40$\times$. Compared to other linear-complexity algorithms such as the genetic algorithm (GA), SemPA-Look achieves 10$\times$ lower complexity, demonstrating its practicality for remote AIGC and other TC applications.
Bridging Geometric and Semantic Foundation Models for Generalized Monocular Depth Estimation
May 29, 2025



We present Bridging Geometric and Semantic (BriGeS), an effective method that fuses geometric and semantic information within foundation models to enhance Monocular Depth Estimation (MDE). Central to BriGeS is the Bridging Gate, which integrates the complementary strengths of depth and segmentation foundation models. This integration is further refined by our Attention Temperature Scaling technique. It finely adjusts the focus of the attention mechanisms to prevent over-concentration on specific features, thus ensuring balanced performance across diverse inputs. BriGeS capitalizes on pre-trained foundation models and adopts a strategy that focuses on training only the Bridging Gate. This method significantly reduces resource demands and training time while maintaining the model's ability to generalize effectively. Extensive experiments across multiple challenging datasets demonstrate that BriGeS outperforms state-of-the-art methods in MDE for complex scenes, effectively handling intricate structures and overlapping objects.
Semantic Packet Aggregation for Token Communication via Genetic Beam Search
Apr 28, 2025Token communication (TC) is poised to play a pivotal role in emerging language-driven applications such as AI-generated content (AIGC) and wireless language models (LLMs). However, token loss caused by channel noise can severely degrade task performance. To address this, in this article, we focus on the problem of semantics-aware packetization and develop a novel algorithm, termed semantic packet aggregation with genetic beam search (SemPA-GBeam), which aims to maximize the average token similarity (ATS) over erasure channels. Inspired from the genetic algorithm (GA) and the beam search algorithm, SemPA-GBeam iteratively optimizes token grouping for packetization within a fixed number of groups (i.e., fixed beam width in beam search) while randomly swapping a fraction of tokens (i.e., mutation in GA). Experiments on the MS-COCO dataset demonstrate that SemPA-GBeam achieves ATS and LPIPS scores comparable to exhaustive search while reducing complexity by more than 20x.
Latent Bayesian Optimization via Autoregressive Normalizing Flows
Apr 21, 2025Bayesian Optimization (BO) has been recognized for its effectiveness in optimizing expensive and complex objective functions. Recent advancements in Latent Bayesian Optimization (LBO) have shown promise by integrating generative models such as variational autoencoders (VAEs) to manage the complexity of high-dimensional and structured data spaces. However, existing LBO approaches often suffer from the value discrepancy problem, which arises from the reconstruction gap between input and latent spaces. This value discrepancy problem propagates errors throughout the optimization process, leading to suboptimal outcomes. To address this issue, we propose a Normalizing Flow-based Bayesian Optimization (NF-BO), which utilizes normalizing flow as a generative model to establish one-to-one encoding function from the input space to the latent space, along with its left-inverse decoding function, eliminating the reconstruction gap. Specifically, we introduce SeqFlow, an autoregressive normalizing flow for sequence data. In addition, we develop a new candidate sampling strategy that dynamically adjusts the exploration probability for each token based on its importance. Through extensive experiments, our NF-BO method demonstrates superior performance in molecule generation tasks, significantly outperforming both traditional and recent LBO approaches.
Semantic Packet Aggregation and Repeated Transmission for Text-to-Image Generation
Mar 31, 2025
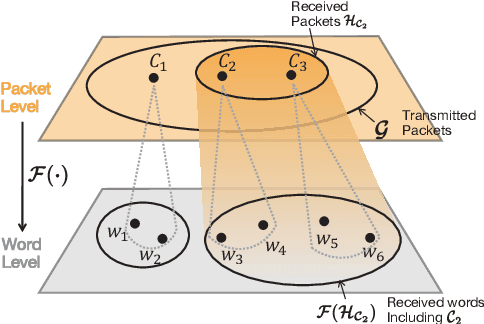
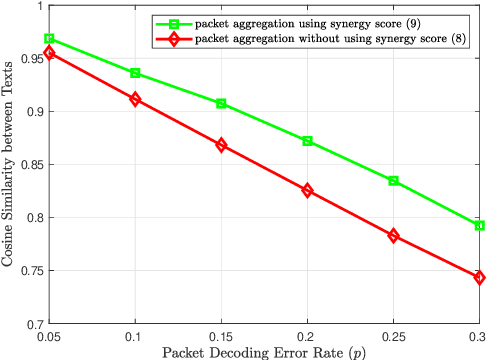
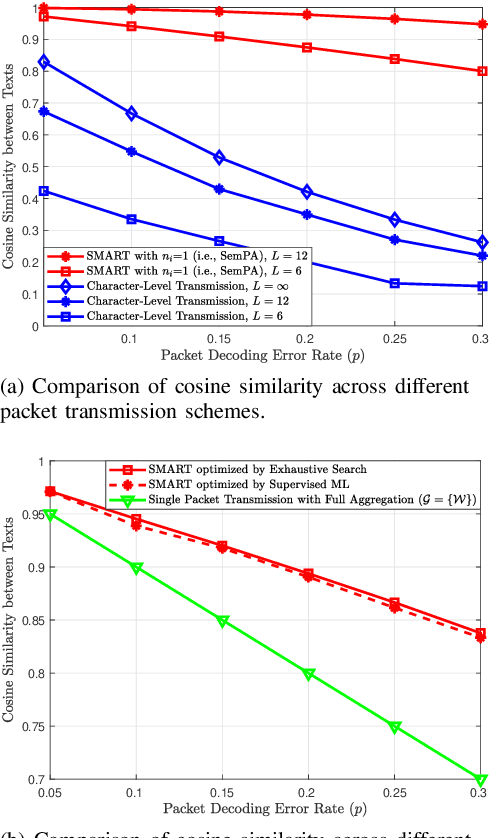
Text-based communication is expected to be prevalent in 6G applications such as wireless AI-generated content (AIGC). Motivated by this, this paper addresses the challenges of transmitting text prompts over erasure channels for a text-to-image AIGC task by developing the semantic segmentation and repeated transmission (SMART) algorithm. SMART groups words in text prompts into packets, prioritizing the task-specific significance of semantics within these packets, and optimizes the number of repeated transmissions. Simulation results show that SMART achieves higher similarities in received texts and generated images compared to a character-level packetization baseline, while reducing computing latency by orders of magnitude compared to an exhaustive search baseline.
Rapid analysis of point-contact Andreev reflection spectra via machine learning with adaptive data augmentation
Mar 13, 2025


Delineating the superconducting order parameters is a pivotal task in investigating superconductivity for probing pairing mechanisms, as well as their symmetry and topology. Point-contact Andreev reflection (PCAR) measurement is a simple yet powerful tool for identifying the order parameters. The PCAR spectra exhibit significant variations depending on the type of the order parameter in a superconductor, including its magnitude ($\mathit{\Delta}$), as well as temperature, interfacial quality, Fermi velocity mismatch, and other factors. The information on the order parameter can be obtained by finding the combination of these parameters, generating a theoretical spectrum that fits a measured experimental spectrum. However, due to the complexity of the spectra and the high dimensionality of parameters, extracting the fitting parameters is often time-consuming and labor-intensive. In this study, we employ a convolutional neural network (CNN) algorithm to create models for rapid and automated analysis of PCAR spectra of various superconductors with different pairing symmetries (conventional $s$-wave, chiral $p_x+ip_y$-wave, and $d_{x^2-y^2}$-wave). The training datasets are generated based on the Blonder-Tinkham-Klapwijk (BTK) theory and further modified and augmented by selectively incorporating noise and peaks according to the bias voltages. This approach not only replicates the experimental spectra but also brings the model's attention to important features within the spectra. The optimized models provide fitting parameters for experimentally measured spectra in less than 100 ms per spectrum. Our approaches and findings pave the way for rapid and automated spectral analysis which will help accelerate research on superconductors with complex order parameters.
Inversion-based Latent Bayesian Optimization
Nov 08, 2024



Latent Bayesian optimization (LBO) approaches have successfully adopted Bayesian optimization over a continuous latent space by employing an encoder-decoder architecture to address the challenge of optimization in a high dimensional or discrete input space. LBO learns a surrogate model to approximate the black-box objective function in the latent space. However, we observed that most LBO methods suffer from the `misalignment problem`, which is induced by the reconstruction error of the encoder-decoder architecture. It hinders learning an accurate surrogate model and generating high-quality solutions. In addition, several trust region-based LBO methods select the anchor, the center of the trust region, based solely on the objective function value without considering the trust region`s potential to enhance the optimization process. To address these issues, we propose Inversion-based Latent Bayesian Optimization (InvBO), a plug-and-play module for LBO. InvBO consists of two components: an inversion method and a potential-aware trust region anchor selection. The inversion method searches the latent code that completely reconstructs the given target data. The potential-aware trust region anchor selection considers the potential capability of the trust region for better local optimization. Experimental results demonstrate the effectiveness of InvBO on nine real-world benchmarks, such as molecule design and arithmetic expression fitting tasks. Code is available at https://github.com/mlvlab/InvBO.