 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Bayesian Optimization via Autoregressive Normalizing Flows
Apr 21, 2025Bayesian Optimization (BO) has been recognized for its effectiveness in optimizing expensive and complex objective functions. Recent advancements in Latent Bayesian Optimization (LBO) have shown promise by integrating generative models such as variational autoencoders (VAEs) to manage the complexity of high-dimensional and structured data spaces. However, existing LBO approaches often suffer from the value discrepancy problem, which arises from the reconstruction gap between input and latent spaces. This value discrepancy problem propagates errors throughout the optimization process, leading to suboptimal outcomes. To address this issue, we propose a Normalizing Flow-based Bayesian Optimization (NF-BO), which utilizes normalizing flow as a generative model to establish one-to-one encoding function from the input space to the latent space, along with its left-inverse decoding function, eliminating the reconstruction gap. Specifically, we introduce SeqFlow, an autoregressive normalizing flow for sequence data. In addition, we develop a new candidate sampling strategy that dynamically adjusts the exploration probability for each token based on its importance. Through extensive experiments, our NF-BO method demonstrates superior performance in molecule generation tasks, significantly outperforming both traditional and recent LBO approaches.
Inversion-based Latent Bayesian Optimization
Nov 08, 2024



Latent Bayesian optimization (LBO) approaches have successfully adopted Bayesian optimization over a continuous latent space by employing an encoder-decoder architecture to address the challenge of optimization in a high dimensional or discrete input space. LBO learns a surrogate model to approximate the black-box objective function in the latent space. However, we observed that most LBO methods suffer from the `misalignment problem`, which is induced by the reconstruction error of the encoder-decoder architecture. It hinders learning an accurate surrogate model and generating high-quality solutions. In addition, several trust region-based LBO methods select the anchor, the center of the trust region, based solely on the objective function value without considering the trust region`s potential to enhance the optimization process. To address these issues, we propose Inversion-based Latent Bayesian Optimization (InvBO), a plug-and-play module for LBO. InvBO consists of two components: an inversion method and a potential-aware trust region anchor selection. The inversion method searches the latent code that completely reconstructs the given target data. The potential-aware trust region anchor selection considers the potential capability of the trust region for better local optimization. Experimental results demonstrate the effectiveness of InvBO on nine real-world benchmarks, such as molecule design and arithmetic expression fitting tasks. Code is available at https://github.com/mlvlab/InvBO.
vid-TLDR: Training Free Token merging for Light-weight Video Transformer
Mar 30, 2024



Video Transformers have become the prevalent solution for various video downstream tasks with superior expressive power and flexibility. However, these video transformers suffer from heavy computational costs induced by the massive number of tokens across the entire video frames, which has been the major barrier to training the model. Further, the patches irrelevant to the main contents, e.g., backgrounds, degrade the generalization performance of models. To tackle these issues, we propose training free token merging for lightweight video Transformer (vid-TLDR) that aims to enhance the efficiency of video Transformers by merging the background tokens without additional training. For vid-TLDR, we introduce a novel approach to capture the salient regions in videos only with the attention map. Further, we introduce the saliency-aware token merging strategy by dropping the background tokens and sharpening the object scores. Our experiments show that vid-TLDR significantly mitigates the computational complexity of video Transformers while achieving competitive performance compared to the base model without vid-TLDR. Code is available at https://github.com/mlvlab/vid-TLDR.
Advancing Bayesian Optimization via Learning Correlated Latent Space
Nov 20, 2023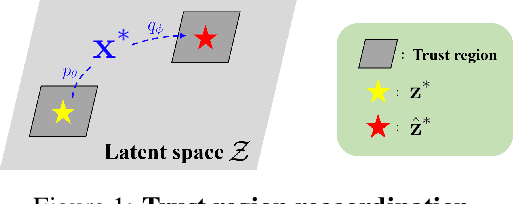

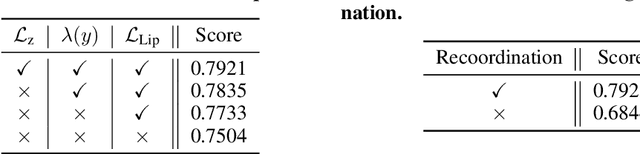
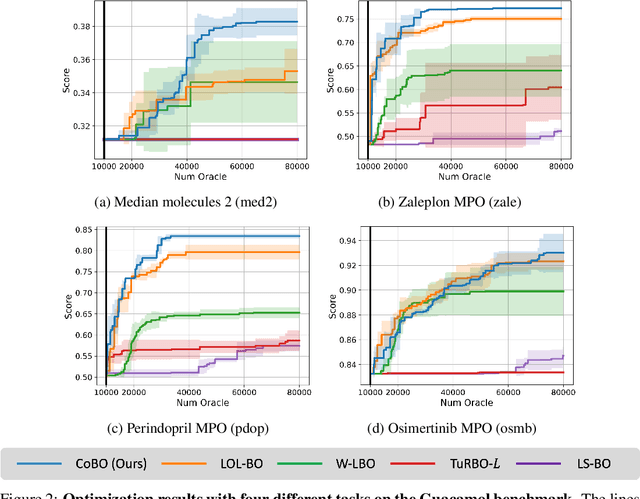
Bayesian optimization is a powerful method for optimizing black-box functions with limited function evaluations. Recent works have shown that optimization in a latent space through deep generative models such as variational autoencoders leads to effective and efficient Bayesian optimization for structured or discrete data. However, as the optimization does not take place in the input space, it leads to an inherent gap that results in potentially suboptimal solutions. To alleviate the discrepancy, we propose Correlated latent space Bayesian Optimization (CoBO), which focuses on learning correlated latent spaces characterized by a strong correlation between the distances in the latent space and the distances within the objective function. Specifically, our method introduces Lipschitz regularization, loss weighting, and trust region recoordination to minimize the inherent gap around the promising areas. We demonstrate the effectiveness of our approach on several optimization tasks in discrete data, such as molecule design and arithmetic expression fitting, and achieve high performance within a small budget.
NuTrea: Neural Tree Search for Context-guided Multi-hop KGQA
Oct 24, 2023Multi-hop Knowledge Graph Question Answering (KGQA) is a task that involves retrieving nodes from a knowledge graph (KG) to answer natural language questions. Recent GNN-based approaches formulate this task as a KG path searching problem, where messages are sequentially propagated from the seed node towards the answer nodes. However, these messages are past-oriented, and they do not consider the full KG context. To make matters worse, KG nodes often represent proper noun entities and are sometimes encrypted, being uninformative in selecting between paths. To address these problems, we propose Neural Tree Search (NuTrea), a tree search-based GNN model that incorporates the broader KG context. Our model adopts a message-passing scheme that probes the unreached subtree regions to boost the past-oriented embeddings. In addition, we introduce the Relation Frequency-Inverse Entity Frequency (RF-IEF) node embedding that considers the global KG context to better characterize ambiguous KG nodes. The general effectiveness of our approach is demonstrated through experiments on three major multi-hop KGQA benchmark datasets, and our extensive analyses further validate its expressiveness and robustness. Overall, NuTrea provides a powerful means to query the KG with complex natural language questions. Code is available at https://github.com/mlvlab/NuTrea.
Open-vocabulary Video Question Answering: A New Benchmark for Evaluating the Generalizability of Video Question Answering Models
Aug 18, 2023Video Question Answering (VideoQA) is a challenging task that entails complex multi-modal reasoning. In contrast to multiple-choice VideoQA which aims to predict the answer given several options, the goal of open-ended VideoQA is to answer questions without restricting candidate answers. However, the majority of previous VideoQA models formulate open-ended VideoQA as a classification task to classify the video-question pairs into a fixed answer set, i.e., closed-vocabulary, which contains only frequent answers (e.g., top-1000 answers). This leads the model to be biased toward only frequent answers and fail to generalize on out-of-vocabulary answers. We hence propose a new benchmark, Open-vocabulary Video Question Answering (OVQA), to measure the generalizability of VideoQA models by considering rare and unseen answers. In addition, in order to improve the model's generalization power, we introduce a novel GNN-based soft verbalizer that enhances the prediction on rare and unseen answers by aggregating the information from their similar words. For evaluation, we introduce new baselines by modifying the existing (closed-vocabulary) open-ended VideoQA models and improve their performances by further taking into account rare and unseen answers. Our ablation studies and qualitative analyses demonstrate that our GNN-based soft verbalizer further improves the model performance, especially on rare and unseen answers. We hope that our benchmark OVQA can serve as a guide for evaluating the generalizability of VideoQA models and inspire future research. Code is available at https://github.com/mlvlab/OVQA.