 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Makes LLM Agents Introverted: How Mandatory Thinking Can Backfire in User-Engaged Agents
Feb 08, 2026Eliciting reasoning has emerged as a powerful technique for improving the performance of large language models (LLMs) on complex tasks by inducing thinking. However, their effectiveness in realistic user-engaged agent scenarios remains unclear. In this paper, we conduct a comprehensive study on the effect of explicit thinking in user-engaged LLM agents. Our experiments span across seven models, three benchmarks, and two thinking instantiations, and we evaluate them through both a quantitative response taxonomy analysis and qualitative failure propagation case studies. Contrary to expectations, we find that mandatory thinking often backfires on agents in user-engaged settings, causing anomalous performance degradation across various LLMs. Our key finding reveals that thinking makes agents more ``introverted'' by shortening responses and reducing information disclosure to users, which weakens agent-user information exchange and leads to downstream task failures. Furthermore, we demonstrate that explicitly prompting for information disclosure reliably improves performance across diverse model families, suggesting that proactive transparency is a vital lever for agent optimization. Overall, our study suggests that information transparency awareness is a crucial yet underexplored perspective for the future design of reasoning agents in real-world scenarios. Our code is available at https://github.com/deeplearning-wisc/Thinking-Agent.
ModeX: Evaluator-Free Best-of-N Selection for Open-Ended Generation
Jan 05, 2026Selecting a single high-quality output from multiple stochastic generations remains a fundamental challenge for large language models (LLMs), particularly in open-ended tasks where no canonical answer exists. While Best-of-N and self-consistency methods show that aggregating multiple generations can improve performance, existing approaches typically rely on external evaluators, reward models, or exact string-match voting, limiting their applicability and efficiency. We propose Mode Extraction (ModeX), an evaluator-free Best-of-N selection framework that generalizes majority voting to open-ended text generation by identifying the modal output representing the dominant semantic consensus among generated texts. ModeX constructs a similarity graph over candidate generations and recursively applies spectral clustering to select a representative centroid, without requiring additional inference or auxiliary models. We further instantiate this selection principle as ModeX-Lite, an improved version of ModeX with early pruning for efficiency. Across open-ended tasks -- including text summarization, code generation, and mathematical reasoning -- our approaches consistently outperform standard single- and multi-path baselines, providing a computationally efficient solution for robust open-ended text generation. Code is released in https://github.com/deeplearning-wisc/ModeX.
Detecting Distillation Data from Reasoning Models
Oct 06, 2025Reasoning distillation has emerged as an efficient and powerful paradigm for enhancing the reasoning capabilities of large language models. However, reasoning distillation may inadvertently cause benchmark contamination, where evaluation data included in distillation datasets can inflate performance metrics of distilled models. In this work, we formally define the task of distillation data detection, which is uniquely challenging due to the partial availability of distillation data. Then, we propose a novel and effective method Token Probability Deviation (TBD), which leverages the probability patterns of the generated output tokens. Our method is motivated by the analysis that distilled models tend to generate near-deterministic tokens for seen questions, while producing more low-probability tokens for unseen questions. Our key idea behind TBD is to quantify how far the generated tokens' probabilities deviate from a high reference probability. In effect, our method achieves competitive detection performance by producing lower scores for seen questions than for unseen questions. Extensive experiments demonstrate the effectiveness of our method, achieving an AUC of 0.918 and a TPR@1% FPR of 0.470 on the S1 dataset.
Debate or Vote: Which Yields Better Decisions in Multi-Agent Large Language Models?
Aug 24, 2025Multi-Agent Debate~(MAD) has emerged as a promising paradigm for improving the performance of large language models through collaborative reasoning. Despite recent advances, the key factors driving MAD's effectiveness remain unclear. In this work, we disentangle MAD into two key components--Majority Voting and inter-agent Debate--and assess their respective contributions. Through extensive experiments across seven NLP benchmarks, we find that Majority Voting alone accounts for most of the performance gains typically attributed to MAD. To explain this, we propose a theoretical framework that models debate as a stochastic process. We prove that it induces a martingale over agents' belief trajectories, implying that debate alone does not improve expected correctness. Guided by these insights, we demonstrate that targeted interventions, by biasing the belief update toward correction, can meaningfully enhance debate effectiveness. Overall, our findings suggest that while MAD has potential, simple ensembling methods remain strong and more reliable alternatives in many practical settings. Code is released in https://github.com/deeplearning-wisc/debate-or-vote.
Safety-Aware Fine-Tuning of Large Language Models
Oct 13, 2024
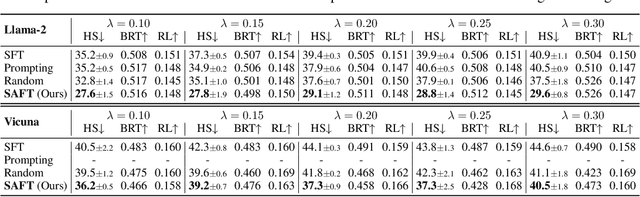

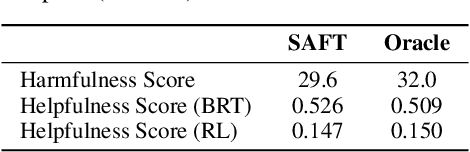
Fine-tuning Large Language Models (LLMs) has emerged as a common practice for tailoring models to individual needs and preferences. The choice of datasets for fine-tuning can be diverse, introducing safety concerns regarding the potential inclusion of harmful data samples. Manually filtering or avoiding such samples, however, can be labor-intensive and subjective. To address these difficulties, we propose a novel Safety-Aware Fine-Tuning (SAFT) framework designed to automatically detect and remove potentially harmful data, by leveraging a scoring function that exploits the subspace information of harmful and benign samples. Experimental results demonstrate the efficacy of SAFT across different LLMs and varying contamination rates, achieving reductions in harmfulness of up to 27.8%. Going beyond, we delve into the mechanism of our approach and validate its versatility in addressing practical challenges in real-world scenarios.
Mitigating Selection Bias with Node Pruning and Auxiliary Options
Sep 27, 2024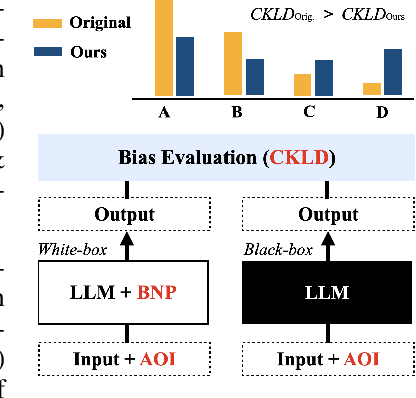
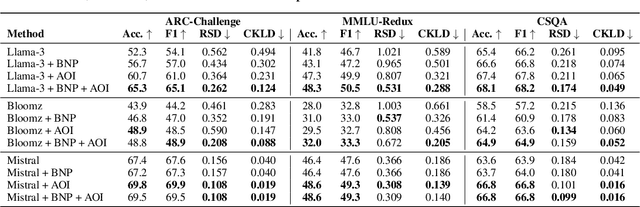
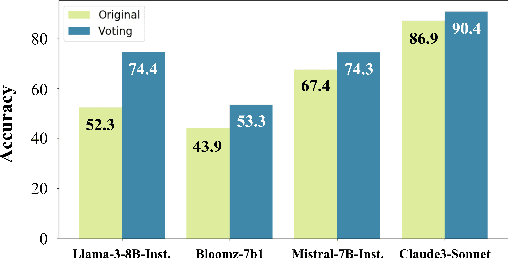
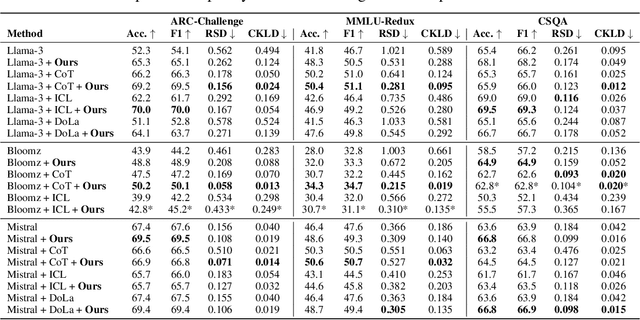
Large language models (LLMs) often show unwarranted preference for certain choice options when responding to multiple-choice questions, posing significant reliability concerns in LLM-automated systems. To mitigate this selection bias problem, previous solutions utilized debiasing methods to adjust the model's input and/or output. Our work, in contrast, investigates the model's internal representation of the selection bias. Specifically, we introduce a novel debiasing approach, Bias Node Pruning (BNP), which eliminates the linear layer parameters that contribute to the bias. Furthermore, we present Auxiliary Option Injection (AOI), a simple yet effective input modification technique for debiasing, which is compatible even with black-box LLMs. To provide a more systematic evaluation of selection bias, we review existing metrics and introduce Choice Kullback-Leibler Divergence (CKLD), which addresses the insensitivity of the commonly used metrics to label imbalance. Experiments show that our methods are robust and adaptable across various datasets when applied to three LLMs.
PICLe: Eliciting Diverse Behaviors from Large Language Models with Persona In-Context Learning
May 14, 2024Large Language Models (LLMs) are trained on massive text corpora, which are encoded with diverse personality traits. This triggers an interesting goal of eliciting a desired personality trait from the LLM, and probing its behavioral preferences. Accordingly, we formalize the persona elicitation task, aiming to customize LLM behaviors to align with a target persona. We present Persona In-Context Learning (PICLe), a novel persona elicitation framework grounded in Bayesian inference. At the core, PICLe introduces a new ICL example selection criterion based on likelihood ratio, which is designed to optimally guide the model in eliciting a specific target persona. We demonstrate the effectiveness of PICLe through extensive comparisons against baseline methods across three contemporary LLMs. Code is available at https://github.com/deeplearning-wisc/picle.
Beyond Helpfulness and Harmlessness: Eliciting Diverse Behaviors from Large Language Models with Persona In-Context Learning
May 03, 2024Large Language Models (LLMs) are trained on massive text corpora, which are encoded with diverse personality traits. This triggers an interesting goal of eliciting a desired personality trait from the LLM, and probing its behavioral preferences. Accordingly, we formalize the persona elicitation task, aiming to customize LLM behaviors to align with a target persona. We present Persona In-Context Learning (PICLe), a novel persona elicitation framework grounded in Bayesian inference. At the core, PICLe introduces a new ICL example selection criterion based on likelihood ratio, which is designed to optimally guide the model in eliciting a specific target persona. We demonstrate the effectiveness of PICLe through extensive comparisons against baseline methods across three contemporary LLMs. Code is available at https://github.com/deeplearning-wisc/picle.
NuTrea: Neural Tree Search for Context-guided Multi-hop KGQA
Oct 24, 2023Multi-hop Knowledge Graph Question Answering (KGQA) is a task that involves retrieving nodes from a knowledge graph (KG) to answer natural language questions. Recent GNN-based approaches formulate this task as a KG path searching problem, where messages are sequentially propagated from the seed node towards the answer nodes. However, these messages are past-oriented, and they do not consider the full KG context. To make matters worse, KG nodes often represent proper noun entities and are sometimes encrypted, being uninformative in selecting between paths. To address these problems, we propose Neural Tree Search (NuTrea), a tree search-based GNN model that incorporates the broader KG context. Our model adopts a message-passing scheme that probes the unreached subtree regions to boost the past-oriented embeddings. In addition, we introduce the Relation Frequency-Inverse Entity Frequency (RF-IEF) node embedding that considers the global KG context to better characterize ambiguous KG nodes. The general effectiveness of our approach is demonstrated through experiments on three major multi-hop KGQA benchmark datasets, and our extensive analyses further validate its expressiveness and robustness. Overall, NuTrea provides a powerful means to query the KG with complex natural language questions. Code is available at https://github.com/mlvlab/NuTrea.
MELTR: Meta Loss Transformer for Learning to Fine-tune Video Foundation Models
Mar 23, 2023Foundation models have shown outstanding performance and generalization capabilities across domains. Since most studies on foundation models mainly focus on the pretraining phase, a naive strategy to minimize a single task-specific loss is adopted for fine-tuning. However, such fine-tuning methods do not fully leverage other losses that are potentially beneficial for the target task. Therefore, we propose MEta Loss TRansformer (MELTR), a plug-in module that automatically and non-linearly combines various loss functions to aid learning the target task via auxiliary learning. We formulate the auxiliary learning as a bi-level optimization problem and present an efficient optimization algorithm based on Approximate Implicit Differentiation (AID). For evaluation, we apply our framework to various video foundation models (UniVL, Violet and All-in-one), and show significant performance gain on all four downstream tasks: text-to-video retrieval, video question answering, video captioning, and multi-modal sentiment analysis. Our qualitative analyses demonstrate that MELTR adequately `transforms' individual loss functions and `melts' them into an effective unified loss. Code is available at https://github.com/mlvlab/MELTR.