 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Aware Fine-Tuning of Large Language Models
Paper and Code
Oct 13, 2024
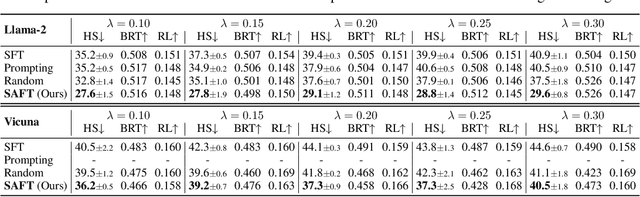

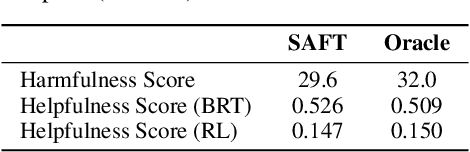
Fine-tuning Large Language Models (LLMs) has emerged as a common practice for tailoring models to individual needs and preferences. The choice of datasets for fine-tuning can be diverse, introducing safety concerns regarding the potential inclusion of harmful data samples. Manually filtering or avoiding such samples, however, can be labor-intensive and subjective. To address these difficulties, we propose a novel Safety-Aware Fine-Tuning (SAFT) framework designed to automatically detect and remove potentially harmful data, by leveraging a scoring function that exploits the subspace information of harmful and benign samples. Experimental results demonstrate the efficacy of SAFT across different LLMs and varying contamination rates, achieving reductions in harmfulness of up to 27.8%. Going beyond, we delve into the mechanism of our approach and validate its versatility in addressing practical challenges in real-world scenarios.