 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientViM: Efficient Vision Mamba with Hidden State Mixer based State Space Duality
Nov 22, 2024



For the deployment of neural networks in resource-constrained environments, prior works have built lightweight architectures with convolution and attention for capturing local and global dependencies, respectively. Recently, the state space model has emerged as an effective global token interaction with its favorable linear computational cost in the number of tokens. Yet, efficient vision backbones built with SSM have been explored less. In this paper, we introduce Efficient Vision Mamba (EfficientViM), a novel architecture built on hidden state mixer-based state space duality (HSM-SSD) that efficiently captures global dependencies with further reduced computational cost. In the HSM-SSD layer, we redesign the previous SSD layer to enable the channel mixing operation within hidden states. Additionally, we propose multi-stage hidden state fusion to further reinforce the representation power of hidden states, and provide the design alleviating the bottleneck caused by the memory-bound operations. As a result, the EfficientViM family achieves a new state-of-the-art speed-accuracy trade-off on ImageNet-1k, offering up to a 0.7% performance improvement over the second-best model SHViT with faster speed. Further, we observe significant improvements in throughput and accuracy compared to prior works, when scaling images or employing distillation training. Code is available at https://github.com/mlvlab/EfficientViM.
Multi-criteria Token Fusion with One-step-ahead Attention for Efficient Vision Transformers
Apr 01, 2024Vision Transformer (ViT) has emerged as a prominent backbone for computer vision. For more efficient ViTs, recent works lessen the quadratic cost of the self-attention layer by pruning or fusing the redundant tokens. However, these works faced the speed-accuracy trade-off caused by the loss of information. Here, we argue that token fusion needs to consider diverse relations between tokens to minimize information loss. In this paper, we propose a Multi-criteria Token Fusion (MCTF), that gradually fuses the tokens based on multi-criteria (e.g., similarity, informativeness, and size of fused tokens). Further, we utilize the one-step-ahead attention, which is the improved approach to capture the informativeness of the tokens. By training the model equipped with MCTF using a token reduction consistency, we achieve the best speed-accuracy trade-off in the image classification (ImageNet1K). Experimental results prove that MCTF consistently surpasses the previous reduction methods with and without training. Specifically, DeiT-T and DeiT-S with MCTF reduce FLOPs by about 44% while improving the performance (+0.5%, and +0.3%) over the base model, respectively. We also demonstrate the applicability of MCTF in various Vision Transformers (e.g., T2T-ViT, LV-ViT), achieving at least 31% speedup without performance degradation. Code is available at https://github.com/mlvlab/MCTF.
vid-TLDR: Training Free Token merging for Light-weight Video Transformer
Mar 30, 2024



Video Transformers have become the prevalent solution for various video downstream tasks with superior expressive power and flexibility. However, these video transformers suffer from heavy computational costs induced by the massive number of tokens across the entire video frames, which has been the major barrier to training the model. Further, the patches irrelevant to the main contents, e.g., backgrounds, degrade the generalization performance of models. To tackle these issues, we propose training free token merging for lightweight video Transformer (vid-TLDR) that aims to enhance the efficiency of video Transformers by merging the background tokens without additional training. For vid-TLDR, we introduce a novel approach to capture the salient regions in videos only with the attention map. Further, we introduce the saliency-aware token merging strategy by dropping the background tokens and sharpening the object scores. Our experiments show that vid-TLDR significantly mitigates the computational complexity of video Transformers while achieving competitive performance compared to the base model without vid-TLDR. Code is available at https://github.com/mlvlab/vid-TLDR.
Concept Bottleneck with Visual Concept Filtering for Explainable Medical Image Classification
Aug 23, 2023



Interpretability is a crucial factor in building reliable models for various medical applications. Concept Bottleneck Models (CBMs) enable interpretable image classification by utilizing human-understandable concepts as intermediate targets. Unlike conventional methods that require extensive human labor to construct the concept set, recent works leveraging Large Language Models (LLMs) for generating concepts made automatic concept generation possible. However, those methods do not consider whether a concept is visually relevant or not, which is an important factor in computing meaningful concept scores. Therefore, we propose a visual activation score that measures whether the concept contains visual cues or not, which can be easily computed with unlabeled image data. Computed visual activation scores are then used to filter out the less visible concepts, thus resulting in a final concept set with visually meaningful concepts. Our experimental results show that adopting the proposed visual activation score for concept filtering consistently boosts performance compared to the baseline. Moreover, qualitative analyses also validate that visually relevant concepts are successfully selected with the visual activation score.
MELTR: Meta Loss Transformer for Learning to Fine-tune Video Foundation Models
Mar 23, 2023Foundation models have shown outstanding performance and generalization capabilities across domains. Since most studies on foundation models mainly focus on the pretraining phase, a naive strategy to minimize a single task-specific loss is adopted for fine-tuning. However, such fine-tuning methods do not fully leverage other losses that are potentially beneficial for the target task. Therefore, we propose MEta Loss TRansformer (MELTR), a plug-in module that automatically and non-linearly combines various loss functions to aid learning the target task via auxiliary learning. We formulate the auxiliary learning as a bi-level optimization problem and present an efficient optimization algorithm based on Approximate Implicit Differentiation (AID). For evaluation, we apply our framework to various video foundation models (UniVL, Violet and All-in-one), and show significant performance gain on all four downstream tasks: text-to-video retrieval, video question answering, video captioning, and multi-modal sentiment analysis. Our qualitative analyses demonstrate that MELTR adequately `transforms' individual loss functions and `melts' them into an effective unified loss. Code is available at https://github.com/mlvlab/MELTR.
TokenMixup: Efficient Attention-guided Token-level Data Augmentation for Transformers
Oct 14, 2022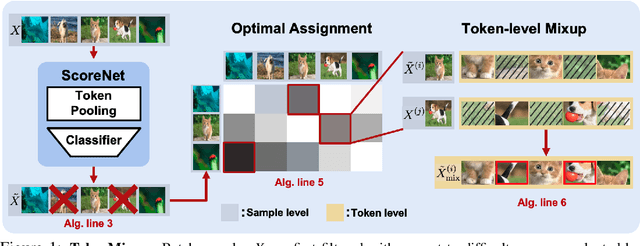


Mixup is a commonly adopted data augmentation technique for image classification. Recent advances in mixup methods primarily focus on mixing based on saliency. However, many saliency detectors require intense computation and are especially burdensome for parameter-heavy transformer models. To this end, we propose TokenMixup, an efficient attention-guided token-level data augmentation method that aims to maximize the saliency of a mixed set of tokens. TokenMixup provides x15 faster saliency-aware data augmentation compared to gradient-based methods. Moreover, we introduce a variant of TokenMixup which mixes tokens within a single instance, thereby enabling multi-scale feature augmentation. Experiments show that our methods significantly improve the baseline models' performance on CIFAR and ImageNet-1K, while being more efficient than previous methods. We also reach state-of-the-art performance on CIFAR-100 among from-scratch transformer models. Code is available at https://github.com/mlvlab/TokenMixup.
Video-Text Representation Learning via Differentiable Weak Temporal Alignment
Mar 31, 2022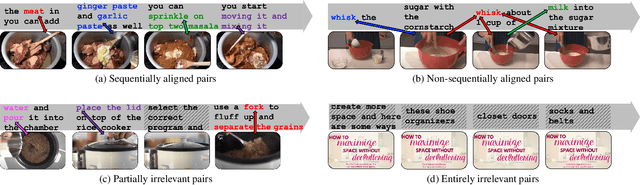
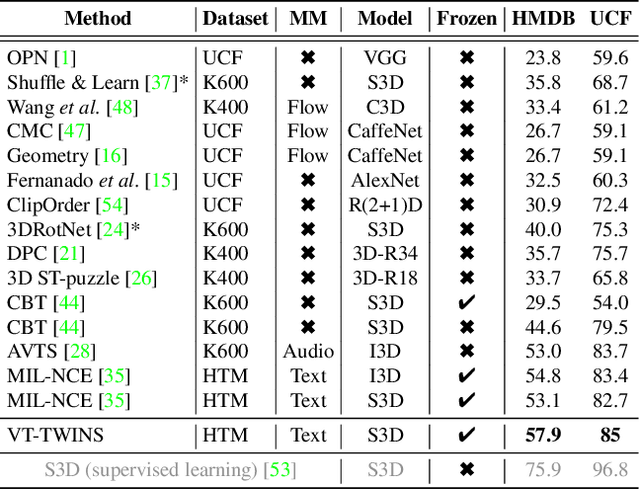
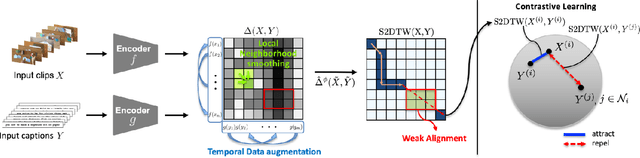
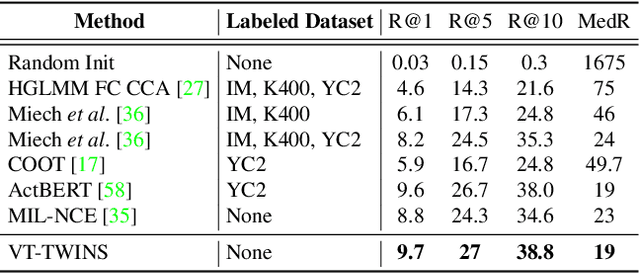
Learning generic joint representations for video and text by a supervised method requires a prohibitively substantial amount of manually annotated video datasets. As a practical alternative, a large-scale but uncurated and narrated video dataset, HowTo100M, has recently been introduced. But it is still challenging to learn joint embeddings of video and text in a self-supervised manner, due to its ambiguity and non-sequential alignment. In this paper, we propose a novel multi-modal self-supervised framework Video-Text Temporally Weak Alignment-based Contrastive Learning (VT-TWINS) to capture significant information from noisy and weakly correlated data using a variant of Dynamic Time Warping (DTW). We observe that the standard DTW inherently cannot handle weakly correlated data and only considers the globally optimal alignment path. To address these problems, we develop a differentiable DTW which also reflects local information with weak temporal alignment. Moreover, our proposed model applies a contrastive learning scheme to learn feature representations on weakly correlated data. Our extensive experiments demonstrate that VT-TWINS attains significant improvements in multi-modal representation learning and outperforms various challenging downstream tasks. Code is available at https://github.com/mlvlab/VT-TWINS.