 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-GRPO: Optimizing Mixture-of-Experts via Reinforcement Learning in Vision-Language Models
Mar 26, 2026Mixture-of-Experts (MoE) has emerged as an effective approach to reduce the computational overhead of Transformer architectures by sparsely activating a subset of parameters for each token while preserving high model capacity. This paradigm has recently been extended to Vision-Language Models (VLMs), enabling scalable multi-modal understanding with reduced computational cost. However, the widely adopted deterministic top-K routing mechanism may overlook more optimal expert combinations and lead to expert overfitting. To address this limitation and improve the diversity of expert selection, we propose MoE-GRPO, a reinforcement learning (RL)-based framework for optimizing expert routing in MoE-based VLMs. Specifically, we formulate expert selection as a sequential decision-making problem and optimize it using Group Relative Policy Optimization (GRPO), allowing the model to learn adaptive expert routing policies through exploration and reward-based feedback. Furthermore, we introduce a modality-aware router guidance that enhances training stability and efficiency by discouraging the router from exploring experts that are infrequently activated for a given modality. Extensive experiments on multi-modal image and video benchmarks show that MoE-GRPO consistently outperforms standard top-K routing and its variants by promoting more diverse expert selection, thereby mitigating expert overfitting and enabling a task-level expert specialization.
ST-VLM: Kinematic Instruction Tuning for Spatio-Temporal Reasoning in Vision-Language Models
Mar 26, 2025



Spatio-temporal reasoning is essential in understanding real-world environments in various fields, eg, autonomous driving and sports analytics. Recent advances have improved the spatial reasoning ability of Vision-Language Models (VLMs) by introducing large-scale data, but these models still struggle to analyze kinematic elements like traveled distance and speed of moving objects. To bridge this gap, we construct a spatio-temporal reasoning dataset and benchmark involving kinematic instruction tuning, referred to as STKit and STKit-Bench. They consist of real-world videos with 3D annotations, detailing object motion dynamics: traveled distance, speed, movement direction, inter-object distance comparisons, and relative movement direction. To further scale such data construction to videos without 3D labels, we propose an automatic pipeline to generate pseudo-labels using 4D reconstruction in real-world scale. With our kinematic instruction tuning data for spatio-temporal reasoning, we present ST-VLM, a VLM enhanced for spatio-temporal reasoning, which exhibits outstanding performance on STKit-Bench. Furthermore, we show that ST-VLM generalizes robustly across diverse domains and tasks, outperforming baselines on other spatio-temporal benchmarks (eg, ActivityNet, TVQA+). Finally, by integrating learned spatio-temporal reasoning with existing abilities, ST-VLM enables complex multi-step reasoning. Project page: https://ikodoh.github.io/ST-VLM.
LLaMo: Large Language Model-based Molecular Graph Assistant
Oct 31, 2024Large Language Models (LLMs) have demonstrated remarkable generalization and instruction-following capabilities with instruction tuning. The advancements in LLMs and instruction tuning have led to the development of Large Vision-Language Models (LVLMs). However, the competency of the LLMs and instruction tuning have been less explored in the molecular domain. Thus, we propose LLaMo: Large Language Model-based Molecular graph assistant, which is an end-to-end trained large molecular graph-language model. To bridge the discrepancy between the language and graph modalities, we present the multi-level graph projector that transforms graph representations into graph tokens by abstracting the output representations of each GNN layer and motif representations with the cross-attention mechanism. We also introduce machine-generated molecular graph instruction data to instruction-tune the large molecular graph-language model for general-purpose molecule and language understanding. Our extensive experiments demonstrate that LLaMo shows the best performance on diverse tasks, such as molecular description generation, property prediction, and IUPAC name prediction. The code of LLaMo is available at https://github.com/mlvlab/LLaMo.
Large Language Models are Temporal and Causal Reasoners for Video Question Answering
Nov 06, 2023Large Language Models (LLMs) have shown remarkable performances on a wide range of natural language understanding and generation tasks. We observe that the LLMs provide effective priors in exploiting $\textit{linguistic shortcuts}$ for temporal and causal reasoning in Video Question Answering (VideoQA). However, such priors often cause suboptimal results on VideoQA by leading the model to over-rely on questions, $\textit{i.e.}$, $\textit{linguistic bias}$, while ignoring visual content. This is also known as `ungrounded guesses' or `hallucinations'. To address this problem while leveraging LLMs' prior on VideoQA, we propose a novel framework, Flipped-VQA, encouraging the model to predict all the combinations of $\langle$V, Q, A$\rangle$ triplet by flipping the source pair and the target label to understand their complex relationships, $\textit{i.e.}$, predict A, Q, and V given a VQ, VA, and QA pairs, respectively. In this paper, we develop LLaMA-VQA by applying Flipped-VQA to LLaMA, and it outperforms both LLMs-based and non-LLMs-based models on five challenging VideoQA benchmarks. Furthermore, our Flipped-VQA is a general framework that is applicable to various LLMs (OPT and GPT-J) and consistently improves their performances. We empirically demonstrate that Flipped-VQA not only enhances the exploitation of linguistic shortcuts but also mitigates the linguistic bias, which causes incorrect answers over-relying on the question. Code is available at https://github.com/mlvlab/Flipped-VQA.
Open-vocabulary Video Question Answering: A New Benchmark for Evaluating the Generalizability of Video Question Answering Models
Aug 18, 2023Video Question Answering (VideoQA) is a challenging task that entails complex multi-modal reasoning. In contrast to multiple-choice VideoQA which aims to predict the answer given several options, the goal of open-ended VideoQA is to answer questions without restricting candidate answers. However, the majority of previous VideoQA models formulate open-ended VideoQA as a classification task to classify the video-question pairs into a fixed answer set, i.e., closed-vocabulary, which contains only frequent answers (e.g., top-1000 answers). This leads the model to be biased toward only frequent answers and fail to generalize on out-of-vocabulary answers. We hence propose a new benchmark, Open-vocabulary Video Question Answering (OVQA), to measure the generalizability of VideoQA models by considering rare and unseen answers. In addition, in order to improve the model's generalization power, we introduce a novel GNN-based soft verbalizer that enhances the prediction on rare and unseen answers by aggregating the information from their similar words. For evaluation, we introduce new baselines by modifying the existing (closed-vocabulary) open-ended VideoQA models and improve their performances by further taking into account rare and unseen answers. Our ablation studies and qualitative analyses demonstrate that our GNN-based soft verbalizer further improves the model performance, especially on rare and unseen answers. We hope that our benchmark OVQA can serve as a guide for evaluating the generalizability of VideoQA models and inspire future research. Code is available at https://github.com/mlvlab/OVQA.
MELTR: Meta Loss Transformer for Learning to Fine-tune Video Foundation Models
Mar 23, 2023Foundation models have shown outstanding performance and generalization capabilities across domains. Since most studies on foundation models mainly focus on the pretraining phase, a naive strategy to minimize a single task-specific loss is adopted for fine-tuning. However, such fine-tuning methods do not fully leverage other losses that are potentially beneficial for the target task. Therefore, we propose MEta Loss TRansformer (MELTR), a plug-in module that automatically and non-linearly combines various loss functions to aid learning the target task via auxiliary learning. We formulate the auxiliary learning as a bi-level optimization problem and present an efficient optimization algorithm based on Approximate Implicit Differentiation (AID). For evaluation, we apply our framework to various video foundation models (UniVL, Violet and All-in-one), and show significant performance gain on all four downstream tasks: text-to-video retrieval, video question answering, video captioning, and multi-modal sentiment analysis. Our qualitative analyses demonstrate that MELTR adequately `transforms' individual loss functions and `melts' them into an effective unified loss. Code is available at https://github.com/mlvlab/MELTR.
Video-Text Representation Learning via Differentiable Weak Temporal Alignment
Mar 31, 2022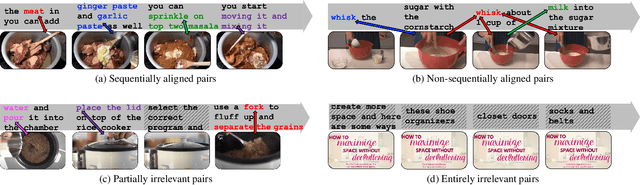
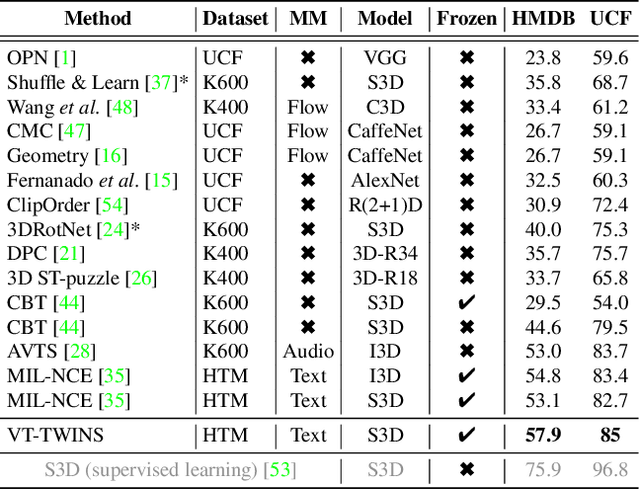
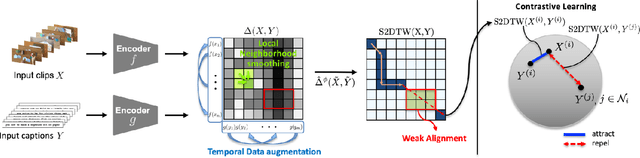
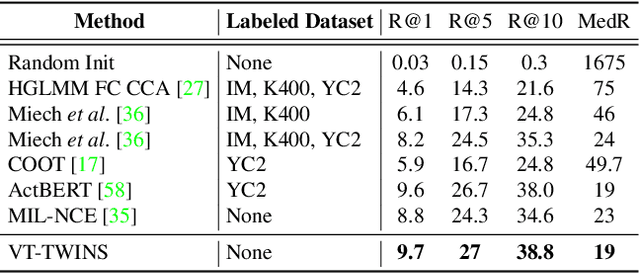
Learning generic joint representations for video and text by a supervised method requires a prohibitively substantial amount of manually annotated video datasets. As a practical alternative, a large-scale but uncurated and narrated video dataset, HowTo100M, has recently been introduced. But it is still challenging to learn joint embeddings of video and text in a self-supervised manner, due to its ambiguity and non-sequential alignment. In this paper, we propose a novel multi-modal self-supervised framework Video-Text Temporally Weak Alignment-based Contrastive Learning (VT-TWINS) to capture significant information from noisy and weakly correlated data using a variant of Dynamic Time Warping (DTW). We observe that the standard DTW inherently cannot handle weakly correlated data and only considers the globally optimal alignment path. To address these problems, we develop a differentiable DTW which also reflects local information with weak temporal alignment. Moreover, our proposed model applies a contrastive learning scheme to learn feature representations on weakly correlated data. Our extensive experiments demonstrate that VT-TWINS attains significant improvements in multi-modal representation learning and outperforms various challenging downstream tasks. Code is available at https://github.com/mlvlab/VT-TWINS.