 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoneybee: Locality-enhanced Projector for Multimodal LLM
Dec 11, 2023In Multimodal Large Language Models (MLLMs), a visual projector plays a crucial role in bridging pre-trained vision encoders with LLMs, enabling profound visual understanding while harnessing the LLMs' robust capabilities. Despite the importance of the visual projector, it has been relatively less explored. In this study, we first identify two essential projector properties: (i) flexibility in managing the number of visual tokens, crucial for MLLMs' overall efficiency, and (ii) preservation of local context from visual features, vital for spatial understanding. Based on these findings, we propose a novel projector design that is both flexible and locality-enhanced, effectively satisfying the two desirable properties. Additionally, we present comprehensive strategies to effectively utilize multiple and multifaceted instruction datasets. Through extensive experiments, we examine the impact of individual design choices. Finally, our proposed MLLM, Honeybee, remarkably outperforms previous state-of-the-art methods across various benchmarks, including MME, MMBench, SEED-Bench, and LLaVA-Bench, achieving significantly higher efficiency. Code and models are available at https://github.com/kakaobrain/honeybee.
Large Language Models are Temporal and Causal Reasoners for Video Question Answering
Nov 06, 2023Large Language Models (LLMs) have shown remarkable performances on a wide range of natural language understanding and generation tasks. We observe that the LLMs provide effective priors in exploiting $\textit{linguistic shortcuts}$ for temporal and causal reasoning in Video Question Answering (VideoQA). However, such priors often cause suboptimal results on VideoQA by leading the model to over-rely on questions, $\textit{i.e.}$, $\textit{linguistic bias}$, while ignoring visual content. This is also known as `ungrounded guesses' or `hallucinations'. To address this problem while leveraging LLMs' prior on VideoQA, we propose a novel framework, Flipped-VQA, encouraging the model to predict all the combinations of $\langle$V, Q, A$\rangle$ triplet by flipping the source pair and the target label to understand their complex relationships, $\textit{i.e.}$, predict A, Q, and V given a VQ, VA, and QA pairs, respectively. In this paper, we develop LLaMA-VQA by applying Flipped-VQA to LLaMA, and it outperforms both LLMs-based and non-LLMs-based models on five challenging VideoQA benchmarks. Furthermore, our Flipped-VQA is a general framework that is applicable to various LLMs (OPT and GPT-J) and consistently improves their performances. We empirically demonstrate that Flipped-VQA not only enhances the exploitation of linguistic shortcuts but also mitigates the linguistic bias, which causes incorrect answers over-relying on the question. Code is available at https://github.com/mlvlab/Flipped-VQA.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Open-Vocabulary Object Detection using Pseudo Caption Labels
Mar 23, 2023



Recent open-vocabulary detection methods aim to detect novel objects by distilling knowledge from vision-language models (VLMs) trained on a vast amount of image-text pairs. To improve the effectiveness of these methods, researchers have utilized datasets with a large vocabulary that contains a large number of object classes, under the assumption that such data will enable models to extract comprehensive knowledge on the relationships between various objects and better generalize to unseen object classes. In this study, we argue that more fine-grained labels are necessary to extract richer knowledge about novel objects, including object attributes and relationships, in addition to their names. To address this challenge, we propose a simple and effective method named Pseudo Caption Labeling (PCL), which utilizes an image captioning model to generate captions that describe object instances from diverse perspectives. The resulting pseudo caption labels offer dense samples for knowledge distillation. On the LVIS benchmark, our best model trained on the de-duplicated VisualGenome dataset achieves an AP of 34.5 and an APr of 30.6, comparable to the state-of-the-art performance. PCL's simplicity and flexibility are other notable features, as it is a straightforward pre-processing technique that can be used with any image captioning model without imposing any restrictions on model architecture or training process.
Noise-aware Learning from Web-crawled Image-Text Data for Image Captioning
Dec 27, 2022



Image captioning is one of the straightforward tasks that can take advantage of large-scale web-crawled data which provides rich knowledge about the visual world for a captioning model. However, since web-crawled data contains image-text pairs that are aligned at different levels, the inherent noises (e.g., misaligned pairs) make it difficult to learn a precise captioning model. While the filtering strategy can effectively remove noisy data, however, it leads to a decrease in learnable knowledge and sometimes brings about a new problem of data deficiency. To take the best of both worlds, we propose a noise-aware learning framework, which learns rich knowledge from the whole web-crawled data while being less affected by the noises. This is achieved by the proposed quality controllable model, which is learned using alignment levels of the image-text pairs as an additional control signal during training. The alignment-conditioned training allows the model to generate high-quality captions of well-aligned by simply setting the control signal to desired alignment level at inference time. Through in-depth analysis, we show that our controllable captioning model is effective in handling noise. In addition, with two tasks of zero-shot captioning and text-to-image retrieval using generated captions (i.e., self-retrieval), we also demonstrate our model can produce high-quality captions in terms of descriptiveness and distinctiveness. Code is available at \url{https://github.com/kakaobrain/noc}.
Dense but Efficient VideoQA for Intricate Compositional Reasoning
Oct 19, 2022
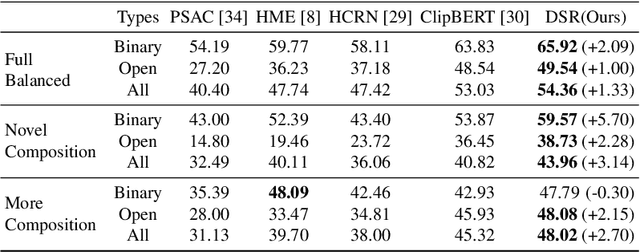
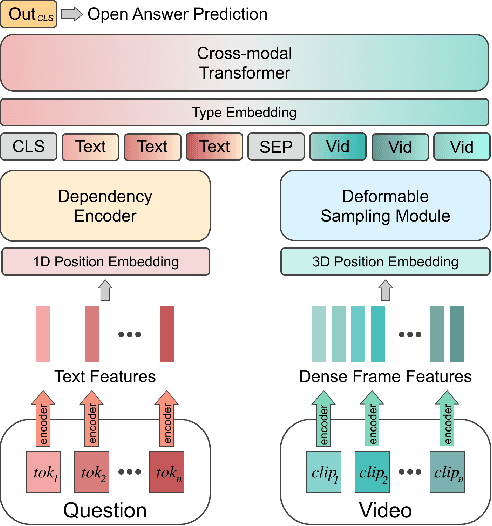
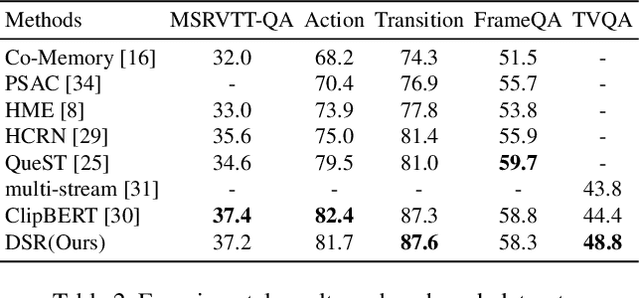
It is well known that most of the conventional video question answering (VideoQA) datasets consist of easy questions requiring simple reasoning processes. However, long videos inevitably contain complex and compositional semantic structures along with the spatio-temporal axis, which requires a model to understand the compositional structures inherent in the videos. In this paper, we suggest a new compositional VideoQA method based on transformer architecture with a deformable attention mechanism to address the complex VideoQA tasks. The deformable attentions are introduced to sample a subset of informative visual features from the dense visual feature map to cover a temporally long range of frames efficiently. Furthermore, the dependency structure within the complex question sentences is also combined with the language embeddings to readily understand the relations among question words. Extensive experiments and ablation studies show that the suggested dense but efficient model outperforms other baselines.